Read文件一个字节实际会发生多大的磁盘IO?
作者:yanfei
【Read文件一个字节实际会发生多大的磁盘IO?】出处:
先讲一个作者大约7年前我在某当时很火的一个应用分发创业公司的面试小插曲 , 该公司安排了一个刚工作1年多的一个同学来面我 , 聊到我们项目中的配置文件里写的一个开关 , 这位同学就跳出来说 , 你这个读文件啦 , 每个用户请求来了还得多一次的磁盘IO , 性能肯定差 。 借由这个故事其实我发现了一个问题 , 虽然我们中的大部分人都是计算机科班出身 , 代码也写的很遛 。 但是在一些看似司空见惯的问题上 , 我们中的绝大多数人并没有真正理解 , 或者理解的不够透彻 。
不管你用的是啥语言 , C/PHP/GO、还是Java , 相信大家都有过读取文件的经历 。 我们来思考两个问题 , 如果我们读取文件中的一个字节:
- 是否会发生磁盘IO?
- 发生的话 , Linux实际向磁盘读取多少字节了呢?
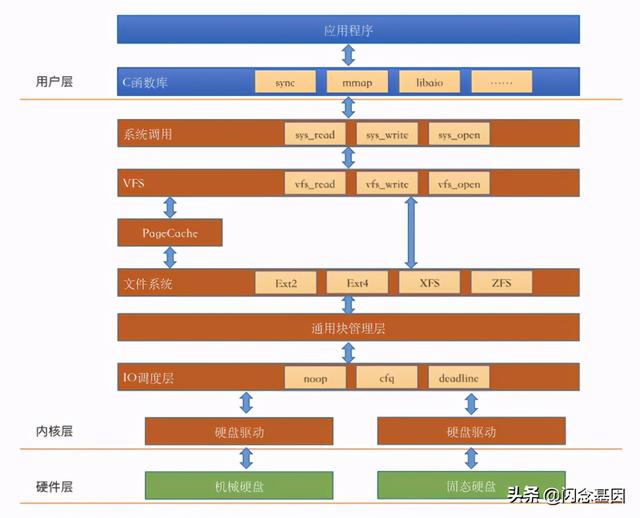
int main(){charc;intin;in = open("in.txt", O_RDONLY);read(in,return 0;}如果不是从事c/c++开发工作的同学 , 这个问题想深度理解起来确实不那么容易 。 因为目前常用的主流语言 , PHP/Java/Go啥的封装层次都比较高 , 把内核的很多细节都给屏蔽的比较彻底 。 要想把上面的两个问题搞的比较清楚 , 需要剖开Linux的内部来理解Linux的IO栈 。Linux IO栈简介废话不多说 , 我们直接把Linux IO栈的一个简化版本画出来:(官方的IO栈参考这个 Linux.IO.stack_v1.0.pdf )
 文章插图
文章插图我们在前面也分享了几篇文章讨论了上图图中的硬件层 , 还有文件系统模块 。 但通过这个IO栈我们发现 , 我们对Linux文件的IO的理解还是远远不够 , 还有好几个内核组件:IO引擎、VFS、PageCache、通用块管理层、IO调度层等模块我们并没有了解太多 。 别着急 , 让我们一一道来:
IO引擎我们开发同学想要读写文件的话 , 在lib库层有很多种函数可以选择 , 比如read , write , mmap等 。 这事实上就是在选择Linux提供的IO引擎 。 我们最常用的read、write函数是属于sync引擎 , 除了sync , 还有map、psync、vsync、libaio、posixaio等 。sync , psync都属于同步方式 , libaio和posixaio属于异步IO 。
当然了IO引擎也需要VFS、通用块层等更底层的支持才能实现 。 在sync引擎的read函数里会进入VFS提供的read系统调用 。
VFS虚拟文件系统在内核层 , 第一个看到的是VFS 。 VFS诞生的思想是抽象一个通用的文件系统模型 , 对我们开发人员或者是用户提供一组通用的接口 , 让我们不用care具体文件系统的实现 。 VFS提供的核心数据结构有四个 , 它们定义在内核源代码的include/linux/fs.h和include/linux/dcache.h中 。
- superblock:Linux用来标注具体已安装的文件系统的有关信息
- inode:Linux中的每一个文件都有一个inode , 你可以把inode理解为文件的身份证
- file:内存中的文件对象 , 用来保存进程和磁盘文件的对应关系
- desty:目录项 , 是路径中的一部分 , 所有的目录项对象串起来就是一棵Linux下的目录树 。
struct inode_operations {......int (*link) (struct dentry *,struct inode *,struct dentry *);int (*unlink) (struct inode *,struct dentry *);int (*mkdir) (struct inode *,struct dentry *,umode_t);int (*rmdir) (struct inode *,struct dentry *);int (*rename) (struct inode *, struct dentry *,struct inode *, struct dentry *, unsigned int);......在file对应的操作方法 file_operations 里面定义了我们经常使用的read和write:struct file_operations {......ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);......int (*mmap) (struct file *, struct vm_area_struct *);int (*open) (struct inode *, struct file *);int (*flush) (struct file *, fl_owner_t id);Page Cache在VFS层往下看 , 我们注意到了Page Cache 。 它的中文译名叫页高速缓存 , 是Linux内核使用的主要磁盘高速缓存 , 是一个纯内存的工作组件 , 其作用就是来给访问相对比较慢的磁盘来进行访问加速 。 如果要访问的文件block正好存在于Page Cache内 , 那么并不会有实际的磁盘IO发生 。 如果不存在 , 那么会申请一个新页 , 发出缺页中断 , 然后用磁盘读取到的block内容来填充它, 下次直接使用 。 Linux内核使用搜索树来高效管理大量的页面 。
- 车企|华为不造车!但任正非加了一个有效期,3年
- 同轴心配合|用SolidWorks画一个直角传动,画四个零件就行
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 发展|新基建发展迅猛,必然会是一个巨大的市场机遇
- 恢复|电脑文件不小心被删除了怎么恢复?文件恢复可以用这招解决!
- 缺点|骁龙865+12GB已降至2399,X轴马达+55W快充,缺点只有一个
- 空间|垃圾文件正在吞噬你的C盘空间用这四种方法,还你一个干净的C盘
- 商业|AC有望建立一个商业帝国吗?
- 中国汽车|2020年,我们攒了一个局,串了一条链,下了一盘棋