特征工程与模型调优
机器学习特征工程机器学习流程与概念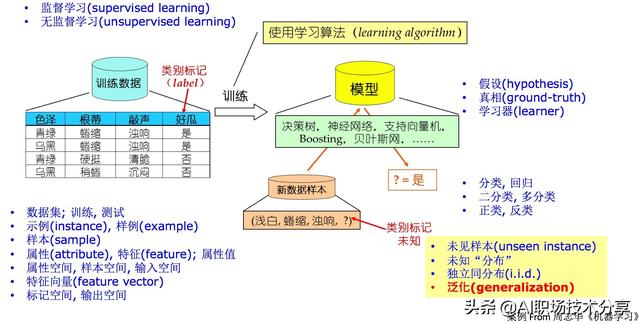 文章插图
文章插图
机器学习建模流程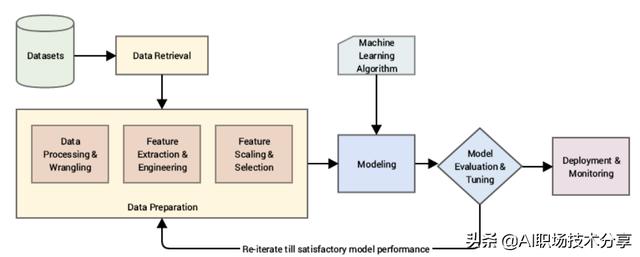 文章插图
文章插图
机器学习特征工程一览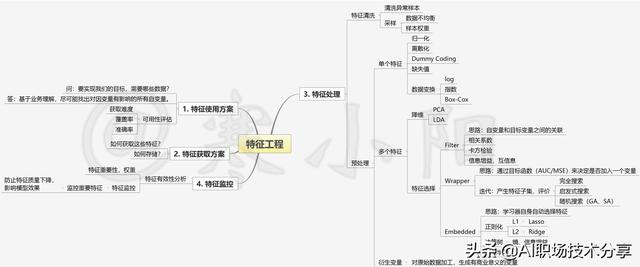 文章插图
文章插图
机器学习特征工程介绍 文章插图
文章插图
特征清洗 文章插图
文章插图
 文章插图
文章插图
 文章插图
文章插图
数值型数据上的特征工程数值型数据通常以标量的形式表示数据 , 描述观测值、记录或者测量值 。 本文的数值型数据是指连续型数据而不是离散型数据 , 表示不同类目的数据就是后者 。 数值型数据也可以用向量来表示 , 向量的每个值或分量代表一个特征 。 整数和浮点数是连续型数值数据中最常见也是最常使用的数值型数据类型 。 即使数值型数据可以直接输入到机器学习模型中 , 你仍需要在建模前设计与场景、问题和领域相关的特征 。 因此仍需要特征工程 。 让我们利用 python 来看看在数值型数据上做特征工程的一些策略 。 我们首先加载下面一些必要的依赖(通常在 Jupyterbotebook 上) 。
> import pandas as pd>> import matplotlib.pyplot as plt>> import numpy as np>> import scipy.stats as spstats>> %matplotlib inline原始度量
正如我们先前提到的 , 根据上下文和数据的格式 , 原始数值型数据通常可直接输入到机器学习模型中 。 原始的度量方法通常用数值型变量来直接表示为特征 , 而不需要任何形式的变换或特征工程 。 通常这些特征可以表示一些值或总数 。 让我们加载四个数据集之一的 Pokemon 数据集 , 该数据集也在 Kaggle 上公布了 。
poke_df = pd.read_csv('datasets/Pokemon.csv', encoding='utf-8') poke_df.head() 文章插图
文章插图
我们的Pokemon数据集截图Pokemon 是一个大型多媒体游戏 , 包含了各种口袋妖怪(Pokemon)角色 。 简而言之 , 你可以认为他们是带有超能力的动物!这些数据集由这些口袋妖怪角色构成 , 每个角色带有各种统计信息 。
数值如果你仔细地观察上图中这些数据 , 你会看到几个代表数值型原始值的属性 , 它可以被直接使用 。 下面的这行代码挑出了其中一些重点特征 。
poke_df[['HP', 'Attack', 'Defense']].head()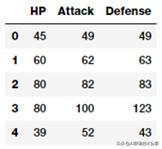 文章插图
文章插图
带(连续型)数值数据的特征这样 , 你可以直接将这些属性作为特征 , 如上图所示 。 这些特征包括 Pokemon 的 HP(血量) , Attack(攻击)和 Defense(防御)状态 。 事实上 , 我们也可以基于这些字段计算出一些基本的统计量 。
poke_df[['HP', 'Attack', 'Defense']].describe()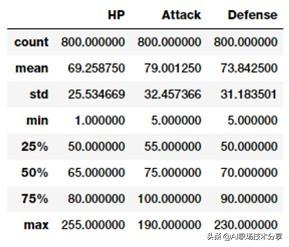 文章插图
文章插图
数值特征形式的基本描述性统计量
这样你就对特征中的统计量如总数、平均值、标准差和四分位数有了一个很好的印象 。
记数原始度量的另一种形式包括代表频率、总数或特征属性发生次数的特征 。 让我们看看 millionsong 数据集中的一个例子 , 其描述了某一歌曲被各种用户收听的总数或频数 。
- 如何进行不确定度估算:模型为何不确定以及如何估计不确定性水平
- 3分钟短文:说说Laravel模型关联关系最单纯的“一对一”
- 如何成为大数据工程师 都需要具备哪些技能
- 自用:HMM隐马尔可夫模型学习笔记(2)-前向后向算法
- 技术|大咖说|身兼工程师、创业者的青年科学家俞凯力求突破 跨界推动科研创新应用
- 腾讯游戏开发工程师:Linux 机器 CPU 毛刺问题排查
- 美国工程师:5G时代已被中国技术抢占,6G技术休想快人一步
- OpenAI推出数学推理证明模型,推理结果首次被数学家接受
- JVM 之java内存模型
- Google的神经网络表格处理模型TabNet介绍