新一代搜索引擎项目 ZeroSearch 设计探索( 三 )
3 多个线程池的方式不论怎么去配置数量 , 都不太可能把所有线程都高效利用起来 , 必然会有计算资源不能充分利用的线程池存在 。
尽管存在这么多很容易预见的问题 , 我们还是先这样做了 , 一方面是目前开发人力非常少 , 在线检索这块的开发只有我一个人在兼职 , 需要弥补完善的东西还有很多 , 整体确实还比较粗糙 , 另一方面主要也是目前我们还没有建立一个用于质量标准评测的系统 , 因此一些优化类的工作优先级都排的比较低 。
关于有没有饿死情况的出现 , 我们的评判标准并不是针对个例的发现 , 而是通过统计p99,p995 , p999等指标来进行评判 。 因此严格意义上来说 , 也并不是真正的饿死 , 毕竟FIFO队列只要入队了迟早会被执行 , 只是等待时间长和短的问题 。 正如标题是对于引擎设计的探索 , 这里简单分享一下后续计划要尝试的几个线程模型的方向 , 当然下面所有的方向都是只使用一个线程池 。 1 继续维持 FIFO 的模式这个很好理解 , 也就是所有的 Task 都入同一个先进先出的队列 , 其实这个改动起来非常简单 , 只是质量标准评测系统还没搭起来 , 就暂时没去做对比测试了 。
【新一代搜索引擎项目 ZeroSearch 设计探索】2 逻辑越轻量 , 优先级越高同样很好理解 , 即创建一个特殊的优先级队列 , 对各类 Task 根据逻辑的繁重设定一个优先级 , 设想的情况是这样的 , 优先级从高到低为:
清理Task > L1Task > L2Task > 求交Task在 Push 任务时 , 优先级越高的直接插入到队首 , 但是同类 Task 之间依然保持先进先出的关系 。 最终是一个这样的队列: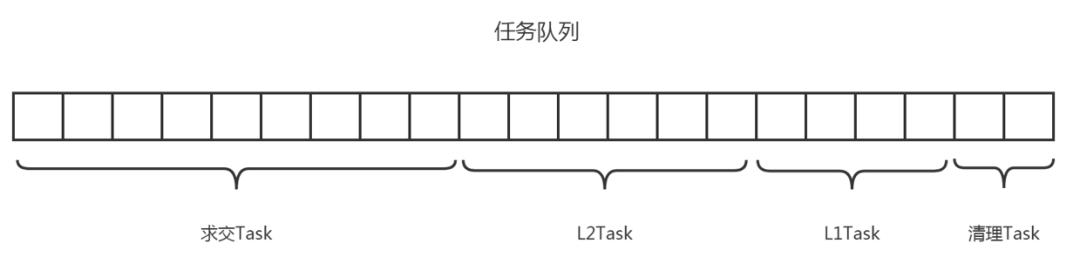 文章插图
文章插图
为什么要这样做呢?
可以有效解决由于求交任务的高消耗和集中入队导致其它任务饿死的问题 。 通俗一点理解 , 那就是只有当所有的打分任务都完成了才会去执行求交任务 。
从过程上看 , 似乎会有一个新的问题 , 即便系统有多个逻辑核 , 索引库之间的求交打分变成了线性的模式(串行) , 而非并发的模式?
但是从结果上进行分析 , 这种调度模式是否改变了处理请求时所需要的计算量?很明显 , 并没有 。 同样的 , 单位时间内机器的算力也并没有浪费 , 因为除非请求已经完成 , 否则一旦有空闲线程出现 , 那么必定会被分配给求交任务 。 那么至少从结果上来分析 , 这种模式应该是有效的 , 当然具体效果优劣 , 数据表现如何 , 还需实验验证 。
以逻辑越轻量 , 优先级越高的优先级队列管理任务似乎会引入一个新的问题 , 即求交任务可能被'饿死' ? 这一点很难评判 , 原因在于两点1 打分任务其实是由求交任务产生 , 如果求交任务得不到执行 , 那么也就不会有打分任务了 。2 单个打分任务的文档数较少 , 逻辑相对较轻 , 影响较小 。具体还是需要实验验证后才能得出明确结论 。 3 以时间片为调度粒度彻底改变 Task 为调度粒度的模式 , 换为时间片的模式 , 同时继续保持 FIFO 的模式 , 每个 Task 消耗完时间片后就被丢入队尾 , 直至超时或完成 。
以时间片为调度粒度时 , 此时众生平等 , 也就不需要关注 Task 之间的消耗程度孰轻孰重带来的饿死情况轻重的问题了 。时间片调度这种模式其实还有一个好处 , 对于一些召回数过低的请求 , 大概率在一个时间片内就能被执行完 , 那么它总体的等待时间就会少很多 , 从它要入队时开始分析 , 等待时间由:
sum(队列Task-处理完成所需耗时之和)降低到 sum(队列 Task-时间片之和) , 但这种模式有没有被引入的问题?
同样有的 , 对于高召回的请求需要多个时间片才能执行完 , 由于每次时间片执行完需要重新入队 , 那么它的等待时间相比 Task 的模式大概率是会增加的 。 不过这个问题相对来说还比较好解决 , 至少我们可以从以下两点来缓解和解决 。
1 增大时间片的粒度即将时间片粒度变大 , 如由原先的 500us , 增大为 1ms 。 从而可变相减少高召回请求的入队次数 。 当然这里也需要控制力度 , 极端情况下会退化为 Task 模式 。
2 增大高召回请求的时间片粒度即给高召回请求的分配的时间片为基础的时间片*2 , 或者*3 等等 , 这是一种有效解决高召回请求入队次数过多的方法 。 但是难点在于我们如何识别出高召回请求?这是一件很有挑战性的事情 , 不过这里先不介绍我们在筹划的做法 , 下文中会提到 。 事实上 , 它不止对于线程模型调度的设计有直接影响 , 对于稍后介绍的任务模型同样有影响 。
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?