新一代搜索引擎项目 ZeroSearch 设计探索( 四 )
细心的读者可能已经想到了 , 高召回请求是从结果上来看的 , 当我们从过程上来看时 , 问题就简单很多了 , 即回到了问题本身 , 它是入队次数过多的请求 。 那么我们只需要增加每次重新入队时被分配的时间片即可 , 一种最简单的方式是参考 vector 的内存增长的方式 , 更高级的方式这里就不展开了 , 索引数据和求交进度也是分配的参考项 。 从而有效解决高召回请求入队次数过多的问题 。 不过同样 , 这里的增长也需要控制力度 , 极端情况下会退化为 Task 模式 。
线程模型的介绍暂时就到这里了 , 下面我们看一下任务模型的设计 。
任务模型设计任务模型与线程模型有什么区别呢?
线程模型更专注于计算量(任务)的执行 , 而任务模型更专注于计算量(任务)的分配 。 对于执行者来说 , 它是任务无关的 , 而对于分配者来说 , 它本身就是任务的创建者 , 与任务是强相关的 。 在介绍线程模型时 , 其实我们已经大概清楚了 , 引擎中有以下 4 类任务 , 分别为清理任务 , 求交任务 , L1 打分任务 , L2 打分任务 。 其中清理任务较为独立 , 就不多花笔墨介绍了 。
下面直接看我们的求交打分任务模型: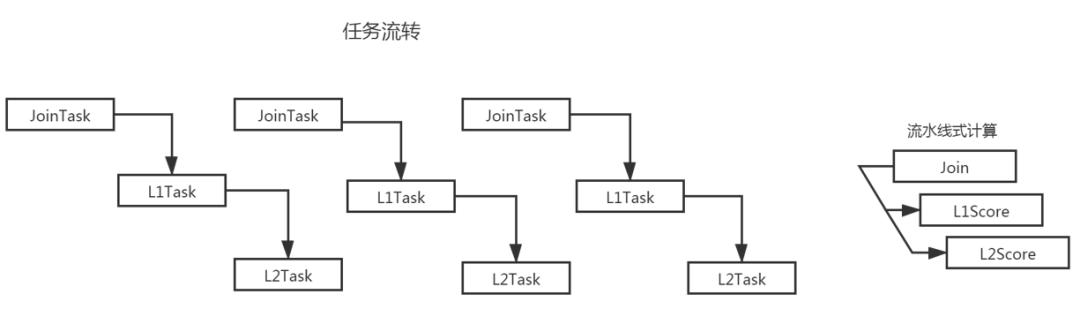 文章插图
文章插图
任务模型的核心要素为以下 3 点:
1 求交依然维持单库单线程求交(小库例外 , 多个小库合并一个求交任务)2 求交文档达到阈值时生成一个L1打分任务3 L1打分文档达到一定阈值时生成一个L2打分任务从而可以实现求交、L1 打分、L2 打分并行执行的效果 , 整体达到一个流水线的设计 , 就如上图所示一样 。 组内的上一代内存搜索引擎对于求交打分是一个阶段一个阶段的执行 , 整体是一个串行的模式
求交阶段 ---> L1打分阶段 ---> L2打分阶段在实际的实现里 , 上一代引擎对于每一个索引库其实是单线程边求交边 L1 打分的(因此本质上属于串行) , 等全部求交文档 L1 打分执行完毕后 , 再进行一次快速选择排序选出 TopK 得分的文档 , 然后把这部分文档送入 L2 打分 , L2 打分结束后 , 进行最终的 TopK 排序 , 然后进入回包处理阶段 。
在新引擎中 , 我们将求交与 L1 打分进行了拆分 , 并对打分任务以 Task 为粒度进行调度 。 为什么要这样做呢?当然是因为这是一种 CPU 利用率更高的做法 。 下面我们进行一个讨论 , 在这个讨论里我们先假定引擎的工作线程池只有一个 , 这样的话更利于分析 。
假设索引库数 = CPU逻辑核数1 在一个线程处理一个库内文档的求交与L1打分的形式下 , 各个线程耗时计算方式是固定的| ------------------|-------------------|求交耗时 +l1打分耗时最终耗时为: max(各个库的求交耗时+l1打分耗时)2 如果我们将求交与打分拆开 , 每次求交部分后 , 再将这部分送出去进行打分 , 让打分独立出来 , 从而达到流水线化:| ------------------|求交耗时|-------------------|打分耗时|-------------------------|总耗时理想情况下 , 最终耗时为:sum(各个库的求交耗时+l1打分耗时) / 引擎工作线程数 = avg(各个库的求交耗时+l1打分耗时)原因是计算总量虽然并未减少 , 但是被打散得更均匀了 。 很明显这种模式能更好的利用CPU资源假设索引库数 > CPU逻辑核数3 将会出现一个线程处理多个索引库 , 我们可以理解为这多个索引库只是一个更大的索引库 , 从而问题回归到讨论1与讨论2中 。 假设索引库数 < CPU逻辑核数4 老模式下其最终耗时依然为:max(各个库的求交耗时+l1打分耗时)新模式下其最终耗时为:(sum(各个库的求交耗时+l1打分耗时) - 非求交线程承担的L1打分耗时 ) / 求交线程数该值比avg(各个库的求交耗时+l1打分耗时)会更小 。 尽管拆分后的方式 CPU 利用率更高 , 但是很明显 , 新的方式在总吞吐方面并不会提高 。
计算基础1 单位时间内机器的算力是固定的2 每个请求需要消耗的算力并没用变因此在极限情况下 , 吞吐方面确实没有提升 。 不过实际上 , 在正常情况下 , 我们都会保证机器的负载在一个较低的水平 , 以此来保证服务的安全 , 而当机器负载未满时 , 新模式下长尾求交任务通过把l1打分逻辑分发出去可以更充分利用总的CPU资源 , 从而减少请求的耗时 。 我们可以得出以下两个结论:
- 新模式在极限情况下的总吞吐没有提升
- 相同吞吐情况下 , 新模式 CPU 利用率更高 , 因此请求处理平均耗时会更少
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?