实时语义分割的城市场景小物体扩增( 三 )
traffic 和 motorcyclebicycle 实例的最小数量 。
4. 实验步骤A. 实验装置
训练方法:本文直接从零开始在 Cityscapes 上训练了本文的模型 , 而没有在 ImageNet 上预先训练本文的主干 NDNet45 。本文对 NDNet45-FCN8-LF 进行了总共 10 万次迭代训练 , 批处理大小为 12×1024×1024 。本文将基本学习率设置为 0.1 , 并在 35K , 60K 和 80K 迭代后将其除以 10 。
优化器和损失函数:本文使用标准的随机梯度下降(SGD)算法(动量为 0.9)训练了所有模型 。损失函数由(1)和(2)定义 。权重衰减参数设置为 0.0005 。 标准数据扩充:按照常规做法 , 本文在训练过程中采用了随机水平镜和[0.75 , 1 , 1.25 , 1.5 , 1.75 , 2]中的随机比例 。
评估协议:本文使用 mIoU 比较准确性 , 并使用 FLOP , FPS 的数量比较不同模型的效率 。 特定类别的 IoU 由下式计算: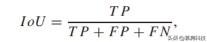 文章插图
文章插图
其中 TP , FP 和 FN 分别代表“真正” , “假正”和“假负”像素的数量 。测试集上报告的所有结果都是从在线评估服务器上获得的 , 而 val 集上的结果是通过应用 Cityscapes 作者提供的代码来计算的 。
实验环境:本文在配备 Intel Xeon E5-1630(8 核 , 3.7 GHz)CPU , Titan X(12G)GPU 和 32G RAM 的计算机上进行了所有实验 。本文使用 Pytorch 深度学习库训练了模型 。
B. NDNet 上的实验
有效性验证:通过将其与流行的 ResNet 中效率最高的网络 ResNet18 进行比较 , 本文展示了骨干网络 NDNet45 的有效性 。 为了实现这一目标 , 本文将其转换为 FCN32 分段架构 , 并使用 OC 对其进行了培训 。 表二表明 , 与 ResNet18 相比 , 本文的 NDNet45 的 FLOP 减少了 36 倍以上 , 而 ResNet18 的分辨率是在 1024×2048 分辨率的图像上进行评估的 。 此外 , 请注意 , 本文的网络参数减少了 31 倍以上 。 为了进一步验证模型的有效性 , 本文还比较了 NDNet45 和 MobileNetV2 。 特别是 , 本文修改了 MobileNetV2 的宽度和深度 , 以使其共享与 NDNet45 类似的 FLOP 。 本文已经发布了免费提供的截短的 MobileNetV21 模型 。 如表二所示 , 与 MobileNetV2 相比 , NDNet45 具有更少的参数和更好的 mIoU , 并且具有相似的计算成本 。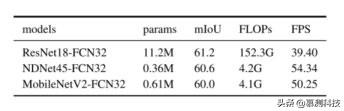 文章插图
文章插图
表 2:NDNET45 , RESNET18 和截断的 MOBILENETV2 的比较
关于学习融合的消融研究:本文在不使用学习分数融合的情况下实施了基本的 NDNet45-FCN8 , 并以此为基线 。 在 8.4G FLOP 的 Cityscapes 验证数据集上 , 本文的基准达到了 64.0%的 mIoU 。 接下来 , 本文将学习的分数融合应用于基线 。 但是 , 学习型融合(LF)并不能改善基线的性能 , 但会产生较差的结果 。 这主要是因为联合学习融合权重和分割模型可能导致次优融合权重 。 因此 , 本文向密集的预测层添加了辅助损耗 。 这本质上具有使融合和分割的学习脱钩的效果 , 并且有望大大提高 NDNet45-FCN8-LF 的性能 。 由于块 4 和 5 的输出步幅分别为 16 和 32 , 因此本文将附加到这两个块的辅助损耗表示为 auloss16 和 auloss32 。 表 III 显示 , 使用 auloss16 , NDNet45-FCN8-LF 的性能从 63.2%提高到 64.3% , 添加 auloss32 之后 , 性能进一步提高到 64.6% 。 但是 , 将 auloss16 添加到基线会使结果恶化 , 并且同时添加 auloss16 和 auloss32 只会带来很小的收益 。 本文将 FCN8 的三个预测分支分别称为 pred8 , pred16 和 pred32 。 为了分析辅助损失如何影响本文模型的结果 , 本文直接从三个预测分支(参见图 3)进行了细分 , 然后分别评估了它们的性能 。 从表 III 中可以看出 , 对于基本的 FCN8 模型 , 在添加 auloss16 之后 , pred16 取代了 pred32 作为主要的预测分支(具有最佳的 mIoU) 。 特别是 , 仅添加 auloss16 显着改善了 pred16 的性能(从 29.7%降至 46.4%) , 同时使 pred32 的性能降低了近 10 个百分点 。 这是合理的 , 因为大部分损失来自 pred16 。 因此 , 将 auloss16 添加到基线(在 pred32 起主要作用的位置)会产生较差的结果 , 这是由于 pred16 的较小接收场导致的上下文丢失 。 相反 , 本文学习到的融合仍然可以通过加权融合期间更高的预测来确保 pred32 的稳定性能 。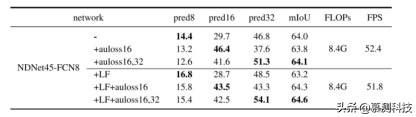 文章插图
文章插图
表 3:有无辅助性损失的融合术的消融实验
通用性验证:本文将本文的模型与 Camvid 数据集上的四个实时模型 SegNet , ENet , LinkNet 和 ESPNet 进行了比较 , 以证明 NDNetFCN8-LF 的通用性 。Camvid 是最早了解街景的数据集之一 。 它具有 11 个用于语义分割的类 , 以及 367、101 和 233 个图像 , 分别用于训练 , 验证和测试 。 原始图像的分辨率为 960×720 。 本文采用与这些比较方法类似的方法 , 对图像进行了 2 倍下采样 , 以进行公平比较 。 请注意 , ESPNet 的性能是由作者在其发布的代码中报告的 。 本文以批处理大小 32×360×480 的模型训练了 30K 步的模型 。 学习率设置为 0.1 , 然后以 7K , 15K 和 20K 步除以 10 。 所有其他设置与第 V-A 节中提到的设置相同 。 结果列于表 4 , 其中使用 SegNet 作者提供的 code3 计算每个类别和 mIoU 的准确性 。 可以看出 , 本文的方法优于所有比较方法 。 与 ENet 相比 , 本文的模型在六个类别(建筑物 , 树木 , 汽车 , 道路 , 人行道和骑自行车的人)上获得了更好的 mIoU , 并且在 mIoU 上提高了 6.2% 。 与 SegNet 相比 , 本文在标志牌 , 行人 , 汽车 , 道路 , 人行道 , 自行车手和 mIoU 上取得了更好的结果 。 图 5 显示了本文的模型与 SegNet 之间的定性比较 。 可以看出 , ENet , SegNet 和本文的方法在小物体上的表现较差 , 这是本文提出的小物体增强的动机 。 但是 , 如表 IV 所示 , 当将建议的小物体(标志 , 杆 , 行人和自行车)应用到 Camvid 时 , 本文的模型仅获得了较小的改进 。 这主要是因为许多 Camvid 训练图像包含一个或多个相同姿势的不同物体 。 结果 , 在小物体提取阶段重复提取了许多物体 , 这大大降低了小物体数据集的多样性 , 从而降低了数据扩增的性能 。 考虑到 Camvid 的训练图像数量少 , 这种退化可以进一步扩大 。 因此 , 接下来本文在 Cityscapes 数据集上验证了小物体增强的有效性 。
- linux配置nginx定时日志分割
- 实时性能和健康监测工具:Netdata 1.26.0 发布
- 你喜欢的 Go 第三方库:一步为系统集成可视化实时运行时统计
- 网易云音乐基于Flink实时数仓实践
- 交通运输局|实时信息一键可得!车辆有了这个“智能锁”厉害了!
- 「数量技术宅|Python爬虫系列」实时监控股市公告的爬虫
- 类别|如何用PyTorch进行语义分割?一个教程教会你
- 导出|淘宝商家电话采集软件实时采集卖家电话
- 基于学习转换的一次性医学图像分割中的数据扩增
- 看护|小白智能看护灯正式亮相 支持一键呼叫实时视频亮了