Flink中的Fault Tolerance 容错机制
导读:容错(Fault Tolerance) 是指容忍故障 , 在故障发生时能够自动检测出来并使系统能够自动恢复正常运行 。 当出现某些指定的网络故障、硬件故障、软件错误时 , 系统仍能执行规定的一组程序 , 或者说程序不会因系统中的故障而中止 , 并且执行结果也不包含系统中故障所引起的差错 。
传统数据库Fault Tolerance我们在 后续会在 《流表对偶(duality)性篇》 中会介绍过mysql的主备复制机制 , 其中binlog是一个append only的日志文件 , Mysql的主备复制是高可用的主要方式 , binlog是主备复制的核心手段(当然mysql高可用细节也很复杂和多种不同的优化点 , 如 纯异步复制优化为半同步和同步复制以保证异步复制binlog导致的master和slave的同步时候网络坏掉 , 导致主备不一致问题等) 。 Mysql主备复制 , 是容错机制的一部分 , 在容错机制之中也包括事物控制 , 在传统数据库中事物可以设置不同的级别 , 以保证数据不同的质量 , 级别由低到高 如下:
- Read uncommitted - 读未提交 , 就是一个事务可以读取另一个未提交事务的数据 。 那么这种事物控制成本最低 , 但是会导致另一个事物读都时候脏数据 , 那么怎么解决读脏数据呢?利用Read committed 级别...
- Read committed - 读提交 , 就是一个事务要等另一个事务提交后才能读取数据 。 这种级别可以解决读脏数据的问题 , 那么这种级别有什么问题呢?这个级别还有一个 不能重复读的问题 , 即:开启一个读事物时候T1 , 先读取字段F1值是V1 , 这时候另一个事物T2可以UPDATA这个字段值V2 , 导致T1再次读取字段值时候获得V2了 , 同一个事物中的两次读取不一致了 。 那么如何解决不可重复读的问题呢?利用 Repeatable read 级别...
- Repeatable read - 重复读 , 就是在开始读取数据(事务开启)时 , 不再允许修改操作 。 重复读模式要有事物顺序的等待 , 需要一定的成本达到高质量的数据信息 , 那么重复读还会有什么问题吗?是的 , 重复读级别还有一个问题就是 幻读 , 幻读产生的原因是INSERT , 那么幻读怎么解决呢?利用Serializable级别...
- Serializable - 序列化 是最高的事务隔离级别 , 在该级别下 , 事务串行化顺序执行 , 可以避免脏读、不可重复读与幻读 。 但是这种事务隔离级别效率低下 , 比较耗数据库性能 , 一般不使用 。
流计算Fault Tolerance的挑战流计算Fault Tolerance的一个很大的挑战是低延迟 , 很多Flink任务都是7 x 24小时不间断 , 端到端的秒级延迟 , 要想在遇上网络闪断 , 机器坏掉等非预期的问题时候快速恢复正常 , 并且不影响计算结果正确性是一件极其困难的事情 。 同时除了流计算的低延时要求 , 还有计算模式上面的挑战 , 在Flink中支持exactly-once和at-least-once两种计算模式 , 如何做到在failover时候不重复计算精准的做到exactly-once也是流计算Fault Tolerance要重点解决的问题 。
Flink Fault Tolerance 机制Flink Fault Tolerance机制上面理论基础与flink一致都是持续创建分布式数据流及其状态的快照 。 这些快照在系统遇到故障时 , 作为一个回退点 。 Blink中创建快照的机制叫做Checkpointing , Checkpointing的理论基础 Stephan 在 Lightweight Asynchronous Snapshots for Distributed Dataflows 进行了细节描述 , 该机制源于由K. MANI CHANDY和LESLIE LAMPORT 发表的 Determining-Global-States-of-a-Distributed-System Paper , 该Paper描述了在分布式系统如何解决全局状态一致性问题 。
在Flink中以checkpointing的机制进行容错 , checkpointing会产生类似binlog一样的可以用来恢复的任务状态数据 。 Flink中也有类似于数据库事物控制(4个级别)一样的数据计算语义控制 , 在Flink中有两种语义模式设置 , 花费的成本由低到高 , 如下:
- at-least-once
- exactly-once
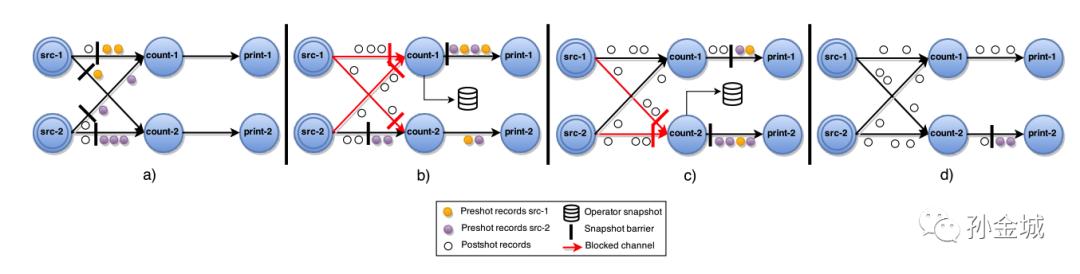 文章插图
文章插图
- C++|嵌入式开发:C++中的结构与类
- |还能打翻身仗么?倪光南一语中的,联想沦落只因这个原因
- 正态|正态分布模型在体验设计中的分析及应用
- 旗舰机|面对2021年旗舰机市场中的两员“猛将”,我们该如何抉择?
- 4g手机|倘若遇见这3种情况,请马上更换手中的数据线,为了你的安全!
- 小米科技|嵌入式开发:机器学习在嵌入式系统中的应用
- 奇绩|2021年陆奇眼中的未来:“元宇宙”、“智能汽车”与中国新经济时代的主旋律
- 营销链|关于企业微信在营销链路中的定位思考
- 联想|还能打翻身仗么?倪光南一语中的,联想沦落只因这个原因
- |5000毫安+128G,千元中的小钢炮,一千出头真的香