郝建业认为,“仿真技术和形式化验证是两条差别比较大的路线,可以说是两个极端。其中基于深度强化学习的仿真技术笨一点,一般通过遍历所有可能场景来寻找可行的方案,而形式化验证则精一点,可以从理论上直接保证结果是可靠的,“但它们都是值得探索的方向,是互补的。”
在论文中,郝建业研究的也是相对简单的场景。而如今,这项技术对于智能电网乃至智慧城市的开发都已具有非常重要的启发意义。
文章插图
论文地址:https://groups.csail.mit.edu/sdg/pubs/2016/norms-fse16.pdf
多学科交叉的有效性或许也可以从历史中寻找渊源。博弈论最早起源于经济学,但它的创始人,实际上是计算机之父冯·诺依曼,博弈论与计算机科学之间或许早就暗藏千丝万缕的联系,如今终于在AI时代被放大。
计算机科学在艾伦·图灵提出图灵机概念后,早就有了统治科学世界的野心。哪怕十分简陋,如今做科研谁能离开计算机呢?深度学习正好在人们困惑、嘲笑计算机只能处理代码,不能理解感官世界的丰富时,提供了一个连接桥梁。似乎在神经网络中,万物都能被统一为无数的电脉冲,不同学科之间的隔阂亦不再厚重和神秘。
在与网易伏羲人工智能实验室、南洋理工大学等合作完成的论文“Wuji: Automatic Online Combat Game Testing Using Evolutionary Deep Reinforcement Learning”中,郝建业等人延续多学科交叉道路,研究了如何将演化学习与强化学习结合起来,提出了动态游戏测试框架Wuji,从而将游戏测试自动化,并提高效率。
文章插图
论文地址:https://nos.netease.com/mg-file/mg/neteasegamecampus/art_works/20200812/202008122020238586.pdf
测试游戏潜在bug的一个难点,就是触发,“有些bug可能非常隐蔽,大部分玩家都不会触发,比如它可能在某个难度很高的关卡中,而一旦触发就会带来非常不好的体验。”
而现有深度强化学习主要聚焦于赢得胜利,获取高分,因此在开发探索能力上受限于目标,也就是奖励函数的设置。
例如,下图展示了一个简单的迷宫游戏,其中机器人需要寻找左上角的黄金。如果机器人到达图中标记的绿点、黄点或红点,就会触发错误。机器人可以轻松到达黄点,因为它们靠近初始位置。然而,绿点和红点更难到达,因为需要找到更精准的路径,或者距离目标太远。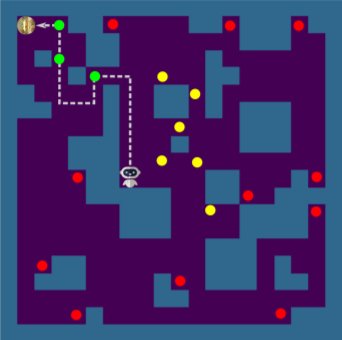
文章插图
强化学习算法的两大阶段是探索(exploration)和利用(exploitation),演化算法相当于提升了强化学习算法的探索能力,从而得以遍历不同的策略,触及角落中隐藏的bug。这样的策略,其实也相当于一种游戏测试脚本,脚本指导智能体去玩游戏,遍历各种场景和各种互动。
为了实现目标,Wuji不仅考虑完成任务,还考虑寻找不同的方向,这两种策略相辅相成。比如在迷宫游戏中,完成任务的策略有助于达到一般随机策略难以覆盖的绿点,探索的策略则有助于触及可能不在游戏主线中的红点。
当时这项成果称得上是业界第一个利用机器学习方法进行游戏测试的工具,帮助游戏测试人员发现了大量多人在线游戏中之前未知的bug。相关论文也在软件工程顶级会议ASE 2019中获得了ACM SIGSOFT 杰出论文奖。
文章插图
文章插图
部分测试场景示例
系统除了要满足全局优化目标,即社会利益最优,还需要考虑每个智能体的利益问题,这就涉及到了公平性,也因此郝建业格外注重这两个方面。甚至要考虑存在性问题,把多智能体系统类比为神经网络,一个智能体在某些场景下是不能像一个神经元那样被轻易dropout的。映射到真实世界的人类社会,在满足社会、企业利益目标的时候,一个普通人也不该被轻易地剥削或牺牲。
- 内卷|02 双11的囚徒困境
- 代码|郝俊杰升任代码乾坤技术合伙人,掌舵物理引擎夯实元宇宙底层
- 囚徒|斗鱼虎牙的钱途陌路
- 山东省临清市金郝庄镇:推进电商发展,助力乡村振兴
- “狼性兔子”搅动快递行业,加剧囚徒困境
- 实力|《平凡的荣耀》四大实力配角,唯郝平、田昊最为犀利,过目难忘
- 曾毅对话郝景芳:人工智能不是未来,而是现在 | VC洞见