新一代搜索引擎项目 ZeroSearch 设计探索( 二 )
2 无 RPC 框架设计引擎自身不携带 RPC 框架 , 我们以组件化的思想来进行设计 。 通俗来说 , 就是封装成了一个库 , 提供了初始化函数和唯一的检索入口函数来给到外部进行使用 。 这种方式有优有劣 , 优势为无须考虑上层的协议头 , 可灵活适配于各种 RPC 框架中 , 并复用已有的运维体系 。 劣势为对线程的控制能力较弱 , 理想情况下引擎自身的工作线程与 RPC 工作线程应当资源隔离 , 通过亲缘性各自分配和独占 CPU , 这一点在组件化里难以实现 。
事实上我们是面向 Controller-Proxy-Work 这一类 RPC 框架进行设计的 , 典型的如 SPP,Svrkit 等 , 并且在我们的实现过程中 , 将预处理和回包处理的逻辑均放到了 RPC-Work 线程中进行 。
3 以易用性为第一优先级组内上一代的内存搜索引擎由于基础配置项过多 , 引擎细节暴露过多 , 且欠缺配套的 debug 工具/能力 , 导致它的学习和维护成本都非常高 。 在新引擎的设计过程中 , 我们将易用性列为了第一优先级 , 本质上也是以服务业务为第一优先级 , 即便是性能方面也需要为易用性让步 。 易用性方面主要会体现在以下几点:
3.1 引擎的学习成本应具备梯度 , 满足快速入门使用的需求;
3.2 配置项尽可能少 , 尽可能避免暴露引擎细节 , 尽可能以通俗语言表达 , 如内存大小 , 线程数量等;
3.3 需要有全面的问题定位能力 , 根据经验 , 维护垂搜业务时 , 最常做的事情就是查文档为什么召不回 , 如果引擎具备问题一键定位的能力 , 那么可以有效的减少运维成本 。
需要说明的是 , 尽管这里提到了易用性 , 但是下面的内容不会涉及到我们为了提升引擎易用性采取的具体做法 。 这里之所以单独拎出来进行强调 , 在于根据我过往的业务开发经验 , 部门内上一代内存搜索引擎的学习和维护成本过高 , 与业务的快速发展已经不匹配 , 我认为作为一个基础平台 , 性能 100 分 , 还是 80 分 , 甚至是 70 分 , 只要可以通过加机器来解决 , 对于增长型业务来说基本就不太 care 了 , 而易用性(含可维护性)才是最优先被考量的因素 , 其对团队的整体效率有很大的影响 。
在清楚了大概的设计背景之后 , 可以开始真正考虑该如何设计我们的检索引擎了 。
线程模型设计下图是我们的检索组件目前使用的线程模型: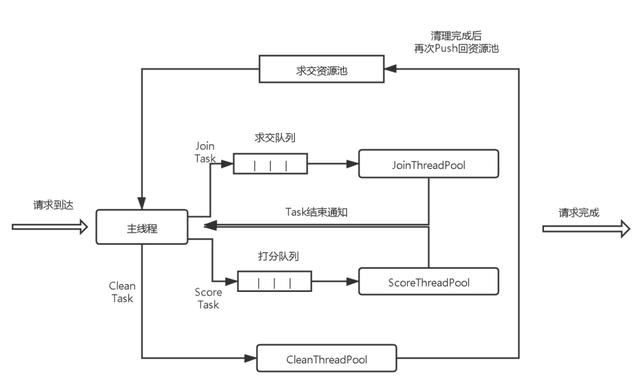 文章插图
文章插图
每个检索请求到达时 , 会生成一系列的求交与打分任务 , 在召回完成之后 , 会生成一个资源清理任务进行提交 , 请求完成 。
下面对图中的主要元素做下简单的介绍
1 主线程即RPC框架的Work线程 , 在Work线程中 , 会完成请求的预处理和回包处理的逻辑 , 并且处理求交或者打分任务完成后的回调逻辑 。 2 JoinThreadPool负责处理求交任务的线程池 , 在上面已经提到过 , 索引会分片分库 , 索引库是检索的基本单位 , 而一个求交任务至少会处理一个索引库(由于数据实时更新 , 系统中会存在一些小库 , 多个小库可能会被放到一个求交任务里进行处理) , 每个求交任务一旦分配到线程 , 就会将任务完整的执行完(或者超时) 。 3 ScoreThreadPool负责处理打分任务的线程池 , 打分任务分为L1打分任务和L2打分任务 , 但是线程池是共用的一个 。 对于L1打分任务 , 当一个求交任务完成的求交文档数量达到一定程度时 , 便会生成一个L1打分任务Push到打分队列中 。 L2打分任务同理 , 也是等到L1打分文档达到一定数量才会生产 。 4 CleanThreadPool负责处理资源清理任务的线程池 , 即资源的清理是异步进行的5 求交资源池负责管理求交时需要的一些数据结构 , 以资源池的形式来完成复用可以看到整个线程模型是以 Task 为调度粒度的 , 这种模型有个比较大的缺陷 , 每个 Task 的消耗其实是不一致的 。 对于求交任务而言 , 每个任务会将一个索引库给求交完(达到限制或者超时) , 而随之产生的 L1 打分任务和 L2 打分任务 , 每个任务其实都只是求交出来的部分文档 , 因此求交任务的消耗是非常高的 , 并且求交任务在入队时是在一个 for 循环里集中式的入队(直到所有的索引库都分配完) , 为了防止打分任务饿死 , 这里划分了 3 个线程池以避免这个问题 。
然而划分多个线程池本身就是问题所在 , 至少存在以下 3 个方面的问题:1 增加了配置项 , 降低了易用性 。
2 其实业务并不知道该如何去对各个线程池的线程数量进行配置(尽管引擎会简单的根据 CPU 逻辑核数量进行默认设置) , 只能不断去调整测试来达到一个合适值 。
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?