PyTorch中傅立叶卷积:计算大核卷积的数学原理和代码实现
 文章插图
文章插图
卷积卷积在数据分析中无处不在 。几十年来 , 它们已用于信号和图像处理 。最近 , 它们已成为现代神经网络的重要组成部分 。
在数学上 , 卷积表示为: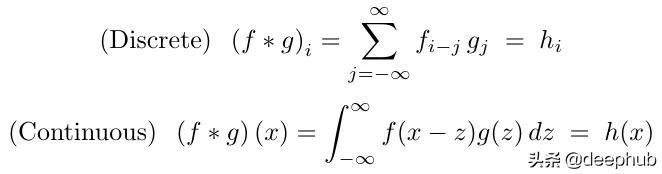 文章插图
文章插图
尽管离散卷积在计算应用程序中更为常见 , 但由于本文使用连续变量证明卷积定理(如下所述)要容易得多 , 因此在本文的大部分内容中 , 我将使用连续形式 。之后 , 我们将返回离散情况 , 并使用傅立叶变换在PyTorch中实现它 。离散卷积可以看作是连续卷积的近似值 , 其中连续函数在规则网格上离散化 。因此 , 我们不会为离散情况重新证明卷积定理 。
卷积定理在数学上 , 卷积定理可以表示为: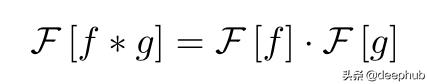 文章插图
文章插图
连续傅里叶变换的位置(最大归一化常数):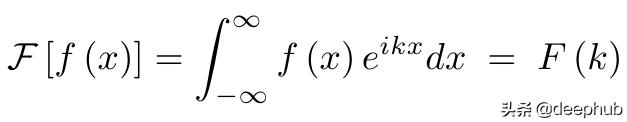 文章插图
文章插图
换句话说 , 位置空间的卷积等价于频率空间的直接乘法 。 这个想法是相当不直观的 , 但证明卷积定理是惊人的容易对于连续的情况 。 首先把方程的左边写出来 。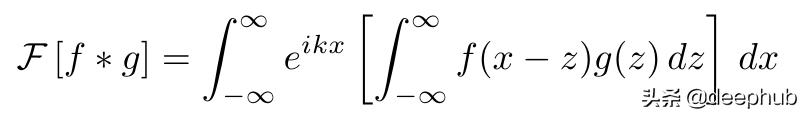 文章插图
文章插图
现在改变积分的顺序 , 替换变量(x = y + z) , 并分离两个被积函数 。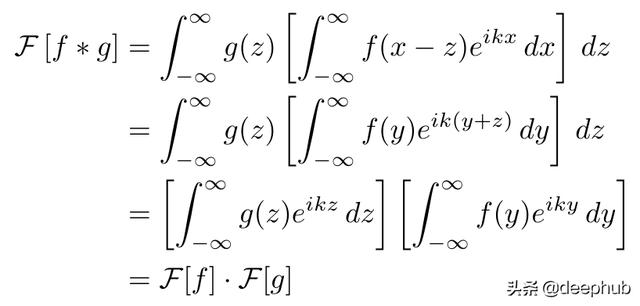 文章插图
文章插图
我们为什么要关心所有这些? 因为快速傅立叶变换的算法复杂度比卷积低 。直接卷积的复杂度为O(n2) , 因为我们将g中的每个元素传递给f中的每个元素 。快速傅立叶变换可以在O(n log n)的时间内计算出来 。当输入数组很大时 , 它们比卷积要快得多 。在这些情况下 , 我们可以使用卷积定理来计算频率空间中的卷积 , 然后执行傅立叶逆变换以返回到位置空间 。
当输入较小时(例如3x3卷积内核) , 直接卷积仍然更快 。在机器学习应用程序中 , 使用较小的内核大小更为常见 , 因此PyTorch和Tensorflow之类的深度学习库仅提供直接卷积的实现 。但是 , 在现实世界中 , 有很多使用大内核的用例 , 其中傅立叶卷积更为有效 。
PyTorch实现现在 , 我将演示如何在PyTorch中实现傅立叶卷积函数 。它应该模仿torch.nn.functional.convNd的功能 , 并在实现中利用FFT , 而无需用户做任何额外的工作 。这样 , 它应该接受三个张量(信号 , 内核和可选的偏差) , 并填充以应用于输入 。从概念上讲 , 此功能的内部工作原理是:
def fft_conv(signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0,) -> Tensor:# 1. Pad the input signal & kernel tensors# 2. Compute FFT for both signal & kernel# 3. Multiply the transformed Tensors together# 4. Compute inverse FFT# 5. Add bias and return让我们根据上面显示的操作顺序逐步构建FFT卷积 。在此示例中 , 我将构建一个1D傅立叶卷积 , 但是将其扩展到2D和3D卷积很简单 。最后我们也会提供github的代码库 。 在该存储库中 , 我实现了通用的N维傅立叶卷积方法 。
1 填充输入阵列
我们需要确保填充后信号和内核的大小相同 。将初始填充应用于信号 , 然后调整填充以使内核匹配 。
# 1. Pad the input signal & kernel tensorssignal = f.pad(signal, [padding, padding])kernel_padding = [0, signal.size(-1) - kernel.size(-1)]padded_kernel = f.pad(kernel, kernel_padding)注意 , 我只在一侧填充内核 。我们希望原始内核位于填充数组的左侧 , 以便它与信号数组的开始对齐 。
2 计算傅立叶变换
这非常容易 , 因为在PyTorch中已经实现了N维FFT 。我们只需使用内置函数 , 然后沿每个张量的最后一个维度计算FFT 。
# 2. Perform fourier convolutionsignal_fr = rfftn(signal, dim=-1)kernel_fr = rfftn(padded_kernel, dim=-1)3 乘以变换后的张量
这是我们功能中最棘手的部分 。这有两个原因 。
(1)PyTorch卷积在多维张量上运行 , 因此我们的信号和内核张量实际上是三维的 。从PyTorch文档中的该方程式 , 我们看到矩阵乘法是在前两个维度上执行的(不包括偏差项):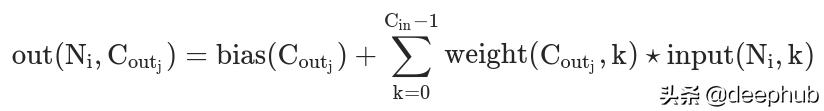 文章插图
文章插图
我们需要包括此矩阵乘法以及转换后的维度上的直接乘法 。
(2)在官方文档中所示 , PyTorch实际上实现了互相关方法而不是卷积 。(TensorFlow和其他深度学习库也是如此 。 )互相关与卷积密切相关 , 但有一个重要的符号变化:
- 在Linux系统中安装深度学习框架Pytorch
- 输出层|PyTorch可视化理解卷积神经网络
- 类别|如何用PyTorch进行语义分割?一个教程教会你
- PyTorch1.7发布,支持CUDA11分布式训练
- 在TPU上运行PyTorch的技巧总结
- 如何在PyTorch和TensorFlow中训练图像分类模型
- 如何利用PyTorch中的Moco-V2减少计算约束
- 检测器|案例解析:用Tensorflow和Pytorch计算骰子值
- 将PyTorch投入生产的5个常见错误
- 使用PolyGen和PyTorch生成3D模型