机器学习下的持续交付( 七 )
在我们的示例中 , 图5中的机器学习pipeline从download data.py文件开始 , 该文件负责从共享的地方下载训练集 。 如果我们在共享的地方更改数据集的内容 , 它并不会立即触发pipeline , 因为代码没有更改 , DVC也无法检测它 。 要对数据进行版本控制 , 我们必须创建一个新文件或更改文件名 , 这反过来要求我们使用新的路径更新download data.py脚本 , 并因此创建一个新的代码提交 。
这种方法的一个改进是允许DVC跟踪我们的文件内容 , 其改进是在机器学习pipeline的第一步替换我们手写的下载脚本 , 如图9所示:
dvc add data/raw/store47-2016.csv ?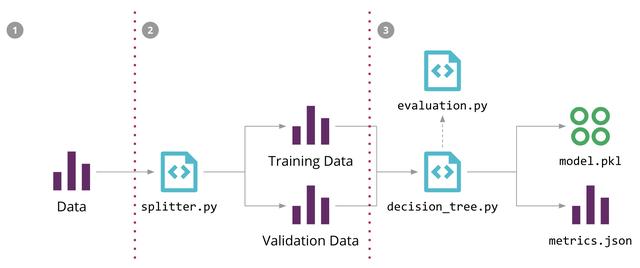 文章插图
文章插图
(图9:更新第一步来允许DVC跟踪数据版本 , 同时简化ML的pipeline)
这将创建一个元数据文件 , 该文件跟踪文件内容的校验和 , 我们可以将校验和提交给Git 。 现在 , 当文件内容更改时 , 校验和将更改 , DVC将更新该元数据文件 , 这将是触发pipeline执行时所需的提交 。
虽然这允许我们在数据更改时重新训练模型 , 但它并没有说明数据版本控制的全部内容 。 一个方面是历史数据:理想情况下你会想要保持所有数据的整个历史变化 , 但这并不是总是可行的 , 具体取决于数据变化的频率 。 另一个方面是数据来源:了解是什么处理步骤导致了数据发生更改 , 以及如何跨越不同的数据集进行传播 。 还有一个问题是随着时间的推移来跟踪和演进数据的模式 , 我们需要知道这些更改是否向后和向前兼容 。
如果你在一个流媒体世界中 , 那么数据版本控制的这些方面将变得更加复杂 , 因此我们希望在这个领域中有更多的实践、工具和技术得到发展 。
数据Pipelines到目前为止我们还没有讨论的另一个方面是如何对数据pipelines本身进行版本、测试、部署和监视 。 在现实世界中 , 一些工具选项比其他工具更好地支持CD4ML 。 例如 , 许多ETL工具需要通过GUI定义转换和处理步骤 , 这些工具通常不容易进行版本控制 , 也不易于测试或部署到混合环境中 。
我们倾向于使用开放源码工具 , 这些工具允许我们在代码中定义数据pipeline , 这样更容易进行版本控制、测试和部署 。 例如 , 如果你正在使用Spark , 你的数据pipeline可能是用Scala编写的 , 你可以使用ScalaTest或Spark -test -base对其进行测试 , 然后将该作业打包为JAR构件 , 该构件就可以在GoCD中的部署pipeline上进行版本控制和部署 。
作为数据Pipelines通常作为批处理作业运行或作为一个长时间运行的流媒体应用程序,在图8中 , 我们没有包括他们在端到端的CD4ML流程图,但如果他们改变了你的模型或应用程序的需要的输出 , 就会造成另一个潜在来源的集成问题 。 因此 , 我们所追求的是将集成和数据Contract Tests作为部署Pipelines的一部分来捕获这些错误 。
与数据Pipelines相关的另一种测试类型是数据质量检查 , 但这可能成为另一个广泛讨论的主题 , 最好在单独的文章中讨论 。
平台思维你可能已经注意到 , 我们使用了各种工具和技术来实现CD4ML 。 如果您有多个团队尝试这样做 , 他们可能最终可能会可能重塑事物或重复工作 。 这就是平台思维的用武之地 。 不是通过将所有的工作集中到一个团队中 , 导致他们成为瓶颈 , 而是将平台工程的工作集中到与领域无关的构建工具中 , 既隐藏了潜在的复杂性 , 也加快了团队的上手速度 。 我们的同事Zhamak Dehghani在她的Data Mesh文章中对此进行了更详细的讨论 。
将平台思维应用于CD4ML是我们看到机器学习平台和其他产品越来越受关注的原因 , 这些产品试图提供一个单一的解决方案来管理端到端机器学习生命周期 。 许多主要的技术巨头都开发了自己的内部工具 , 但我们相信这是一个活跃的研究和开发领域 , 并期望出现新的工具和供应商 , 提供可以被更广泛采用的解决方案 。
总结随着机器学习技术的不断发展和执行越来越复杂的任务 , 如何管理和交付此类应用程序到生产中的知识也在不断发展 。 通过从持续交付中引入和扩展的原则和实践 , 我们可以更好地管理 , 以安全可靠的方式发布对机器学习应用程序的更改的风险 。
通过一个示例的销售预测应用程序 , 我们在本文中展示了CD4ML的技术组件 , 并讨论了实现这些组件的几种方法 。 我们相信这种技术将会继续发展 , 新的工具将会不断出现和消失 , 但是持续交付的核心原则仍然是保持不变的 , 你应该为自己的机器学习应用程序做更多的思考 。
- 推新标准建新生态,下载超198亿次金山发力海内外
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 看过明年的iPhone之后,现在下手的都哭了
- 砍单|iPhone12之后,拼多多又将iPhone12Pro拉下水
- 巨头|“社区薇娅”都不够用了 一线互联网巨头全员下场卖菜
- 余额|中兴通讯:现有资金余额仅能确保公司当前经营规模下现金流安全
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人