新一代搜索引擎项目 ZeroSearch 设计探索
本文作者:kaelhua , 腾讯 WXG 后台开发工程师 文章插图
文章插图
背景写这篇文章很大的原因在于不论是内网还是外网 , 分享内存检索引擎设计的资料都非常稀少 , 且存量的资料大多侧重于功能性的介绍 。
另一方面 , 在磁盘检索引擎方面 , 由于开源搜索引擎 ES 的盛行 , 对于其使用的索引库 lucence 的分析资料反而较为丰富 。
本文意在通过分享对于内存检索引擎的认识 , 核心的解决方案 , 和一些优化方向的思考等等 , 略微填补一下关于内存检索引擎设计的资料空缺 。
需要说明的是本人进入搜索领域的时间并不长 , 尽管之前搭建过一些垂类搜索系统 , 但只是站在应用层面进行使用 , 真正从事引擎设计的工作也是通过今年 4 月份左右组内重新设计新一代搜索引擎的项目 ZeroSearch 开始 , 恰巧承担了在线检索的设计与开发 。 因此这并不是一份多么标准的答案 , 而是我们对于引擎设计的探索 , 其质量还需时间检验和调整 。
本文属于 ZeroSearch 系列分享中的在线检索设计分享 。 在本文中假定读者已经对搜索引擎有了基本的了解 , 至少对倒排求交 , 打分排序有基本的概念 。
系统认知对于系统的认知深度 , 会决定我们怎么去看待内存检索这样一个问题 , 以及由此而产生的的设计方案 。 尽管本文要讲的是内存检索引擎设计 , 然而我们还是得从对磁盘搜索引擎的认识开始 。
由于 ES 的盛行 , 以及网页搜索(搜索领域的大 boss)体验的存在 , 大多数人对检索引擎的认识可能都是基于磁盘检索引擎来理解的 , 即系统的倒排 , 正排数据都位于磁盘中 , 只有在执行检索时 , 才会将相关的数据 load 到内存中 。
其整体的流程大概如图所示: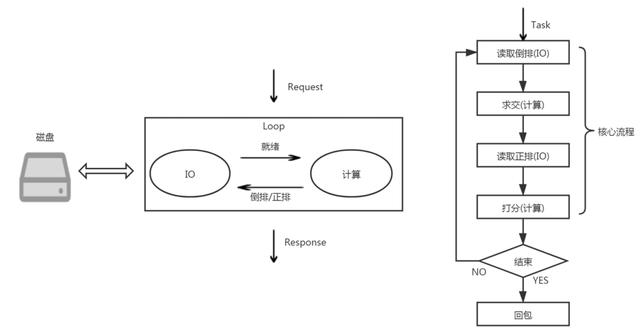 文章插图
文章插图
磁盘搜索引擎在设计的过程中面临的主要问题为:
- 同时兼具计算密集型与IO密集型任务
- 磁盘与内存及CPU存在数量级差距的性能GAP , 磁盘资源属于瓶颈 , 而计算量富余 。
- 任务调度的设计 , 即管理 IO 任务与计算任务
- IO 优化 如异步 IO 设计 , IOCache 优化 , 索引压缩等等
现在回到内存搜索引擎的讨论上来 。 很明显 , 内存检索引擎在去除磁盘 IO 后 , 其要解决的核心问题是计算量的分配问题 , 即如何合理的分配计算量 , 能尽可能的让优质结果展现给用户 。
下面是我们给内存检索引擎制定的核心流程:
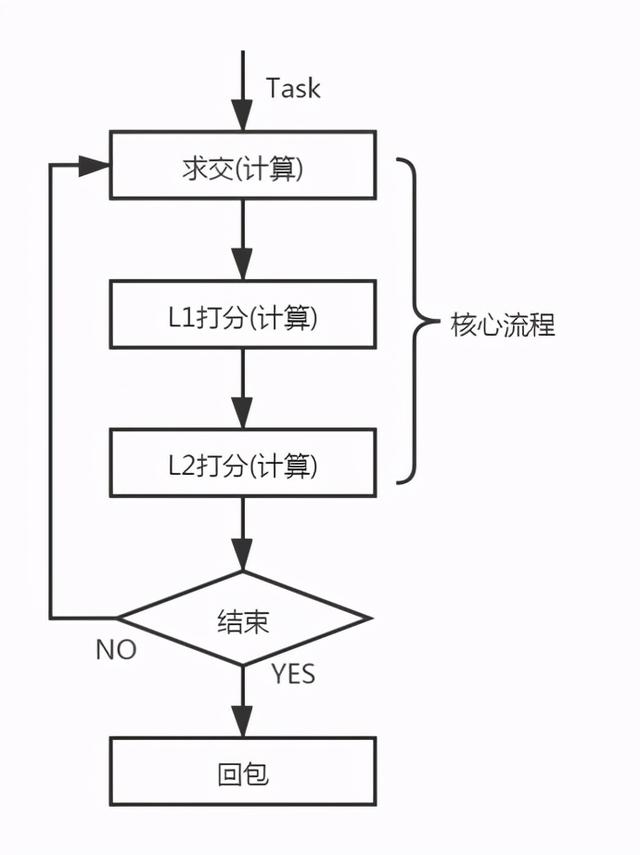 文章插图
文章插图可以看到我们对于计算量的分配 , 抽象出了求交 , L1 打分 , L2 打分等 3 个逻辑阶段 。
求交即根据查询串取出对应的倒排链进行求交 , 得到结果文档L1打分求交出来的文档均会送入L1打分L2打分L1得分Top的文档才能进入L2打分这里为何要将打分分为两个阶段呢?1 满足高求交数的需要
由于倒排数据处在内存中 , 因此单篇文档的求交消耗较少 , 限制引擎召回量的瓶颈往往不在求交 , 而在打分 。 轻量级的打分配合高求交数 , 可以避免求交截断导致的文档无法召回问题的出现
2 满足轻量级业务的打分需求
对于一些排序较简单的业务 , 不需要单独的精排服务 , 可以在引擎的 L2 打分过程中满足它的需求 。
需要注意的是对于一些高消耗的模型 , 我们会放在更高层次的排序中 , 并对其进行抽离 , 放在独立的 tf 服务上执行 , 并不会放在引擎的 L1、L2 阶段来执行 。
L0打分在离线索引过程中我们会提供接口用于计算文档的质量分 , 因此全量文档计算都会进行质量分的计算 , 建立倒排索引过程中 , 质量分越高的文档 , 排序越靠前 , 以保证被优先查找到
核心设计设计背景在讲述核心设计之前 , 需要先了解以下几点背景
1 索引分片分库索引会先进行分片 , 多个分片再合并为一个索引库 。 分片数一旦指定后便不可更改 , 但是索引库的库数是可以灵活调整的 , 可以满足业务数据增长 , 索引数据多集群划分的需求 。 在检索过程中 , 索引库是检索的基本单位 。 这一点与 ES 可做一个简单的对比 , ES 为库->分片(多个库)->实例(多个分片)的设计 , 而我们的设计为分片->库(多个分片)->实例(多个库) , 即我们将数据分片放到了更底层 , 打开了它的数量限制 , 同时对库的数量进行了收敛 , 原因在于库数越多 , 引擎性能将越差 。 关于索引分片分库的详细背景和设计后续组内会另有同学来进行介绍 。
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 钢筋|海南国道G360文临公路项目引进钢筋智能“焊”将
- 名单|河南8个项目入选国家级示范名单
- 新一代|外媒: 高通新一代旗舰处理器或命名为骁龙888
- 项目|Yearn帝国正在崛起,有多少DeFi项目开始瑟瑟发抖
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 团队|为什么项目管理非常重要?