机器学习下的持续交付( 六 )
- 模型输入:了解什么数据被送进来模型 , 这样可以看到任何训练服务的出现的偏差 。 模型输出:模型用这些输入来产生什么样的预测以及推荐 , 方便理解模型在真实数据下表现的如何 。
- 可解释的模型输出:一些指标比如说模型的系数、ELI5或者LIME输出使得我们能够进行更深入的调查去理解模型如何作出预测 , 以及确定潜在的过拟合或者在训练期间没有找到的的权重 。
- 模型的公平性:分析输入的数据和输出的预测结果和已有的特征做对比 , 这可以包括权重 , 比如说比赛、性别、年龄、收入群体等等 。
- Elasticsearch:一个开源的搜索引擎 。
- FluentD:一个开源的对统一日志源的收集程序
- Kibana:一个开源的web UI 让使用者能够更简单的探索和可视化Elasticsearch的数据索引 。
predict_with_logging.py… df = pd.DataFrame(data=http://kandian.youth.cn/index/data, index=['row1'])df = decision_tree.encode_categorical_columns(df)pred = model.predict(df)logger = sender.FluentSender(TENANT, host=FLUENTD_HOST, port=int(FLUENTD_PORT))log_payload = {'prediction': pred[0], **data}logger.emit('prediction', log_payload)这个事件之后就被转发 , 并且被ElasticSearch索引 , 我们可以使用Kibana的web接口去查询和分析它 , 就像下面图7所示 。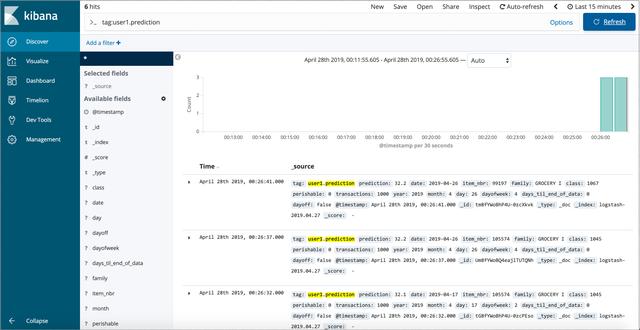 文章插图
文章插图(图7:在Kibana分析我们的模型对实际输入数据的预测)
这里有一些其他的监控和可视化的工具 , 比如说ELK stack(另一种方法是使用Logstash代替FluentD来收集日志和转发) , Splunk等等 。
收集监控和可见的数据甚至比你部署了多个模型在生产环境中更重要 。 比如说 , 你可能对多个模型进行分开的测试————或者简单的并排部署一个影子模型在你的正常的模型中来对同样的生产环境下的数据作出预测并比较它们 。
如果你正在训练或者运行联合模型在边缘设备上也与这是有关系的————比如说在一个移动设备上————或者如果你部署一个随着时间推移 , 用生产环境中的新数据学习的在线学习的模型 。
通过捕获这些数据 , 你能够使这些数据的反馈闭环 。 要做到这些 , 我们可以通过收集更多的真实数据(例如 , 在一个价格引擎或者推荐系统里)或者增加人类到这个环中去分析从生产环境中捕获的新数据 , 帮助它为新的和改进的模型创建新的训练数据集来使之闭环 。 能使这个反馈闭环就是CD4ML的主要优点之一 , 因为它允许我们调整从真实生产环境中的数据所学习的模型 , 进而开创了一个可持续改进的流程 。
端到端的CD4ML流程通过慢慢解决每个技术挑战 , 并使用各种工具和技术 , 我们成功的创建了如图8所示的端到端流程 。 该流程管理横跨三个维度的组件的推广:代码 , 模型和数据 。
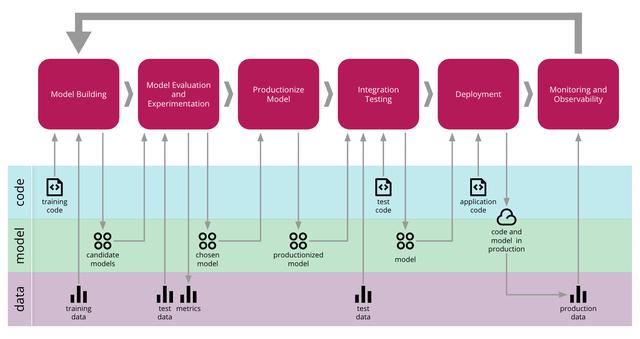 文章插图
文章插图(图8:机器学习端到端流程的持续交付)
首先 , 我们需要有一种简单的方法来管理、发现、访问和版本化我们的数据 。然后 , 我们将模型构建和训练的过程自动化 , 使其可重现 。这使我们能够实验和训练多个模型 , 此时我们就需要管理和跟踪这些实验 。一旦我们找到合适的模型 , 我们就可以决定如何生产和服务 。由于模型正在发展 , 我们必须确保它不会破坏与消费者的任何关联 , 因此我们需要在部署到生产之前对其进行测试 。一旦投入生产 , 我们就可以使用监控和可观察性基础设施来收集新数据 , 这些新数据可以分析和创建新训练集 , 从而使持续改进的反馈循环闭环 。
一个可持续交付业务流程设置工具可以协调端到端CD4ML流程 , 按需提供所需的基础架构 , 并管理模型和应用程序如何部署到生产环境 。
当下 , 我们如何起步?我们在本文中使用的示例应用程序和代码可以在我们的Github存储库中找到 , 并作为我们在各种会议与客户在为期半天的研讨中展示的基本样例 。 我们将继续发展关于如何实现CD4ML的想法 。 在本节结束时 , 我们强调了研讨材料中没有反映的一些改进领域 , 以及需要进一步探讨的一些开放领域 。
数据版本控制在持续交付中 , 我们将每个代码提交作为一个发布候选 , 这将触发部署pipeline的新的执行动作 。 假设提交的代码通过了所有pipeline阶段 , 它就可以部署到生产环境中 。 而当谈到CD4ML时 , 我们经常遇到的一个问题是“当数据发生变化时 , 我如何触发pipeline?”
- 推新标准建新生态,下载超198亿次金山发力海内外
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 看过明年的iPhone之后,现在下手的都哭了
- 砍单|iPhone12之后,拼多多又将iPhone12Pro拉下水
- 巨头|“社区薇娅”都不够用了 一线互联网巨头全员下场卖菜
- 余额|中兴通讯:现有资金余额仅能确保公司当前经营规模下现金流安全
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人