后端程序员书写高质量SQL的30条建议( 三 )
 文章插图
文章插图
13、如果插入数据过多 , 考虑批量插入 。
反例:
for(User u :list){
INSERT into user(name,age) values(#name#,#age#)
}
正例:
//一次500批量插入 , 分批进行
insert into user(name,age) values<
foreach collection="list" item="item" index="index" separator=",">
(#{item.name},#{item.age})
理由:批量插入性能好 , 更加省时间 。
打个比喻:假如你需要搬一万块砖到楼顶,你有一个电梯,电梯一次可以放适量的砖(最多放500),你可以选择一次运送一块砖,也可以一次运送500块砖,你觉得哪个时间消耗大?
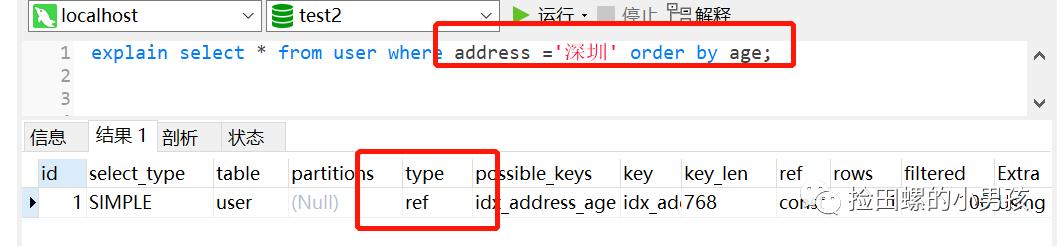
14、在适当的时候 , 使用覆盖索引 。
覆盖索引能够使得你的SQL语句不需要回表 , 仅仅访问索引就能够得到所有需要的数据 , 大大提高了查询效率 。
反例:
// like模糊查询 , 不走索引了
select * from user where userid like '%123%'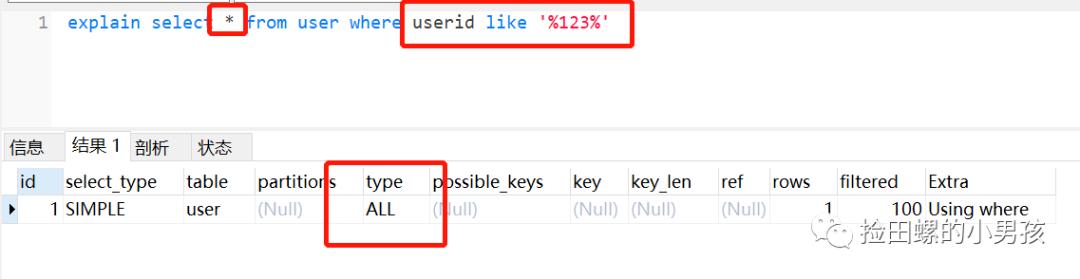 文章插图
文章插图
正例:
//id为主键 , 那么为普通索引 , 即覆盖索引登场了 。
select id,name from user where userid like '%123%';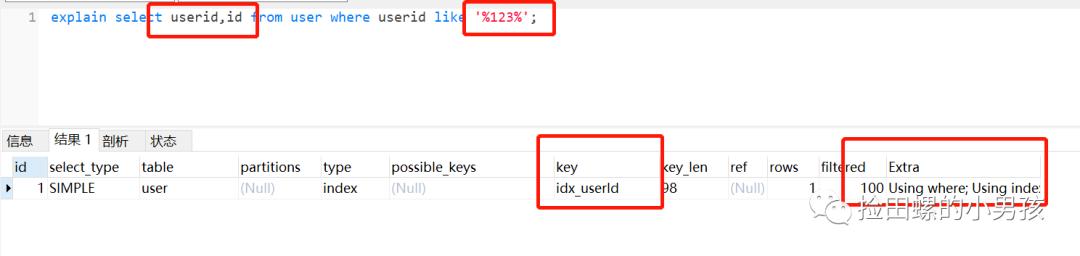 文章插图
文章插图
15、慎用distinct关键字 。
distinct 关键字一般用来过滤重复记录 , 以返回不重复的记录 。 在查询一个字段或者很少字段的情况下使用时 , 给查询带来优化效果 。 但是在字段很多的时候使用 , 却会大大降低查询效率 。
反例:
SELECT DISTINCT * from user;
正例:
select DISTINCT name from user;
理由:带distinct的语句cpu时间和占用时间都高于不带distinct的语句 。 因为当查询很多字段时 , 如果使用distinct , 数据库引擎就会对数据进行比较 , 过滤掉重复数据 , 然而这个比较、过滤的过程会占用系统资源 , cpu时间 。
16、删除冗余和重复索引
反例:
KEY `idx_userId` (`userId`)
KEY `idx_userId_age` (`userId`,`age`)
正例:
//删除userId索引 , 因为组合索引(A , B)相当于创建了(A)和(A , B)索引
KEY `idx_userId_age` (`userId`,`age`)
理由:重复的索引需要维护 , 并且优化器在优化查询的时候也需要逐个地进行考虑 , 这会影响性能的 。
17、如果数据量较大 , 优化你的修改/删除语句 。
避免同时修改或删除过多数据 , 因为会造成cpu利用率过高 , 从而影响别人对数据库的访问 。
反例:
//一次删除10万或者100万+?
delete from user where id <100000;
//或者采用单一循环操作 , 效率低 , 时间漫长
for(User user:list){
delete from user;
}
正例:
//分批进行删除,如每次500
delete user where id<500
delete product where id>=500 and id<1000;
理由:一次性删除太多数据 , 可能会有lock wait timeout exceed的错误 , 所以建议分批操作 。
18、where子句中考虑使用默认值代替 。
反例:
select * from user where age is not ; 文章插图
文章插图
正例:
//设置0为默认值
select * from user where age>0; 文章插图
文章插图
理由:
- 并不是说使用了is 或者 is not 就会不走索引了 , 这个跟mysql版本以及查询成本都有关;
- 如果把值 , 换成默认值 , 很多时候让走索引成为可能 , 同时 , 表达意思会相对清晰一点 。
- 连表越多 , 编译的时间和开销也就越大;
- 把连接表拆开成较小的几个执行 , 可读性更高;
- 如果一定需要连接很多表才能得到数据 , 那么意味着糟糕的设计了 。
这样写等价于:
先查询部门表B
select deptId from B
再由部门deptId , 查询A的员工
select * from A where A.deptId = B.deptId
可以抽象成这样的一个循环:
List<> resultSet ;
for(int i=0;ifor(int j=0;jif(A[i].id==B[j].id){
resultSet.add(A[i]);
break;
}
}
}
显然 , 除了使用in , 我们也可以用exists实现一样的查询功能 , 如下:
select * from A where exists ( select 1 from B where A.deptId =B.deptId);
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 联网时代|34岁转行做程序员是否还有成功的机会
- 检查|填补软件开发市场空白,飞算全自动软件工程平台瞄准全自动后端微服务开发
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 这些错误,程序员经常会犯,你了解过吗?
- 程序员面试主要看哪些 该怎么准备面试内容
- 中国程序员最容易发音错误的单词,看看你有没有读错
- 程序员大佬整理的300本编程电子书,整整12个G你想学的都有
- Rust能不能做后端开发语言?
- 程序员年包90w,回老家被月薪3800表哥怼,催他赶紧上岸