特征工程与模型调优( 二 )
popsong_df = pd.read_csv('datasets/song_views.csv',encoding='utf-8')popsong_df.head(10) 文章插图
文章插图
数值特征形式的歌曲收听总数根据这张截图 , 显而易见 listen_count 字段可以直接作为基于数值型特征的频数或总数 。
二值化基于要解决的问题构建模型时 , 通常原始频数或总数可能与此不相关 。 比如如果我要建立一个推荐系统用来推荐歌曲 , 我只希望知道一个人是否感兴趣或是否听过某歌曲 。 我不需要知道一首歌被听过的次数 , 因为我更关心的是一个人所听过的各种各样的歌曲 。 在这个例子中 , 二值化的特征比基于计数的特征更合适 。 我们二值化 listen_count 字段如下 。
> watched = np.array(popsong_df['listen_count'])>> watched[watched >= 1] = 1>> popsong_df['watched'] = watched你也可以使用 scikit-learn 中 preprocessing 模块的 Binarizer 类来执行同样的任务 , 而不一定使用 numpy 数组 。
from sklearn.preprocessing import Binarizerbn = Binarizer(threshold=0.9)pd_watched =bn.transform([popsong_df['listen_count']])[0]popsong_df['pd_watched'] = pd_watchedpopsong_df.head(11) 文章插图
文章插图
歌曲收听总数的二值化结构你可以从上面的截图中清楚地看到 , 两个方法得到了相同的结果 。 因此我们得到了一个二值化的特征来表示一首歌是否被每个用户听过 , 并且可以在相关的模型中使用它 。
数据舍入处理连续型数值属性如比例或百分比时 , 我们通常不需要高精度的原始数值 。 因此通常有必要将这些高精度的百分比舍入为整数型数值 。 这些整数可以直接作为原始数值甚至分类型特征(基于离散类的)使用 。 让我们试着将这个观念应用到一个虚拟数据集上 , 该数据集描述了库存项和他们的流行度百分比 。
items_popularity =pd.read_csv('datasets/item_popularity.csv',encoding='utf-8')items_popularity['popularity_scale_10'] = np.array(np.round((items_popularity['pop_percent'] * 10)),dtype='int')items_popularity['popularity_scale_100'] = np.array(np.round((items_popularity['pop_percent'] * 100)),dtype='int')items_popularity 文章插图
文章插图
不同尺度下流行度舍入结果基于上面的输出 , 你可能猜到我们试了两种不同的舍入方式 。 这些特征表明项目流行度的特征现在既有 1-10 的尺度也有 1-100 的尺度 。 基于这个场景或问题你可以使用这些值同时作为数值型或分类型特征 。
相关性高级机器学习模型通常会对作为输入特征变量函数的输出响应建模(离散类别或连续数值) 。 例如 , 一个简单的线性回归方程可以表示为
 文章插图
文章插图
其中输入特征用变量表示为
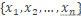 文章插图
文章插图
权重或系数可以分别表示为
 文章插图
文章插图
目标是预测响应 *y*.
在这个例子中 , 仅仅根据单个的、分离的输入特征 , 这个简单的线性模型描述了输出与输入之间的关系 。
然而 , 在一些真实场景中 , 有必要试着捕获这些输入特征集一部分的特征变量之间的相关性 。 上述带有相关特征的线性回归方程的展开式可以简单表示为
- 如何进行不确定度估算:模型为何不确定以及如何估计不确定性水平
- 3分钟短文:说说Laravel模型关联关系最单纯的“一对一”
- 如何成为大数据工程师 都需要具备哪些技能
- 自用:HMM隐马尔可夫模型学习笔记(2)-前向后向算法
- 技术|大咖说|身兼工程师、创业者的青年科学家俞凯力求突破 跨界推动科研创新应用
- 腾讯游戏开发工程师:Linux 机器 CPU 毛刺问题排查
- 美国工程师:5G时代已被中国技术抢占,6G技术休想快人一步
- OpenAI推出数学推理证明模型,推理结果首次被数学家接受
- JVM 之java内存模型
- Google的神经网络表格处理模型TabNet介绍