实时语义分割的城市场景小物体扩增( 二 )
但是 , 基于重要的观察结果直接对从不同阶段获得的预测分数求和是次优的:不同阶段的特征对于预测不同类别可能是最佳的 。 特别是 , 下级的输出适用于可以被较小的接收场覆盖的小型物体 。 相反 , 对于不能通过局部特征很好地区分的大型物体类 , 较高的级输出更好的表示 。换句话说 , 最好将 FCN8 的三个预测分支之一作为特定类的主要分支 。因此 , 本文建议对 FCN8 的三个预测执行加权和 。 因此 , 可以将上述方程式转换为以下方程式: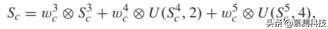 文章插图
文章插图 文章插图
文章插图
C. 深度监督
为了使 FCN8 的三级预测尽可能准确 , 本文将深度监督纳入训练损失函数的设计中 。 本文添加了辅助损耗以监督第 4 阶段和第 5 阶段的预测 。 本文将辅助损耗乘以权重因子 α , 并将其设置为与 PSPNet 相似的 0.4 。 因此 , 损失函数为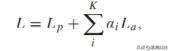 文章插图
文章插图
(1)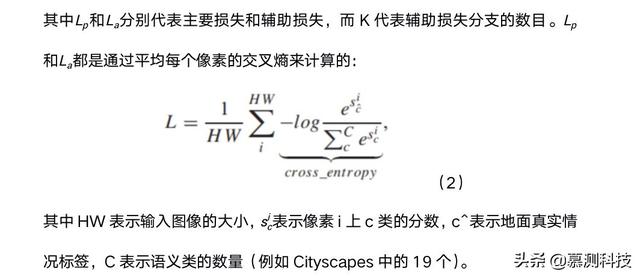 文章插图
文章插图
3. 增强小物体本节首先介绍有关街道场景的重要观察结果 , 这激发了本文对小物体增强的想法 。然后 , 本文描述如何向现有的名为 Cityscapes 的数据集中添加更多小物体 。
A. 动机
因为扩充数据集不会增加计算量 , 而且之前也有研究表示 , 扩充更多的数据 , 效果也不一定比改进网络来的少 。 该观点激发了本文提出的剪切粘贴小物体增强的提议 。 首先 , 街道场景数据集的图像可以包含该数据集的所有语义类别 , 这些语义类别与一般的语义分割数据集不同 , 本文可以将街道场景的物体添加到街道场景数据集的任何图像中 , 而无需考虑场景类型的先验 。 其次 , 许多街道场景图像包含大范围的非物体类 , 例如道路和人行道(见图 4) 。 由于空白区域是物体通常出现的位置 , 因此直观地将更多小物体粘贴在这些区域上以执行数据扩增 。 对于此粘贴过程 , 本文需要从同一数据集中收集许多小物体实例 。
B. 小物件的集合
作者定义的小物件:电线杆 , 交通信号灯 , 交通标志 , 骑手 , 摩托车和自行车 。
驾驶场景的重要属性:本文根据驾驶场景的以下三个重要属性提取小物件 。
- 驾驶场景是以自我为中心的 , 即 , 物体离摄像机越近 , 它出现的越大 。 因此 , 本文将物体到相机的距离分为三个级别:far , medium_far 和 near 。
- 左侧和右侧物体之间存在差异 , 尤其是在给定左侧和右侧驱动国家的情况下 。 因此 , 本文进一步将小物体分为左物体和右物体 。
- 交通信号灯和交通标志通常放置在电线杆上 。
以 pole_traffic 为例 , 介绍小物体提取流程 。 如图 4 所示 , 小物件提取流程可分为三个阶段:
1)poletraffic 的分割:由于训练集中的每个图像都与像素级标签图像相关联 , 因此通过处理 , 可以很容易地实现 poletraffic 分割 pole_traffic 的像素为前景像素 , 所有其他像素为背景;
2)实例分割:可以通过从二进制 poletraffic 分割结果中找到标签连接的组件来区分 poletraffic 的不同实例;
3)实例分类:根据实例的位置将提取的实例分类为上述各种子集 。
 文章插图
文章插图图 4:小物体提取的流程和合成图像的示例 。
D. 小物件的放置
本节介绍如何在 2975 个城市景观的训练图像中插入其他小物体 。
先验上下文:本文考虑了在道路行驶场景中存在的两个重要的先验条件 , 以实现本文在放置小物体时的目标:
1)经常在人行道上找到 pole_traffic 。
2)骑摩托车的人通常在马路上 , 而没有骑摩托车的人通常在人行道上
物体放置:首先 , 本文根据上述两个上下文先验从人行道或道路上随机选择一个位置来放置小物体 。 本文观察到这种随机机制很容易导致小物体重叠 。 尽管在 2D 图像中遮挡是自然的 , 但是放置的小物体之间的重叠会产生伪影(请参见图 5 中的 SC2) , 因为这些小物体具有各种姿势 , 形状和方向 。 因此 , 本文反复选择位置以确保有足够的空间放置物体 。 根据选择的位置(例如 , 远或近 , 左或右) , 从本文的小物体数据集的相应子集中随机采样放置的小物体 。 由于某些原始图像中可能已经存在许多小物体实例 , 因此本文将 8 和 5 分别设置为每个合成图像的 pole
- linux配置nginx定时日志分割
- 实时性能和健康监测工具:Netdata 1.26.0 发布
- 你喜欢的 Go 第三方库:一步为系统集成可视化实时运行时统计
- 网易云音乐基于Flink实时数仓实践
- 交通运输局|实时信息一键可得!车辆有了这个“智能锁”厉害了!
- 「数量技术宅|Python爬虫系列」实时监控股市公告的爬虫
- 类别|如何用PyTorch进行语义分割?一个教程教会你
- 导出|淘宝商家电话采集软件实时采集卖家电话
- 基于学习转换的一次性医学图像分割中的数据扩增
- 看护|小白智能看护灯正式亮相 支持一键呼叫实时视频亮了