检测器|案例解析:用Tensorflow和Pytorch计算骰子值
点击上方关注 , All in AI中国在之前的文章中 , 我讨论了如何在Tensorflow中使用大约400个带注释的图像作为训练数据来构建12类骰子检测器 。 该模型的目标是检测6、8、10或12面骰子的骰子每一面的存在 , 然后确定显示的那一面的值是什么 。 完成后 , 我可以在屏幕上获得骰子的总值 。
这个模型在任务上表现得相当不错 , 但问题是要么不识别骰子的那一面 , 要么错误分类了它确实检测到的面部值 。 所以在上一篇文章的最后 , 我提到我要解决这个问题的另一种方法是建立一个专门用于检测骰子面的第一阶段对象检测器 , 然后是第二阶段CNN , 它可以使用第一阶段的输出模型来确定数字 。 虽然这增加了训练和实施管道的复杂性 , 但我觉得它可以提高整体性能 。
我对潜在性能改进的推理基于是使用一种尺寸适合所有通用模型的优势 , 而不是将问题分解为更小的部分并构建专门针对特定任务的模型 。 在这种情况下 , 第一阶段物体检测器可以学习单独地与每种类型的骰子来识别骰子面部 。 这意味着它可以从不同的角度更多地看到骰子 , 因为根据方向识别8面和10面骰子上的面部就会产生类似的问题 。 然后在第二阶段CNN我可以应用大量的旋转和翻转来增加数据 , 这比我之前构建的通用对象检测模型中的数据要高得多 , 它可以帮助在任何方向都更好地识别骰子值 。 文章插图
文章插图
新的对象检测模型具有单个类“dice_top” , 这些框被传递到后端ResNet模型进行分类 。 文章插图
文章插图
来自之前博客的同一视频的GIF重新运行 。 两阶段管道也获得20的值
你可以在这里找到github上的代码() 。 这些脚本需要用作Tensorflow对象检测库的一部分 , 并且我在各个点都修改了检测脚本以进行数据准备 。 那些有我用来做图像和视频最终标签的那些 , 就如帖子所示 。
训练新物体探测器
对于这个项目 , 我使用了我之前博客中使用的相同的数据集 。 对于物体检测模型 , 我仅使用200个图像 , 其中我调整了所有边界框以具有标签“dice_top”而不是数字1-12 。 我通过使用Labelimg快速浏览xmls并手动调整标签来完成此操作 。 最初我试图在xmls生成的csv中自动调整标签 , 但在训练时遇到了奇怪的模型行为 , 所以我又回到了手动方法 。
对于单一类 , 模型只需要运行一个小时左右才能将其停在一个良好的阈值 , 而不是前一个模型所需的6个小时左右 。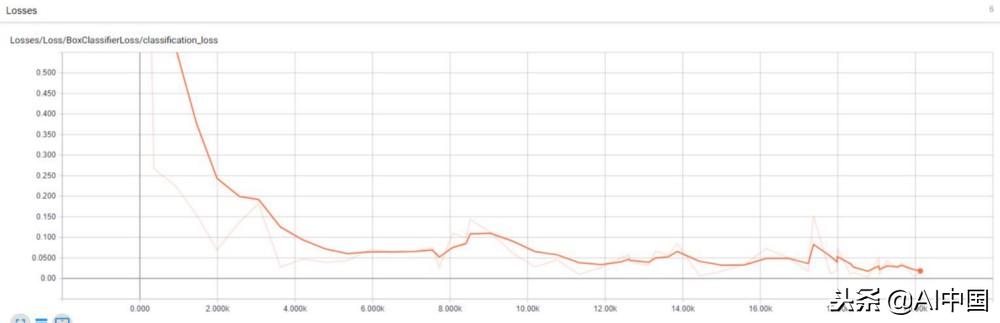 文章插图
文章插图
在这个阶段 , 我能够评估新物体检测模型与其前身相比如何进行预处理 。 快速出现的是它检测到错过第一个模型的检测骰子 。 左下方的图像是第一个模型的输出 , 而右侧的图像是新的单个类检测器处理的相同图像 。 左侧的6可以在新的中检测到 , 但在第一个模型中省略 。 文章插图
文章插图 文章插图
文章插图
类似的故事可以在以下图像中看到 。 第一个模型在d8顶部附近未检测到 , 但第二个模型可以检测到 。 文章插图
文章插图 文章插图
文章插图
两个模型都显示出出现10面骰子的劣势 。 在这种情况下 , 两个模型在检测角落中的蓝色10面骰子时表现不佳 , 第一个模型更是直接失败了 。 文章插图
文章插图 文章插图
文章插图
因此 , 虽然第一个模型在未能识别蓝色10面骰子的顶部方面做得更好 , 但我认为值得注意的是 , 新的单类检测器的数据量只有一半 , 但它可以比前一代更好的检测骰子 。
现在新的骰子探测器就位 , 我可以继续开始建立第二阶段的价值分类模型 。
为后端模型准备数据
更有趣的数据准备工作是获取后端CNN的数据 。 我知道我需要训练一个模型来识别骰子面上的数字 , 无论它们的方向如何 , 所以我认为CNN对于随机垂直和水平翻转以及随机旋转形式的大量数据增加将是有帮助的 。 我决定使用Pytorch后端模型 , 因为它提供了一个很好的简单管道来训练和部署它的模型(我也只运行了太多的Keras模型和类似的品种) 。 使用Pytorch的其他原因主要是我喜欢使用Pytorch , 并且在我的其他博客中为这类问题提供了良好的代码库 。
- 高像素|加持高像素只为解析力?vivo S7丛林秘境展对样张细节的要求更严苛
- 用了就停不下来,解析全网视频,不仅免费还能下载
- 案例:如何使用接口测试框架Karate创建一个API测试?
- 详解mysql执行计划
- python之hashlib详解,附案例和计算文件哈希值算法
- 在美国当快递小哥赚钱吗?西瓜视频解析除了努力,运气也很重要
- 标识|食品行业工业互联网标识解析二级节点、“星火·链网”骨干节点在漯河上线
- 茶业|科技引领中国茶业,小罐茶入选《企业数字化升级之路》白皮书案例
- 数字|Westfield客户体验创新案例,发现从未被发现的客户痛点
- 治理|京东数科再秀智能城市战略图,解密产业案例最新进展