后端程序员书写高质量SQL的30条建议
前言
本文将结合实例demo , 阐述30条有关于优化SQL的建议 , 多数是实际开发中总结出来的 , 希望对大家有帮助 。
正文
1、查询SQL尽量不要使用select * , 而是select具体字段 。
反例子:
select * from employee;
正例子:
select id , name from employee;
理由:
- 只取需要的字段 , 节省资源、减少网络开销;
- select * 进行查询时 , 很可能就不会使用到覆盖索引了 , 就会造成回表查询 。
假设现在有employee员工表 , 要找出一个名字叫jay的人 。
CREATE TABLE `employee` (
`id` int(11) NOT ,
`name` varchar(255) DEFAULT ,
`age` int(11) DEFAULT ,
`date` datetime DEFAULT ,
`sex` int(1) DEFAULT ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
反例:
select id , name from employee where name='jay'
正例:
select id , name from employee where name='jay' limit 1;
理由:
- 加上limit 1后,只要找到了对应的一条记录,就不会继续向下扫描了,效率将会大大提高;
- 当然 , 如果name是唯一索引的话 , 是不必要加上limit 1了 , 因为limit的存在主要就是为了防止全表扫描 , 从而提高性能,如果一个语句本身可以预知不用全表扫描 , 有没有limit, 性能的差别并不大 。
新建一个user表 , 它有一个普通索引userId , 表结构如下:
CREATE TABLE `user`(
`id` int (11) NOT AUTO_INCREMENT,
`userId` int(11) NOT ,
`age` int(11) NOT ,
`name` varchar (255) NOT ,
PRIMARY KEY (`id`),
KEY `idx_userId`(`userId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
假设现在需要查询userid为1或者年龄为18岁的用户 , 很容易有以下SQL
反例:
select * from user where userid=1 or age =18
正例:
//使用union all
select * from user where userid=1
union all
select *from user where age =18
//或者分开两条sql写:
select * from user where userid=1
selet * from user where age=18
理由:使用or可能会使索引失效 , 从而全表扫描 。
对于or+没有索引的age这种情况 , 假设它走了userId的索引 , 但是走到age查询条件时 , 它还得全表扫描 , 也就是需要三步过程:全表扫描+索引扫描+合并 。
如果它一开始就走全表扫描 , 直接一遍扫描就完事 。 mysql是有优化器的 , 处于效率与成本考虑 , 遇到or条件 , 索引可能失效 , 看起来也合情合理 。
4、优化limit分页 。
我们日常做分页需求时 , 一般会用 limit 实现 , 但是当偏移量特别大的时候 , 查询效率就变得低下 。
反例:
select id , name , age from employee limit 10000 , 10
正例:
//方案一 :返回上次查询的最大记录(偏移量)
select id , name from employee where id>10000 limit 10.
//方案二:order by + 索引
select id , name from employee order by id limit 10000 , 10
//方案三:在业务允许的情况下限制页数:
理由:
- 当偏移量最大的时候 , 查询效率就会越低 , 因为Mysql并非是跳过偏移量直接去取后面的数据 , 而是先把偏移量+要取的条数 , 然后再把前面偏移量这一段的数据抛弃掉再返回的;
- 如果使用优化方案一 , 返回上次最大查询记录(偏移量) , 这样可以跳过偏移量 , 效率提升不少;
- 方案二使用order by+索引 , 也是可以提高查询效率的;
- 方案三的话 , 建议跟业务讨论 , 有没有必要查这么后的分页啦 。 因为绝大多数用户都不会往后翻太多页 。
日常开发中 , 如果用到模糊关键字查询 , 很容易想到like , 但是like很可能让你的索引失效 。
反例:
select userId , name from user where userId like '%123';
正例:
select userId , name from user where userId like '123%';
理由:
- 把%放前面 , 并不走索引 , 如下:
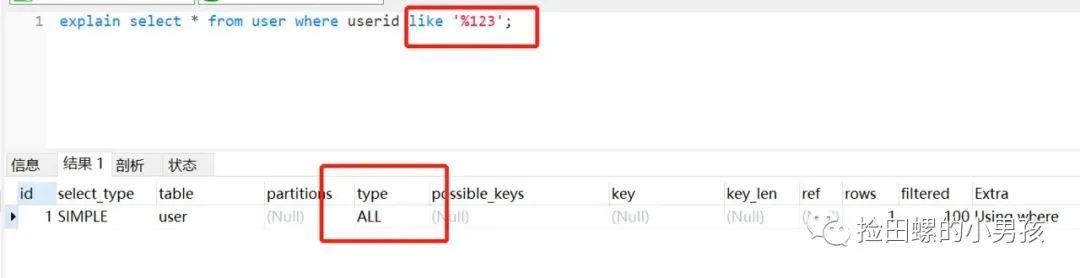 文章插图
文章插图- 把% 放关键字后面 , 还是会走索引的 。 如下:
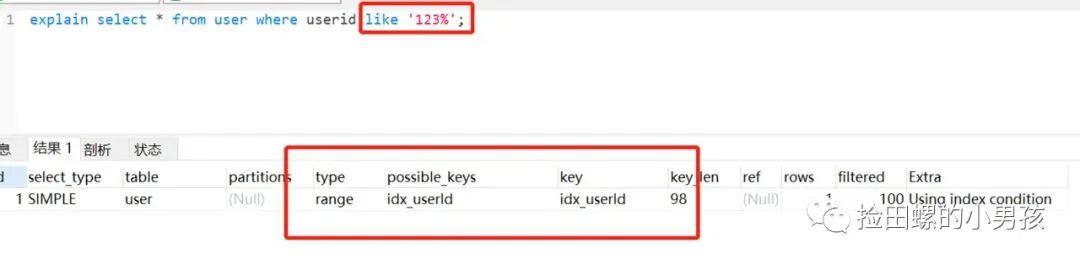 文章插图
文章插图6、使用where条件限定要查询的数据 , 避免返回多余的行 。
假设业务场景是这样:查询某个用户是否是会员 。 曾经看过老的实现代码是这样 。。。
反例:
List
- 现状|程序员现状揭秘:平均年薪20.36万,Java人才需求量最大
- 联网时代|34岁转行做程序员是否还有成功的机会
- 检查|填补软件开发市场空白,飞算全自动软件工程平台瞄准全自动后端微服务开发
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 这些错误,程序员经常会犯,你了解过吗?
- 程序员面试主要看哪些 该怎么准备面试内容
- 中国程序员最容易发音错误的单词,看看你有没有读错
- 程序员大佬整理的300本编程电子书,整整12个G你想学的都有
- Rust能不能做后端开发语言?
- 程序员年包90w,回老家被月薪3800表哥怼,催他赶紧上岸