后端程序员书写高质量SQL的30条建议( 四 )
因为exists查询的理解就是 , 先执行主查询 , 获得数据后 , 再放到子查询中做条件验证 , 根据验证结果(true或者false) , 来决定主查询的数据结果是否得意保留 。
那么 , 这样写就等价于:
select * from A,先从A表做循环
select * from B where A.deptId = B.deptId,再从B表做循环.
同理 , 可以抽象成这样一个循环:
List <> resultSet ;
for ( int i = 0 ; i < A.length; i ++) {
for(int j = 0 ;j if( A [i].deptId == B[ j ].deptId) {
resultSet.add(A[i]);
break;
}
}
}
数据库最费劲的就是跟程序链接释放 。 假设链接了两次 , 每次做上百万次的数据集查询 , 查完就走 , 这样就只做了两次;相反建立了上百万次链接 , 申请链接释放反复重复 , 这样系统就受不了了 。 即mysql优化原则 , 就是小表驱动大表 , 小的数据集驱动大的数据集 , 从而让性能更优 。
因此 , 我们要选择最外层循环小的 , 也就是 , 如果B的数据量小于A , 适合使用in , 如果B的数据量大于A , 即适合选择exist 。
21、尽量用union all替换 union 。
如果检索结果中不会有重复的记录 , 推荐union all 替换 union 。
反例:
select from user where userid = 1
union
select * from user where age = 10
正例:
select * from user where userid =1
union all
select *from user where age =10
理由:如果使用union , 不管检索结果有没有重复 , 都会尝试进行合并 , 然后在输出最终结果前进行排序 。 如果已知检索结果没有重复记录 , 使用union all 代替union , 这样会提高效率 。
22、索引不宜太多 , 一般5个以内 。
- 索引并不是越多越好 , 索引虽然提高了查询的效率 , 但是也降低了插入和更新的效率;
- insert或update时有可能会重建索引 , 所以建索引需要慎重考虑 , 视具体情况来定;
- 一个表的索引数最好不要超过5个 , 若太多需要考虑一些索引是否没有存在的必要 。
反例:
`king_id` varchar(20) NOT COMMENT '守护者Id'
正例:
`king_id` int(11) NOT COMMENT '守护者Id'
理由:相对于数字型字段 , 字符型会降低查询和连接的性能 , 并会增加存储开销 。
24、索引不适合建在有大量重复数据的字段上 , 如性别这类型数据库字段 。
因为SQL优化器是根据表中数据量来进行查询优化的 , 如果索引列有大量重复数据 , Mysql查询优化器推算发现不走索引的成本更低 , 很可能就放弃索引了 。
25、尽量避免向客户端返回过多数据量 。
假设业务需求是 , 用户请求查看自己最近一年观看过的直播数据 。
反例:
//一次性查询所有数据回来
select * from LivingInfo where watchId = useId and watchTime >= Date_sub ( now, Interval 1 Y )
正例:
//分页查询
select * from LivingInfo where watchId = useId and watchTime >= Date_sub ( now, Interval 1 Y ) limit offset , pageSize
//如果是前端分页 , 可以先查询前两百条记录 , 因为一般用户应该也不会往下翻太多页
select * from LivingInfo where watchId = useId and watchTime>= Date_sub ( now, Interval 1 Y) limit 200;
26、当在SQL语句中连接多个表时,请使用表的别名 , 并把别名前缀于每一列上 , 这样语义更加清晰 。
反例:
select * from A inner
join B on A.deptId = B.deptId;
正例:
select memeber.name,deptment.deptName from A member inner
join B deptment on member.deptId = deptment.deptId;
27、尽可能使用varchar/nvarchar 代替 char/nchar 。
反例:
`deptName` char (100) DEFAULT COMMENT '部门名称'
正例:
`deptName` varchar (100 ) DEFAULT COMMENT '部门名称'
理由:因为首先变长字段存储空间小 , 可以节省存储空间 。 其次对于查询来说 , 在一个相对较小的字段内搜索 , 效率更高 。
28、为了提高group by 语句的效率 , 可以在执行到该语句前 , 把不需要的记录过滤掉 。
反例:
select job , avg(salary)from employee group by job having job ='president'
or job = 'managent'
正例:
select job , avg(salary)from employee where job ='president'
or job = 'managent' group by job;
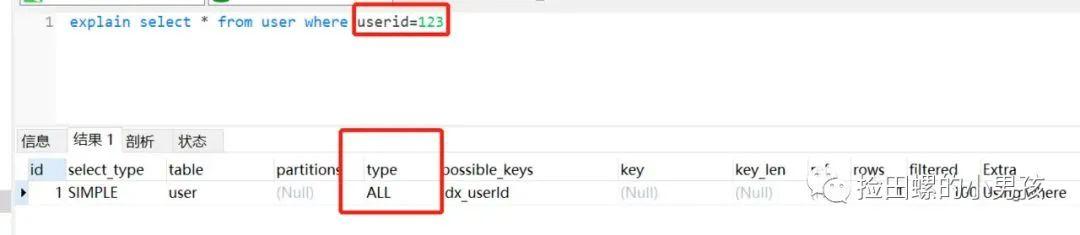
29、如果字段类型是字符串 , where时一定用引号括起来 , 否则索引失效 。
反例:
select * from user where userid = 123 ;
 文章插图
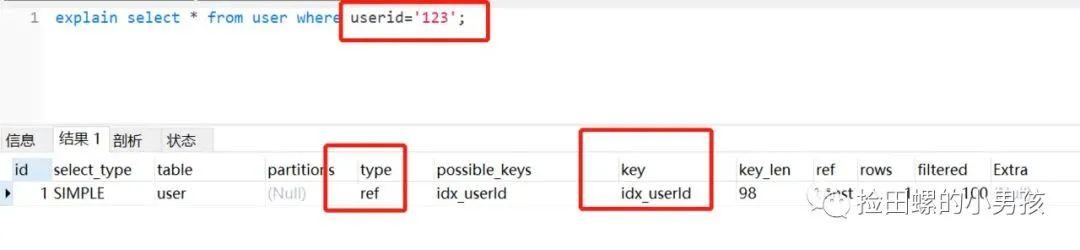
文章插图正例:
select * from user where userid = '123' ;
 文章插图
文章插图
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 联网时代|34岁转行做程序员是否还有成功的机会
- 检查|填补软件开发市场空白,飞算全自动软件工程平台瞄准全自动后端微服务开发
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 这些错误,程序员经常会犯,你了解过吗?
- 程序员面试主要看哪些 该怎么准备面试内容
- 中国程序员最容易发音错误的单词,看看你有没有读错
- 程序员大佬整理的300本编程电子书,整整12个G你想学的都有
- Rust能不能做后端开发语言?
- 程序员年包90w,回老家被月薪3800表哥怼,催他赶紧上岸