直观地说,该算法是面向合作的,并且对对手的自私、剥削行为也有防御能力。
文章插图
论文地址:http://ala2018.it.nuigalway.ie/papers/ALA_2018_paper_18.pdf
科研更像是在撒播种子,学者们依靠期望和想象去支撑意志力,从而坚持不懈地耕耘。这一过程存在太大的不确定性,但每次或隔一个月、或隔十年回到原野时,都期盼能看到令人出乎意料的景观。
郝建业坦言,“尽管最初只是非常简单的模型,但时间的力量以及外部环境的助推,可以令其茁壮成长,并最终在现实中变成让我们惊叹的样子。”
他没有仅仅满足于增加问题复杂度,而是进一步将目光聚焦到了更贴近现实的层面——研究自动驾驶场景的多智能体系统。

文章插图
SMARTS针对的是仿真平台的两个限制性问题,一个是环境单一,比如大部分仿真平台都只设置了晴天的天气;另一个则是缺少与其它智能体的互动场景,比如下图中的“双重合并”。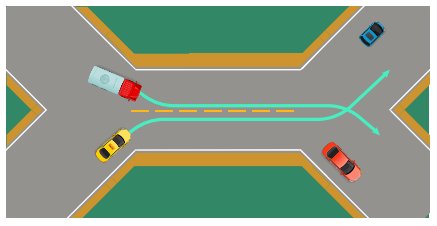
文章插图
可以说,多样的互动场景是SMARTS的一大特色。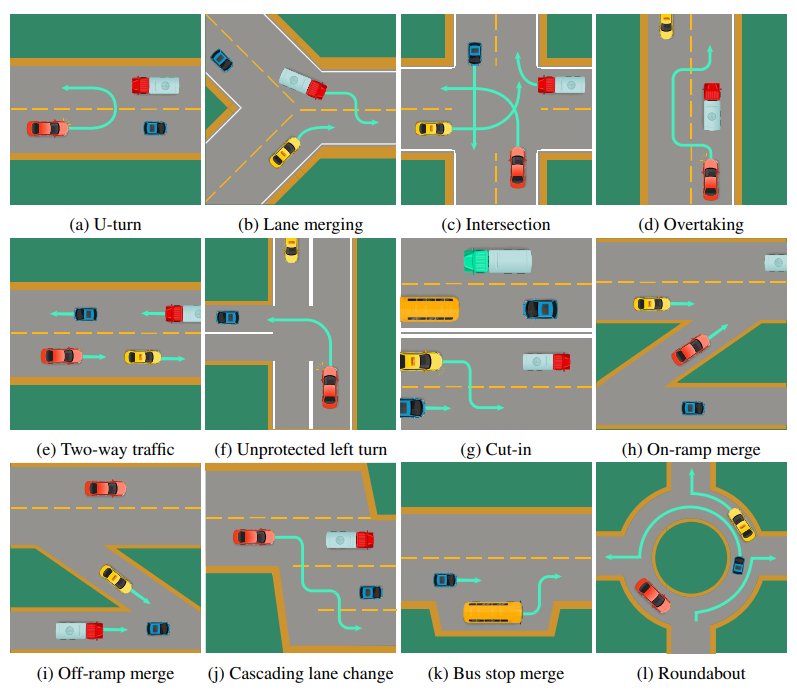
文章插图
SMARTS的相关论文“SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving”发表在机器人顶会之一CoRL 2020上,并斩获最佳系统论文奖。
文章插图
论文地址:https://arxiv.org/pdf/2010.09776.pdf
缺乏互动场景研究会导致一个问题,即自动驾驶汽车在遭遇复杂场景时,通常选择更加保守的策略,比如放慢速度,而不是主动寻找另一条出路。即便是采用了保守的方案,也不见得安全。
在 2018 年的加利福尼亚州,57% 的自动驾驶汽车事故是追尾事故,29% 是侧滑事故。所有这些都是其他汽车造成的,因此可以归因于自动驾驶汽车的保守性。
类比于自动驾驶汽车的L0-L5级别,郝建业等人在这项研究中提出了“多智能体学习级别”,或简称“M级别”。
其中,M0级别的智能体为完全遵守规则的保守派;M1级别的智能体可以在线学习,以增加应对未知情况的能力;M2级别的智能体要学会建模其他智能体,但还没有直接的信息交换;M3级别的智能体在训练期间会进行信息交换,在部署时则不需要;M4级别的智能体需要学会应对局域交互场景,比如十字路口会车,找到符合纳什均衡或其他均衡的策略;M5级别的智能体则需要在满足全局最优的前提下,去学习局域决策。
郝建业等人认为,迄今为止,自动驾驶研究主要集中在 M0,对 M1 和 M2 的尝试非常有限,而一个关键原因是缺乏对道路上的异构智能体之间交互的合适模拟。看来这个标准相比“L级别”要更加严苛。
在第二届DAI(DAI 2020)上,华为诺亚基于该平台举办了自动驾驶挑战赛,郝建业回忆道,“比赛中,选手们没有局限于强化学习,提出了多种不同的解决方案,这是一个很好的现象。”
他进一步说道,“SMARTS有两方面的价值,一方面是它作为平台,可以让所有做相关研究的人针对自动驾驶的不同场景做相关算法的研究。另一方面,我们希望通过这个平台,生成多样化的真实社会模型,从而让自动驾驶算法在现实落地中安全、有效。”
17世纪,当伽利略观察金属球在光滑的斜面上滚过时,不会想到这背后的物理学支撑着如今在天空中飞驰的蜻蜓状庞然巨物。
多智能体强化学习从最初的表格学习,进化到今天的自动驾驶模拟,亦宛如完成了《2001太空漫游》中的史诗级蒙太奇一般。
文章插图
相信时间之力量的信念,或许有一部分来自郝建业在MIT期间受到的潜移默化的影响。
“CSAIL给我的整体感觉是,学术氛围非常浓厚。他们有最顶尖的人才,学生、老师之间交流起来没有隔阂,没有辈分顾虑,非常舒服,学术合作的效率也非常高。”
- 内卷|02 双11的囚徒困境
- 代码|郝俊杰升任代码乾坤技术合伙人,掌舵物理引擎夯实元宇宙底层
- 囚徒|斗鱼虎牙的钱途陌路
- 山东省临清市金郝庄镇:推进电商发展,助力乡村振兴
- “狼性兔子”搅动快递行业,加剧囚徒困境
- 实力|《平凡的荣耀》四大实力配角,唯郝平、田昊最为犀利,过目难忘
- 曾毅对话郝景芳:人工智能不是未来,而是现在 | VC洞见