Flink中的Fault Tolerance 容错机制( 二 )
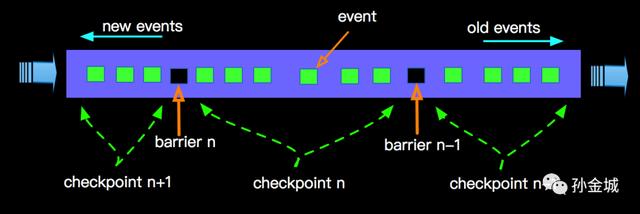
上图描述的是一个面描述 增量计算 word count的Job , 上图核心说明了如下几点:
- barrier 由source节点发出;
- barrier会将流上event切分到不同的checkpoint中;
- 汇聚到当前节点的多流的barrier要对齐;
- barrier对齐之后会进行Checkpointing , 生成snapshot;
- 完成snapshot之后向下游发出barrier , 继续直到Sink节点;
 文章插图
文章插图生成的snapshot会存储到StateBackend中 , 相关State的介绍可以查阅 《Apache Flink 漫谈系列 - State》。 这样在进行failover时候 , 从最后一次成功的checkpoint进行恢复;
Checkpointing的控制上面我们了解到整个流上面我们会随着时间推移不断的做Checkpointing , 不断的产生snapshot存储到Statebackend中 , 那么多久进行一次Checkpointing?对产生的snapshot如何持久化的呢?带着这些疑问 , 我们看看Flink对于Checkpointing如何控制的?有哪些可配置的参数:
- checkpointMode - 检查点模式 AT_LEAST_ONCE 或 EXACTLY_ONCE
- checkpointInterval - 检查点时间间隔 , 单位是毫秒
- checkpointTimeout - 检查点超时时间 ,单位毫秒
语义从语义上面exactly-once 比 at-least-once对数据处理的要求很严格 , 更精准 , 那么更高的要求就意味着更高的代价 , 这里的代价就是 延迟 。
- at-least-once - 语义是指流上所有数据至少被处理过一次(不要丢数据)
- exactly-once - 语义是指流上所有数据必须被处理且只能处理一次(不丢数据 , 且不能重复)
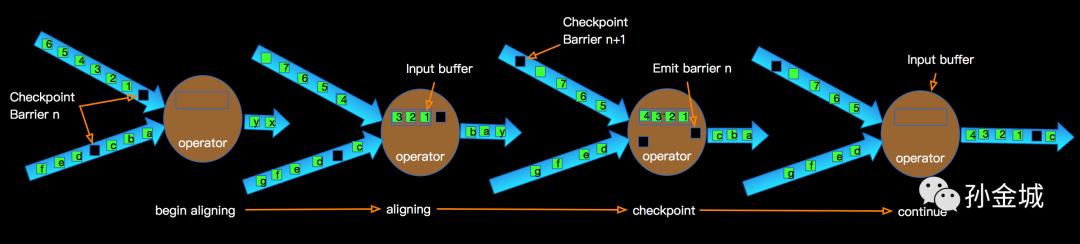
我以exactly-once为例说明exactly-once模式相对于at-least-once模式为啥会有更高的延时?如下图:
 文章插图
文章插图上图示意了某个节点进行Checkpointing的过程:
- 当Operator接收到某个上游发下来的barrier时候开始进行barrier的对齐阶段;
- 在进行对齐期间barrier之后到来的input的数据会被缓存到buffer中;
- 当Operator接收到上游所有barrier的时候 , 当前Operator会进行checkpointing , 生成snapshot并持久化;
- 当checkpointing完成时候将barrier广播给下游operator;
完整Flink任务Checkpointing过程在 《Apache Flink 漫谈系列 - State》中我们有过对Flink存储到State中的内容做过介绍 , 比如在connector会利用OperatorState记录读取位置offset , 那么一个完整的Blink任务的执行图是一个DAG , 上面我们描述了DAG中一个节点的过程 , 那么整体来看Checkpointing的过程是怎样的呢?在产生checkpoint并分布式持久到HDFS的过程是怎样的呢?
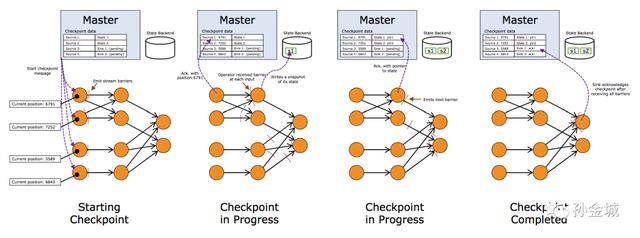
整体checkpoint流程
 文章插图
文章插图上图我们看到一个完整的Flink任务进行Checkpointing的过程 , JM触发Soruce发射barriers,当某个Operator接收到上游发下来的barrier , 开始进行barrier的处理 , 整体根据DAG自上而下的逐个节点进行Checkpointing , 并持久化到Statebackend 。 一直到DAG的sink节点 。
Incremental checkpoint对于一个流计算的任务 , 数据会源源不断的流入 , 比如要进行双流JOIN , 由于两边的流event的到来有先后顺序问题 , 我们必须将left和right的数据都会在state中进行存储 , Left event流入会在Right的State进行join数据 , Right event流入会在LState中join数据 , 如下图左右两边的数据都会持久化到State中:
- C++|嵌入式开发:C++中的结构与类
- |还能打翻身仗么?倪光南一语中的,联想沦落只因这个原因
- 正态|正态分布模型在体验设计中的分析及应用
- 旗舰机|面对2021年旗舰机市场中的两员“猛将”,我们该如何抉择?
- 4g手机|倘若遇见这3种情况,请马上更换手中的数据线,为了你的安全!
- 小米科技|嵌入式开发:机器学习在嵌入式系统中的应用
- 奇绩|2021年陆奇眼中的未来:“元宇宙”、“智能汽车”与中国新经济时代的主旋律
- 营销链|关于企业微信在营销链路中的定位思考
- 联想|还能打翻身仗么?倪光南一语中的,联想沦落只因这个原因
- |5000毫安+128G,千元中的小钢炮,一千出头真的香