网易云音乐基于Flink实时数仓实践
本次ITPUB技术栈线上沙龙2020上 , 网易云音乐Flink 提供SQL和SDK给用户使用;端到端血缘收集;数据源和任务监控完善 。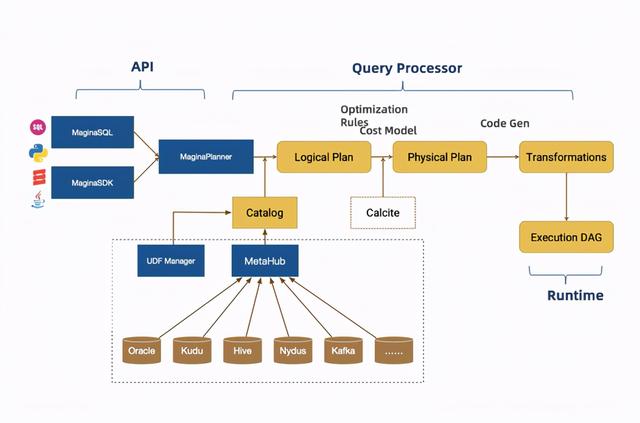 文章插图
文章插图
▲实时数仓的架构图
从最源头开始看实时数仓的架构图 , SQL和SDK作为输入 , 直接去走Planner 。 Planner和SQL打通 , 可以解析整体的SQL语句 。 接下来 , 会有一个Catalog的注入 , 它接的是MetaHub(云数据中心) 。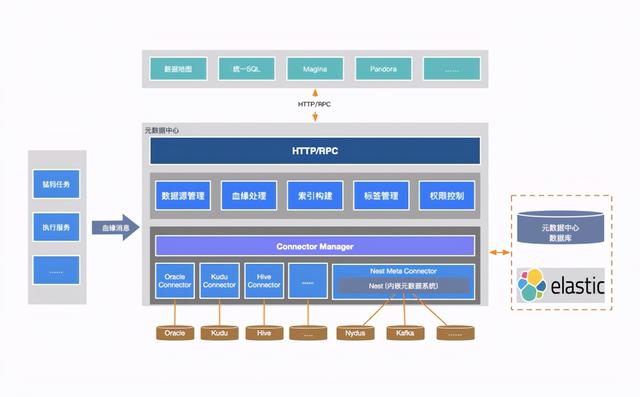 文章插图
文章插图
所有的元数据都被管控起来 , 就形成了一个系统 , 也就是元数据中心 。 它可以管理所有存在元数据系统的存储 , 并具备独立模块管理MQ元数据、插拔式元数据管理、统一数据类型、元数据检索等功能 。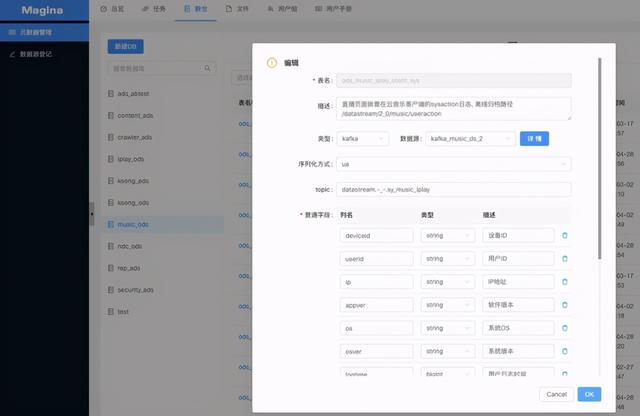 文章插图
文章插图
数仓建设分为三个部分:统一表表示格式 (catalog.db.table) 、数仓分层 , 以及表权限管理 。 在做实时数仓时 , 我们完全以现有离线的数仓模式 , 复制出来一个实时数仓的表 。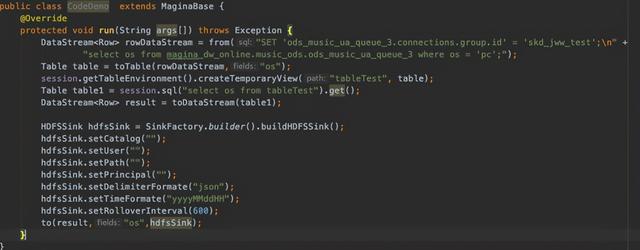 文章插图
文章插图
SDK提供封装内部SQL执行逻辑 , 简易的API , 以及数据血缘收集 。 上图是用SDK做的一个DEMO , 这是真实的一个业务代码 。 之前是用了将近190多行代码去实现的 , 在封装之后总体不过十几行代码 , 方便用户使用 。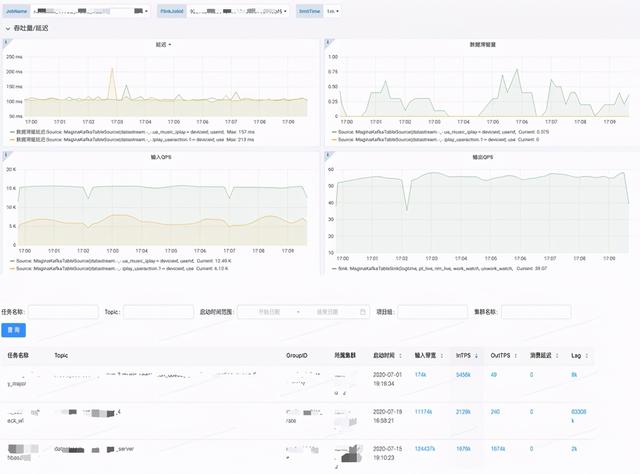 文章插图
文章插图
从数据、数据源、数据写出 , 我们均提供细粒度任务级别指标监控和MQ数据量监控 。 李涵淼认为 , “当平台做到一定程度的时候 , 这种集群级别的监控是必不可少的 。 监控做的完善 , 对平台是一个很好的补充 。 ”
三、实时数仓实践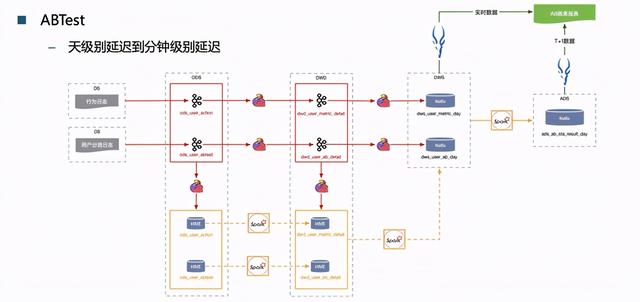 文章插图
文章插图
实时数仓第一个很典型的实践就是ABTest , 把原始数据存到HIVE里面去 , 再用Spark做清洗和聚合 , 然后再输到上层的表里 。 值得注意的是 , 实时数仓和离线数仓的分层 , 其实是一致的 。
实时数仓版ABTest摆脱了之前HIVE+Spark的处理模式 , 应用效果非常好 。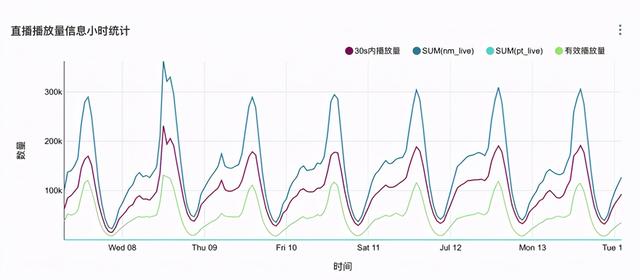 文章插图
文章插图
实时数仓第二个典型的实践是实时报表 , 如上图所示 , 网易云音乐直播播放量的统计表格 。 实时报表建立任务更容易 , 数据问题定位更清晰 。
第三个典型的实践是实时特征 , 具备特征复用和特征血缘展示 。 我们做过一个统计 , 各个算法团队做出来的任务 , 输出的特征很多都是重复的 , 这无形中就造成了资源的浪费 , 增加了团队开发的成本 。
实时数仓对特征做了分层 , 所有的表根据业务做了隔离 , 并全部统一起来 。 算法团队如果想用一些特征的话 , 他可以直接在平台上搜索相关特征 , 然后根据其中包含的信息 , 做进一步的操作 。
【网易云音乐基于Flink实时数仓实践】来自 “ ITPUB博客 ”, 链接: , 如需转
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 平台|Win平台上的本地音乐管理软件,MusicBee
- 建设|《青岛市城市云脑建设指引》发布
- 蓝海|背靠万亿美元市场,老年人会是音乐产业的新蓝海吗?
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐
- 服务平台|HashiCorp发布多云服务平台Consul 1.9版
- 市占率不足2%,虾米音乐还能听多久?|数据 | 虾米
- 物种|苏宁易购赋能落地“新物种”旗下云网万店A轮融资60亿
- 电商|直播电商风云巨变,新一波红利路在何方?
- 首创|网易有道词典笔3发布:首创毫秒级超快点查、识别率超98%