Flink中的Fault Tolerance 容错机制( 三 )
 文章插图
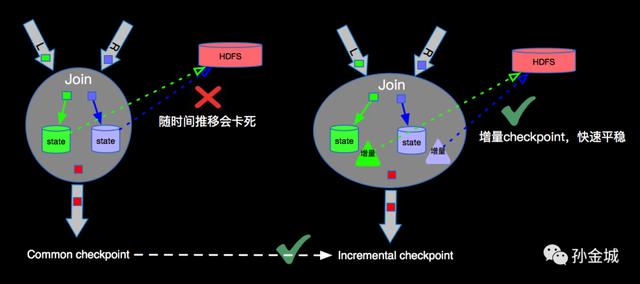
文章插图
由于流上数据源源不断 , 随着时间的增加 , 每次checkpoint产生的snapshot的文件(RocksDB的sst文件)会变的非常庞大 , 增加网络IO , 拉长checkpoint时间 , 最终导致无法完成checkpoint , 进而失去failover的能力 。 为了解决checkpoint不断变大的问题 , Flink内部实现了Incremental checkpoint , 这种增量进行checkpoint的机制 , 会大大减少checkpoint时间 , 并且如果业务数据稳定的情况下每次checkpoint的时间是相对稳定的 , 根据不同的业务需求设定checkpoint的interval , 稳定快速的进行checkpointing , 保障Flink任务在遇到故障时候可以顺利的进行failover 。 Incremental checkpoint的优化对于Flink成百上千的任务节点带来的利好不言而喻 。
端到端exactly-once根据上面的介绍我们知道Flink内部支持exactly-once , 要想达到端到端(Soruce到Sink)的exactly-once , 需要Flink外部Soruce和Sink的支持 , 比如Source要支持精准的offset , Sink要支持两阶段提交 , 也就是继承TwoPhaseCommitSinkFunction 。
Unaligned Checkpoints在Flink1.11及以后版本中 , 为了解决在特殊情况下由于barrier对齐导致的Checkpoint时间过长 , 甚至Checkpoint失败问题 , Flink提供了Unaligned checkpoins的机制 。 也就是可以将原来需要buffer的数据也存储到checkpoint的state文件中 。
最后感谢您的阅读 , 如果喜欢本文欢迎关注和转发 , 本头条号将坚持持续分享IT技术知识 。 对于文章内容有其他想法或意见建议等 , 欢迎提出共同讨论共同进步 。
本文转自:Apache Flink 漫谈系列 - Fault Tolerance
原文作者:孙金城
原文地址:
【Flink中的Fault Tolerance 容错机制】
- C++|嵌入式开发:C++中的结构与类
- |还能打翻身仗么?倪光南一语中的,联想沦落只因这个原因
- 正态|正态分布模型在体验设计中的分析及应用
- 旗舰机|面对2021年旗舰机市场中的两员“猛将”,我们该如何抉择?
- 4g手机|倘若遇见这3种情况,请马上更换手中的数据线,为了你的安全!
- 小米科技|嵌入式开发:机器学习在嵌入式系统中的应用
- 奇绩|2021年陆奇眼中的未来:“元宇宙”、“智能汽车”与中国新经济时代的主旋律
- 营销链|关于企业微信在营销链路中的定位思考
- 联想|还能打翻身仗么?倪光南一语中的,联想沦落只因这个原因
- |5000毫安+128G,千元中的小钢炮,一千出头真的香