实时语义分割的城市场景小物体扩增
摘要:语义分割是自动驾驶场景理解中的关键步骤 。 尽管深度学习已显著提高了分割精度 , 但由于当前的高质量模型架构复杂且依赖于多尺度输入 , 因此效率低下 。 因此 , 很难将它们应用于实时或实际应用 。 另一方面 , 实时性较好的方法仍无法在交通信号灯等小物体上产生令人满意的结果 , 这对自动驾驶来说 , 对安全性有很大的威胁 。 本文从两个方面提高了实时语义分割的性能和数据 。 具体来说 , 本文提出了一种由 Neep Deep Network(NDNet)创建的实时分割模型 , 并通过将其他小物体插入训练图像中来构建合成数据集 。 该方法在 1024×2048 输入上仅 8.4G 浮点运算(FLOP)即可在 Cityscapes 测试集上实现 65.7%的平均相交度(mIoU) 。 此外 , 通过在合成数据集上对现有的 PSPNet 和 DeepLabV3 模型进行重新训练 , 本文在小物体上的平均 mIoU 提高了 2% 。
1. 主要贡献在本文中 , 本文旨在进一步提高实时语义分割的效率 , 同时确保对小物体的高精度分割 。 本文从方法论和数据角度都解决了这个具有挑战性的问题(见图 1) 。 从方法论的角度来看 , 本文通过堆叠两个深度可分离的卷积(每个卷积具有 1×1 的卷积)以首先缩小然后恢复特征尺寸来开发瓶颈结构 。 瓶颈结构在不增加参数数量的情况下增加了网络的深度 。 利用此特性 , 本文使用提出的瓶颈结构设计 NDNet 进行实时特征提取 。 从数据的角度出发 , 受合成物体检测数据集的最新成功以及许多街道图像没有小物体的启发 , 本文建议增加通过在原始图像中插入其他小物体来训练数据 。 本文的主要贡献概述如下:
1) 本文提出了 NDNet45 这一实时网络 , 该网络使用基于卷积的可分离瓶颈结构 。 然后 , 本文将 NDNet45 修改为具有学习分数融合的改进的全卷积网络 8(FCN8)结构 , 并在 8.4G FLOP 的 Cityscapes 测试集上实现了 65.7%的平均相交联盟(mIoU)准确性 , 在效率上明显优于最新的实时性好的方法 。
2) 本文为增强街道场景的小物体 , 开发了剪切和粘贴策略 。 如图 1 所示 , 本文首先从原始的 Cityscapes(OC)数据集中剪切了许多小物体 , 然后通过在原始训练图像中插入其他小物体来生成合成的 Cityscapes(SC)数据集 。
3) 本文的研究显示 , 使用本文的 SC 数据集进行训练可以显着改善小物体的分割 , 同时对于实时模型 , 大物体的分割性能几乎保持不变 。 特别是 , 通过使用 SC 数据集训练 NDNet45-FCN8 , 本文在小物体上的 mIoU 改善了 2.2% 。使用本文的 SC 数据集进行训练 , 对于现有最先进的方法 , 即金字塔场景解析网络(PSPNet)和 DeepLabV3 , 本文还可以在小物体上获得平均 2%的 mIoU 改善 。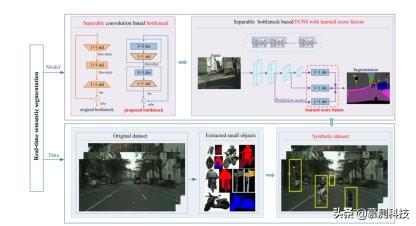 文章插图
文章插图
图 1:关于本文的模型和数据驱动的实时语义分割的概述
2. 实时分割架构尽管深度可分离卷积大大降低了深度学习的计算成本 , 但考虑到标准卷积的巨大基数 , 仍有很大的空间可以进一步提高效率 。 在本节中 , 本文描述如何将可分解卷积合并到瓶颈结构中以提高深度学习的效率 。
A. 实时特征提取 文章插图
文章插图
本文基于残差层设计了一个实时特征提取网络 。根据功能分辨率 , 本文将提议的网络分为五个部分 。前两个块通过 3×3 卷积层和最大池化层简单堆叠 , 以快速降低输入分辨率 。 其余三个块是通过堆叠许多剩余层构成的 。表 1 列出了本文网络的详细架构 , 其中缩写 std , dw , pw 和 conv 分别表示标准 , 深度 , 逐点和卷积 。 本文将其称为骨干网络 NDNet45 , 因为它采用窄而深的结构并具有 45 个卷积层 。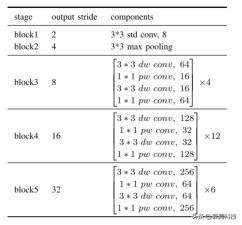 文章插图
文章插图
表 1:NDNet45 的结构
【实时语义分割的城市场景小物体扩增】B. 实时分割网络
本文的实时分割网络的概述如图 3 所示 。 通过对最终特征图进行密集的预测 , 本文的 NDNet45 可以轻松地转换为 FCN32 结构进行语义分割 。 但是 , FCN32 无法捕获足够的空间细节以恢复物体之间的边界 。 因此 , 本文将 NDNet45 调整为 FCN8 结构以进行语义分割 。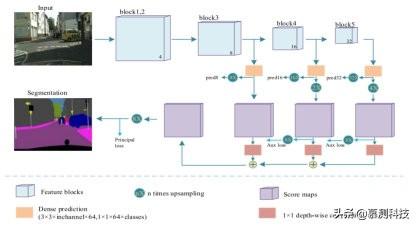 文章插图
文章插图
图 3:基于 NDNet 的 FCN8 的体系结构 文章插图
文章插图
其中 U(x,i)表示速率为 i 的上采样 。
- linux配置nginx定时日志分割
- 实时性能和健康监测工具:Netdata 1.26.0 发布
- 你喜欢的 Go 第三方库:一步为系统集成可视化实时运行时统计
- 网易云音乐基于Flink实时数仓实践
- 交通运输局|实时信息一键可得!车辆有了这个“智能锁”厉害了!
- 「数量技术宅|Python爬虫系列」实时监控股市公告的爬虫
- 类别|如何用PyTorch进行语义分割?一个教程教会你
- 导出|淘宝商家电话采集软件实时采集卖家电话
- 基于学习转换的一次性医学图像分割中的数据扩增
- 看护|小白智能看护灯正式亮相 支持一键呼叫实时视频亮了