新一代搜索引擎项目 ZeroSearch 设计探索( 五 )
最后 , 细心的读者可能早早就发现了 , 求交出来的文档是需要都送入 L1 打分的 , 但是只有 L1 得分 Top 的文档才能进入 L2 打分 , 整个任务模型里的求交-L1 打分-L2 打分的流水线处理应该无法实现才对 。 的确是的 , 求交结果进入 L1 打分是一个确定的行为 , 而 L1 打分结果是否进入 L2 打分是一个待定的行为 。 为了满足流水线的计算 , 我们需要将待定行为转为确定行为 。
1 文档预估
如果我们能够知道一个请求能求交得到多少篇文档 , 那么当求交文档数 < L1 结果限制数(TopK 里的 k 值) , 那么很明显 , 所有完成了 L1 打分的文档都可以直接进入 L2 打分 。
1.1 根据文档频率预估这是一种简单粗暴的方式 , 例如用户搜索[苹果手机],它的分词结果得[苹果 | 手机] , 两者的关系为求交 , 那么这个 query 的预估召回文档数就为:
min(Term(苹果)倒排链长度 , Term(手机)倒排链长度)如果考虑到苹果手机整体与 iphone 同义 , 那么其预估召回文档数就为:
max(Term(iphone)倒排链长度 , min(Term(苹果)倒排链长度 , Term(手机)倒排链长度))即根据各个 Term 的文档频率和其逻辑关系来进行简单的推导 。 很明显 , 实际求交文档数 , 一定会小于等于该推导值 。
1.2 缓存查表由于一定时间内的索引数据是相对稳定的 , 我们可以通过缓存检索 query 和求交数的映射关系 , 每个请求到达时进行一次查表来完成预估 。 可能有读者会质疑 , 那为什么不直接缓存求交结果呢?
其实这是两个维度的东西 , 它们本身也并不冲突 , 如果在引擎内对结果缓存会占用较多的内存 , 我们期望的做法是在更上层对分页后的结果进行缓存 , 因为可以明确的一点是首页的缓存命中率一定会显著高于后续的结果页 。 另外引擎内进行缓存的话还会影响系统的时效性 , 这一点并不合适 。
1.3 模型预估通过模型来对一个 query 的召回文档数进行预估 。 由于每个业务的数据量是相对稳定的 , 可以通过在线收集 query 和查 询语法树的特征以及倒排链相关的特征 , 离线训练 , 在线接入 , 来完成预估 。
2 预计算即选出一部分 L1 打分完成的文档 , 先进行 L2 打分计算 。 目前我们实现的方式有以下几种:
2.1 固定篇数模式取固定的 l1 结果数进行预计算,原则为先完成 l1 打分的文档将会被送入 , 这是因为由于 l0 得分的存在,通常我们认为越先被求交出来的文档,其质量越高
2.2 得分阈值模式l1 得分大于得分阈值的进行预计算
2.3 得分比例模式l1 得分大于 (已完成 l1 打分的文档的平均分 * rate) 的文档进行预计算 , 因此其实这是一种特殊的得分阈值模式 , 只是它的阈值在不断调整 。
由于我们目前只有一些较简单的离线业务接入了新引擎 , 上面几种方案的具体效果如何还没有得到一个可信的数据 。 另外后续也会考虑不断加入新的预计算方式 , 例如将固定篇数模式与得分阈值模式组合起来使用 。
事实上 , 预计算几乎肯定会有浪费计算量的情况出现 , 即本不能进入 L2 打分的文档却被执行了 L2 打分 。 其浪费率以及耗时降低的收益需要根据各个业务自己的需求而定 。
需要特别说明的是 , 新引擎在 L1 打分阶段完成之后(求交阶段已完成 , 且 L1 打分任务全部完成) , 依然会整体进入 L2 打分阶段 , 对 L1 结果集取 TopK , 然后分配 L2 打分任务 , 只是每个 L2 打分任务对分配到的文档进行打分时会先判断是否已经被预计算过了 , 如果是的话则直接跳过 。 因此预计算的存在并不会导致结果不稳定的问题出现 。
求交设计求交设计分为两块 , 一块是语法树求交设计 , 主要是查询语法树的设计和求交算法 。 另一块是查找算法设计 , 主要介绍倒排查找的做法 。
语法树求交设计对于求交而言 , 基本的理解其实就是取出几条倒排链 , 然后计算出倒排链中公共的文档 。 不过实际情况比这个要复杂很多 。 对于求交设计而言 , 第一步要考虑的是查询语法树的设计 , 我们从同义词开始 , 在新引擎的设计里 , 我们采用的 3 层结构语法树 。 假设 [苹果手机] 存在同义词 [iphone],那么对于 query [苹果手机回收] 的最终的检索语法树为下图所示: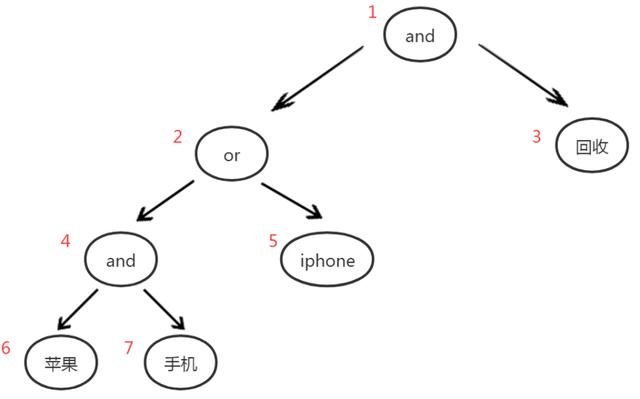 文章插图
文章插图
这里以宽度优先的方式给每个节点进行了编号 。 可以看到这是一颗 and-or-and 的语法树 , 可以支持多对多的同义词表达形式,例如这里的节点 2 下面的两个同义词词组 , 就是一个 2 对 1 的同义词组 。
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?