Google的神经网络表格处理模型TabNet介绍
Google Research的TabNet于2019年发布 , 在预印稿中被宣称优于表格数据的现有方法 。它是如何工作的 , 又如何可以尝试呢?
 文章插图
文章插图
表格数据可能构成当今大多数业务数据 。考虑诸如零售交易 , 点击流数据 , 工厂中的温度和压力传感器 , 银行使用的KYC (Know Your Customer) 信息或制药公司使用的模型生物的基因表达数据之类的事情 。
论文称为TabNet: Attentive Interpretable Tabular Learning(arxiv/1908.07442) , 很好地总结了作者正在尝试做的事情 。"Net"部分告诉我们这是一种神经网络 , "Attentive "部分表示它正在使用一种注意力机制 , 旨在实现可解释性 , 并用于表格数据的机器学习 。
它是如何工作的?TabNet使用一种软功能选择将重点仅放在对当前示例很重要的功能上 。这是通过顺序的多步骤决策机制完成的 。即 , 以多个步骤自上而下地处理输入信息 。正如论文所指出的那样 , "自上而下关注的思想是从处理视觉和语言数据或强化学习中得到的启发 , 可以在高维输入中搜索一小部分相关信息 。 "
尽管它们与BERT等流行的NLP模型中使用的transformer 有些不同 , 但执行这种顺序关注的构件却称为transformer 块 。这些transformer 使用自注意力机制 , 试图模拟句子中不同单词之间的依赖关系 。 这里使用的transformer类型试图使用"软"特性选择 , 一步一步地消除与示例无关的那些特性 , 这是通过使用sparsemax函数完成的 。
这篇论文的第一个图 , 如下重现 , 描绘了信息是如何聚集起来形成预测的 。
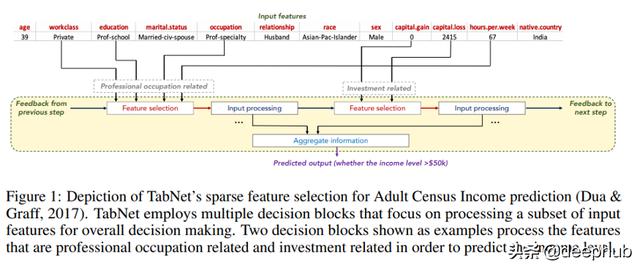 文章插图
文章插图
TabNet的一个好特性是它不需要特性预处理 。 另一个原因是 , 它具有内置的可解释性 , 即为每个示例选择最相关的特性 。 这意味着您不必应用外部解释模块 , 如shap或LIME 。
在阅读本文时 , 要理解这个架构中发生了什么并不容易 , 但幸运的是 , 已经发表的代码稍微澄清了一些问题 , 并表明它并不像您可能认为的那样复杂 。
我怎么使用它?现在TabNet有了更好的实现 , 如下所述:一个是PyTorch的接口 , 它有一个类似scikit学习的接口 , 还有一个是FastAI的接口 。
根据作者readme描述要点如下:
为每个数据集创建新的train.csv , val.csv和test.csv文件 , 我不如读取整个数据集并在内存中进行拆分(当然 , 只要可行) , 所以我写了一个在我的代码中为Pandas提供了新的输入功能 。
修改data_helper.py文件可能需要一些工作 , 至少在最初不确定您要做什么以及应该如何定义功能列时(至少我是这样) 。 还有许多参数需要更改 , 但它们位于主训练循环文件中 , 而不是数据帮助器文件中 。 有鉴于此 , 我还尝试在我的代码中概括和简化此过程 。
我添加了一些快速的代码来进行超参数优化 , 但到目前为止仅用于分类 。
还值得一提的是 , 作者提供的示例代码仅显示了如何进行分类 , 而不是回归 , 因此用户也必须编写额外的代码 。 我添加了具有简单均方误差损失的回归功能 。
使用命令行运行测试python train_tabnet.py \ --csv-path data/adult.csv \ --target-name "<=50K" \ --categorical-features workclass,education,marital.status,\ occupation,relationship,race,sex,native.country\ --feature_dim 16 \ --output_dim 16 \ --batch-size 4096 \ --virtual-batch-size 128 \ --batch-momentum 0.98 \ --gamma 1.5 \ --n_steps 5 \ --decay-every 2500 \ --lambda-sparsity 0.0001 \ --max-steps 7700强制性参数包括--csv-path(指向CSV文件的位置) , -target-name(具有预测目标的列的名称)和-category-featues(逗号分隔列表) 应该视为分类的功能) 。其余输入参数是需要针对每个特定问题进行优化的超参数 。但是 , 上面显示的值直接取自TabNet论文 , 因此作者已经针对成人普查数据集对其进行了优化 。
- 在图上发送消息的神经网络MPNN简介和代码实现
- Google官方新闻更新1012
- 深度学习入门之第五章:经典卷积神经网络
- 如何把百度伪装成Google
- 机器学习实战:GNN(图神经网络)加速器的FPGA解决方案
- GHunt:可嗅探Google账户的OSINT工具
- 苹果2020年度App、游戏排行榜出炉
- 使用CatBoost和NODE建模表格数据对比测试
- 每天有超过10亿人使用Google搜索
- Google|1999年,奥尼尔买了谷歌公司100万原始股,这笔钱现在值多少?