特征工程与模型调优( 四 )
现在我们分析编码员调查报告数据集的 Age 特征并看看它的分布 。
fig, ax = plt.subplots()fcc_survey_df['Age'].hist(color='#A9C5D3',edgecolor='black',grid=False)ax.set_title('Developer Age Histogram', fontsize=12)ax.set_xlabel('Age', fontsize=12)ax.set_ylabel('Frequency', fontsize=12)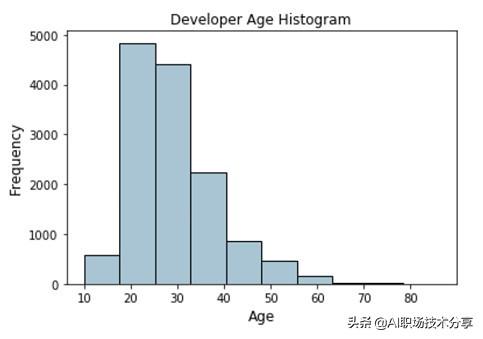 文章插图
文章插图
描述开发者年龄分布的直方图上面的直方图表明 , 如预期那样 , 开发者年龄分布仿佛往左侧倾斜(上年纪的开发者偏少) 。 现在我们根据下面的模式 , 将这些原始年龄值分配到特定的区间 。
Age Range: Bin\---------------0 - 9 : 010 - 19 : 120 - 29 : 230 - 39 : 340 - 49 : 450 - 59 : 560 - 69 : 6... and so on我们可以简单地使用我们先前学习到的数据舍入部分知识 , 先将这些原始年龄值除以 10 , 然后通过 floor 函数对原始年龄数值进行截断 。
fcc_survey_df['Age_bin_round'] = np.array(np.floor(np.array(fcc_survey_df['Age']) / 10.))fcc_survey_df[['ID.x', 'Age','Age_bin_round']].iloc[1071:1076]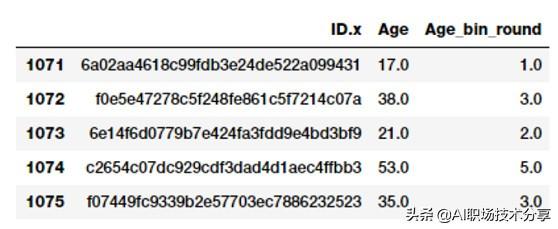 文章插图
文章插图
通过舍入法分区间你可以看到基于数据舍入操作的每个年龄对应的区间 。 但是如果我们需要更灵活的操作怎么办?如果我们想基于我们的规则或逻辑 , 确定或修改区间的宽度怎么办?基于常用范围的分区间方法将帮助我们完成这个 。 让我们来定义一些通用年龄段位 , 使用下面的方式来对开发者年龄分区间 。
Age Range : Bin\---------------0 - 15 : 116 - 30 : 231 - 45 : 346 - 60 : 461 - 75 : 575 - 100 : 6基于这些常用的分区间方式 , 我们现在可以对每个开发者年龄值的区间打标签 , 我们将存储区间的范围和相应的标签 。
bin_ranges = [0, 15, 30, 45, 60, 75, 100]bin_names = [1, 2, 3, 4, 5, 6]fcc_survey_df['Age_bin_custom_range'] = pd.cut(np.array(fcc_survey_df['Age']),bins=bin_ranges)fcc_survey_df['Age_bin_custom_label'] = pd.cut(np.array(fcc_survey_df['Age']),bins=bin_ranges, labels=bin_names)\# view the binned featuresfcc_survey_df[['ID.x', 'Age', 'Age_bin_round','Age_bin_custom_range','Age_bin_custom_label']].iloc[10a71:1076]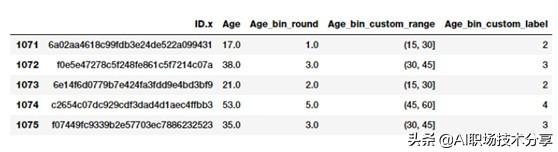 文章插图
文章插图
开发者年龄的常用分区间方式自适应分区间使用等宽分区间的不足之处在于 , 我们手动决定了区间的值范围 , 而由于落在某个区间中的数据点或值的数目是不均匀的 , 因此可能会得到不规则的区间 。 一些区间中的数据可能会非常的密集 , 一些区间会非常稀疏甚至是空的!自适应分区间方法是一个更安全的策略 , 在这些场景中 , 我们让数据自己说话!这样 , 我们使用数据分布来决定区间的范围 。
基于分位数的分区间方法是自适应分箱方法中一个很好的技巧 。 量化对于特定值或切点有助于将特定数值域的连续值分布划分为离散的互相挨着的区间 。 因此 q 分位数有助于将数值属性划分为 q 个相等的部分 。 关于量化比较流行的例子包括 2 分位数 , 也叫中值 , 将数据分布划分为2个相等的区间;4 分位数 , 也简称分位数 , 它将数据划分为 4 个相等的区间;以及 10 分位数 , 也叫十分位数 , 创建 10 个相等宽度的区间 , 现在让我们看看开发者数据集的 Income 字段的数据分布 。
fig, ax = plt.subplots()fcc_survey_df['Income'].hist(bins=30, color='#A9C5D3',edgecolor='black',grid=False)ax.set_title('Developer Income Histogram',fontsize=12)ax.set_xlabel('Developer Income', fontsize=12)ax.set_ylabel('Frequency', fontsize=12)
- 如何进行不确定度估算:模型为何不确定以及如何估计不确定性水平
- 3分钟短文:说说Laravel模型关联关系最单纯的“一对一”
- 如何成为大数据工程师 都需要具备哪些技能
- 自用:HMM隐马尔可夫模型学习笔记(2)-前向后向算法
- 技术|大咖说|身兼工程师、创业者的青年科学家俞凯力求突破 跨界推动科研创新应用
- 腾讯游戏开发工程师:Linux 机器 CPU 毛刺问题排查
- 美国工程师:5G时代已被中国技术抢占,6G技术休想快人一步
- OpenAI推出数学推理证明模型,推理结果首次被数学家接受
- JVM 之java内存模型
- Google的神经网络表格处理模型TabNet介绍