在那时候,团队以及相关领域的学者,都在研究怎么用强化学习等方法,在不同的博弈环境下快速学习到纳什均衡。“纳什均衡是博弈论里最核心的概念,甚至上世纪90年代的很多相关工作都沿着这个方向来做。”
在博弈论中,纳什均衡是指在包含两个或以上参与者的非合作博弈中,假设每个参与者都知道其他参与者的均衡策略的情况下,没有参与者可以通过单方面改变自身策略使自身受益。
囚徒困境中两个囚徒都选择招供的策略,就是一个典型的纳什均衡解。两个囚徒无法与对方进行合作(或沟通),此时选择招供就会比不招供收益更大。
那么,这类研究存在什么问题呢?很明显,均衡解虽然稳定,但不一定是最好的解。在囚徒困境中,双方都不招供其实才是全局最优解,而全局最优解又存在不稳定的问题。此外,公平性问题也是存在的,即在一个均衡点上,每一方的利益不一定对等。
因此,郝建业就在探索,怎么用强化学习的方法,让智能体有意愿、有动力、有理性地去学习到社会全局最优的、公平的解,以及研究是否存在新型的均衡解,即保留原始均衡稳定性的特点,同时有具备公平性,社会最优等属性,也就是从“策略层面”而言的均衡 (strategy equilibrium)。
而当初那些基于表格的toy example,在深度强化学习的助力下,得以应对更加复杂的场景,智能体也得以产生更加多样化和灵活的决策。“反过来说,如果我们细看现在的深度强化学习的代表工作,很多其实都是借鉴了上世纪90年代至2010年之前的工作,并扩展了深度学习方法。”然而目前大部分深度强化学习下的工作还没有走到关注“策略均衡”的阶段,还停留在类比于“基于表格强化学习的多智能体系统研究“相对早期的阶段。
郝建业将“从简单到复杂”的理念贯彻至今,并在2019年首届国际分布式AI大会上,以复杂场景的囚徒困境研究获得了DAI最佳论文奖。这一次,囚徒不再限于两个选择,而是无限个,虽然这也只让其更自由了一点点。
文章插图
经典囚徒困境对囚徒的决策选择做了很大限制,要么合作,要么背叛。但囚徒困境并不是凭空捏造的思维游戏,不只有《蝙蝠侠前传2》中的小丑会玩。
在现实世界,也存在因为无法完全信任或推测对方心理,导致选择相信就可能遭遇损失的情况。可以说,存在竞争和信任危机时都容易引发囚徒困境,比如战争,乃至任何形式的合作关系。毕竟,合作意味着妥协,意味着出让部分利益,这就让背叛者有机可乘。在论文中,郝建业等人将这种背叛行为称之为“剥削”。
因此,在这项工作中,郝建业等人应用深度强化学习,探索了在复杂场景下,能抵抗对手剥削,同时又能适当合作的智能体策略。这其中的关键点,就在于推测对手心理。
他们提出了一个合作度检测网络,它相当于一个心理模型。给定对方的一系列动作,来预测对方的合作程度。该网络结合了LSTM和自编码器,可以保证对观察到的动作进行有效的特征提取,加快心理模型的训练速度,提高鲁棒性。
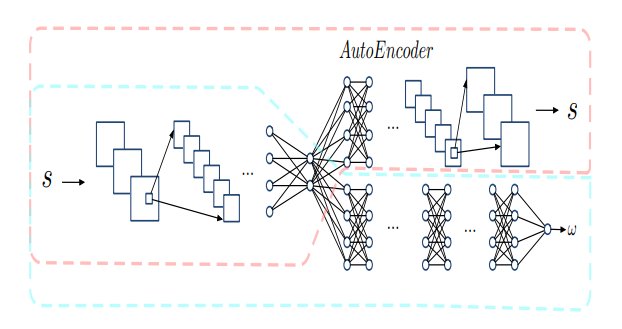
文章插图
比如在 Apple-Pear 游戏中,有一个红苹果和一个绿梨。蓝色智能体喜欢苹果,而红色智能体喜欢梨。每个智能体有四个动作:上、下、左、右,每走一步都会产生 0.01 的成本。当智能体走到水果对应方格时,就能收集到水果。
文章插图
当蓝色(红色)智能体单独收集一个苹果(梨)时,它会获得更高的奖励 1。当智能体收集到不喜欢的水果时,则只能获得更低的奖励 0.5。但是,当它们分享一个梨或一个苹果时,它们都会获得相应奖励的一半。
以合作度为度量,智能体可以产生更加多样化的决策。实验结果也不意外地显示,这两个智能体合作程度越高,总体奖励越高。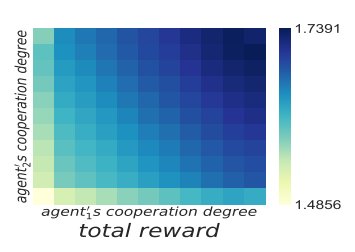
文章插图
郝建业将这种博弈场景称之为序列囚徒困境(SPD),它更加接近于现实世界中的博弈过程,即结合观察来随时调整策略。
训练方面,该方法包括两个阶段:离线和在线阶段。离线阶段生成不同合作度的策略并训练合作度检测网络。在线阶段则根据检测到的对手的合作程度,从连续的候选范围中自适应地选择具有适当合作程度的策略。
- 内卷|02 双11的囚徒困境
- 代码|郝俊杰升任代码乾坤技术合伙人,掌舵物理引擎夯实元宇宙底层
- 囚徒|斗鱼虎牙的钱途陌路
- 山东省临清市金郝庄镇:推进电商发展,助力乡村振兴
- “狼性兔子”搅动快递行业,加剧囚徒困境
- 实力|《平凡的荣耀》四大实力配角,唯郝平、田昊最为犀利,过目难忘
- 曾毅对话郝景芳:人工智能不是未来,而是现在 | VC洞见