需求方|数据分析的 8 个状态
编辑导语:流量时代,数据尤其重要,数据分析是对数据进行分析使其产生相应的价值。因此正确的数据分析非常重要,它有助于品牌了解用户和市场。本篇文章中,作者分享了数据分析的八种状态,我们一起来看看吧。

文章插图
看了刘思喆老师写的「数据分析师的生存手记」,其中把数据分析的工作流程分成 8 个状态,我觉得很有启发。
下面谈一谈我对这 8 个状态的理解和思考,为了方便理解,我修改了原文中一些状态的名称。
一、新的需求数据分析工作流程的第 1 个状态,就是忠实地记录新的需求,纯粹地站在需求方的角度,不加任何评判地收集原始的需求。
这个状态借鉴了ORID 焦点讨论法的第 1 步,也就是真实地记录客观的事实。
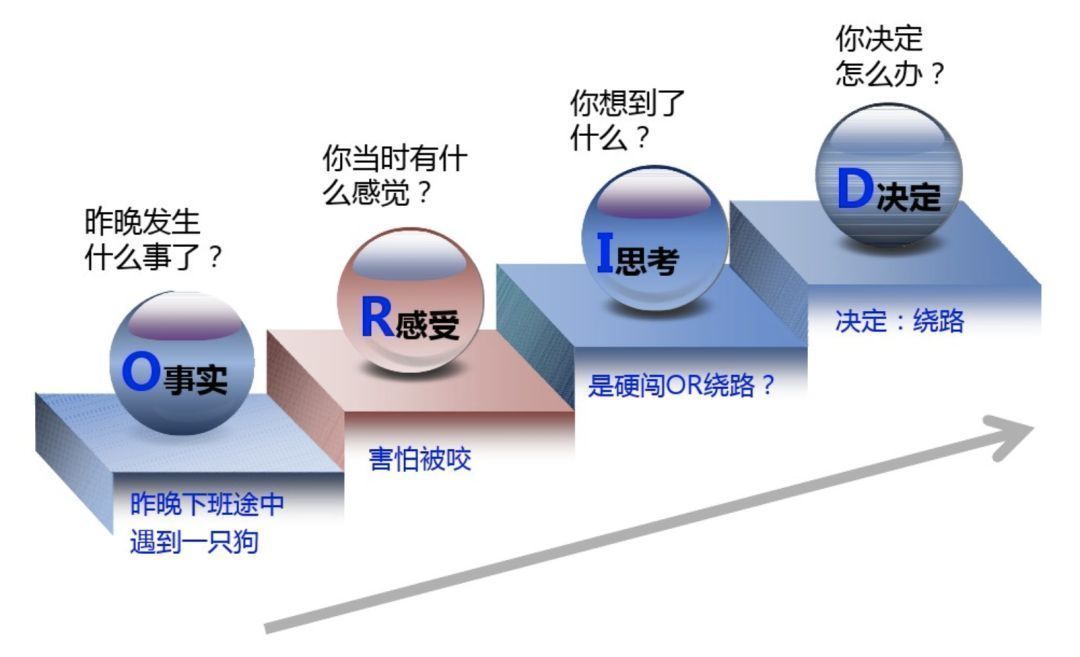
关于 ORID 焦点讨论法,我从网上查了一些相关资料,看到下面这个例子,感觉比较恰当。
假设昨天晚上在下班的路上,我遇到一条狗(O 事实),当时我很害怕(R 感受),心想应该怎么办(I 思考),为了避免被狗咬,我最终决定绕路走(D 决定)。
文章插图
二、需求确认【 需求方|数据分析的 8 个状态】需求确认是分析任务成败的关键,针对不同的情况,应该采取不同的对策。
1. 需求方无法清楚描述问题刘思喆老师说,这类需求方的专业技能不合格,会祸害上下游,「fire」掉就可以了,绝对不可以手软。
关于「fire」这个英文单词,有「开除」的意思,不过我理解刘思喆老师在这里表达的应该是「拒绝」。
对于一般的数据分析师而言,需求方可能就是自己的老板,恐怕没有「开除」的勇气。遇到这种情况,我个人建议加强沟通交流,主动多问一问具体情况,搞清楚需求方的真正意图。
2. 需求方将很多问题混杂在一起这种情况非常普遍,数据分析师需要应用 MECE 原则,帮助需求方梳理业务,变成相互独立、完全穷尽的问题,并了解其中的主要矛盾和次要矛盾。
3. 需求方无法和数据进行映射这种情况也相对比较普遍,一般企业是通过「角色前置」来缓解这个问题,比如设置「产品经理」的岗位角色。不过有的时候,前置的角色可能不合格,这就需要数据分析师在「数据确认」环节给予专业的建议。
4. 需求方提出了错误的数据需求想象一下,数据需求本身就不对,你作为数据分析师,居然漂亮地执行完成了……结果需求方不满意,又提了一遍,后面可能还有第三遍……最终需求方可能很不满意,数据分析师吃哑巴亏。
当出现这种情况时,建议数据分析师在执行之前,先进行合理的沟通,指出数据需求本身的不当之处。
5. 需求方无法预判可能的分析结果这种情况很正常,毕竟很难碰到非常完美的需求方。我认为此时数据分析师应该多一些包容和理解,多站在对方的角度看问题,自己先学会预判,然后再帮助对方学会预判,为对方排忧解难。
假如遇到需求方不仅掌握业务和数据之间的关系,而且懂得利用数据分析的结果,来指导下一步的行动,那么数据分析师应该好好珍惜。
三、 数据确认当需求确认清楚之后,接下来需要确认数据源,可能会遇到 3 个问题。
1. 期望的数据没有存储作为数据分析师,如果你能帮助改善这个问题,让企业的数据更加完备,那么你的影响力将会得到提升。
2. 数据分散在不同的位置在传统企业,这个问题非常普遍,可能还没有建立数据仓库。对于互联网企业,这个问题体现了数据仓库设计的不完备。
如果不是经常性的问题,临时解决即可。如果是经常性的问题,建议数据分析师主动了解底层的数据逻辑,编写自动化的代码,在可能的情况下,交付给数据仓库团队。
3. 数据源错误这个问题非常致命,如果数据源不对,后面的分析结果可能造成误导,让需求方做出错误决策,后果不堪设想。
所以,数据分析师提高数据敏感度也很重要,在做数据分析之前,一定要先确认一下,数据源是正确无误的吗?
四、需求实现在需求实现的过程中,数据分析师要管理好自己的分析代码。
以 Python 为例,尽量使用 Numpy、Pandas、Matplotlib 等比较成熟的包,用 Git 做好代码的版本控制,特别注意代码注释和提交信息的可读性和完整性,让数据处理的每个步骤都清晰易懂。
另外,配合使用 Jupyter Lab 之类的工具,能大大提升数据分析的工作效率。
- 加州大学|马斯克脑机接口公司被指虐猴,参加实验的23只猴子死了15只
- 互联网|传统企业里,产品经理的价值衡量难题
- 企业|裁员,降薪,大牛出走:AI大退却的始末缘由
- 界面设计中的分割方式
- 权限|CRM 05:基于RBAC理论的权限设计
- 小米科技|家电升级计划:幸福感+N,盘点近期入手的家电好物
- 机箱|内外设置精致双屏幕,二手金立w900体验,国产翻盖手机中的贵族
- 算法|千人千面的算法,走到了十字路口
- 熟人|年轻人都在玩的“啫喱”,没撑过3天?
- 千人千面的算法,走到了十字路口