如何利用PyTorch中的Moco-V2减少计算约束
介绍SimCLR论文(~arastogi/papers/simclr.pdf)解释了这个框架如何从更大的模型和更大的批处理中获益 , 并且如果有足够的计算能力 , 可以产生与监督模型类似的结果 。
但是这些需求使得框架的计算量相当大 。 如果我们可以拥有这个框架的简单性和强大功能 , 并且有更少的计算需求 , 这样每个人都可以访问它 , 这不是很好吗?Moco-v2前来救援 。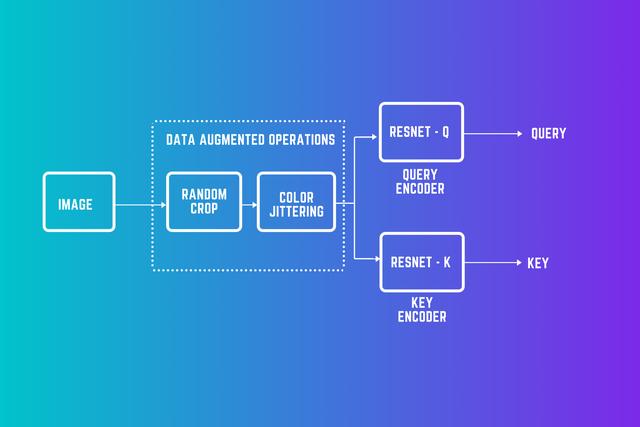 文章插图
文章插图
注意:在之前的一篇博文中 , 我们在PyTorch中实现了SimCLR框架 , 它是在一个包含5个类别的简单数据集上实现的 , 总共只有1250个训练图像 。
数据集这次我们将在Pytorch中在更大的数据集上实现Moco-v2 , 并在Google Colab上训练我们的模型 。 这次我们将使用Imagenette和Imagewoof数据集 文章插图
文章插图
来自Imagenette数据集的一些图像 文章插图
文章插图
这些数据集的快速摘要(更多信息在这里:):
- Imagenette由Imagenet的10个容易分类的类组成 , 总共有9479个训练图像和3935个验证集图像 。
- Imagewoof是一个由Imagenet提供的10个难分类组成的数据集 , 因为所有的类都是狗的品种 。 总共有9035个训练图像 , 3939个验证集图像 。
 文章插图
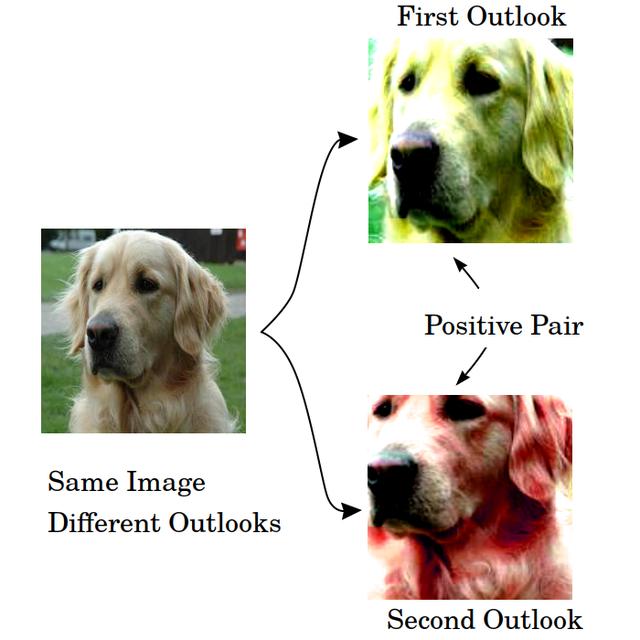
文章插图另外 , 我们希望不同类别的图像有不同的外观 , 使它们的表征彼此远离 。 不同图像的不同外观的呈现与类别无关 , 会被彼此推开 。 我们把这些不同的外观称为负对(negative pairs) 。
 文章插图
文章插图在这种情况下 , 一个图像的前景是什么?前景可以被认为是以一种经过修改的方式看待图像的某些部分 , 它本质上是图像的一种变换 。
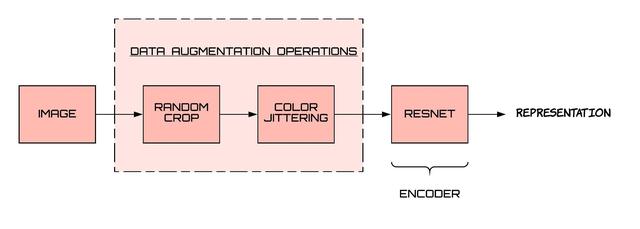
根据手头的任务 , 有些转换可以比其他转换工作得更好 。 SimCLR表明 , 应用随机裁剪和颜色抖动可以很好地完成各种任务 , 包括图像分类 。 这本质上来自于网格搜索 , 从旋转、裁剪、剪切、噪声、模糊、Sobel滤波等选项中选择一对变换 。
从外观到表示空间的映射是通过神经网络完成的 , 通常 , resnet用于此目的 。 下面是从图像到表示的管道
 文章插图
文章插图负对是如何产生的?在同一幅图像中 , 由于随机裁剪 , 我们可以得到多个表示 。 这样 , 我们就可以产生正对 。
但是如何生成负对呢?负对是来自不同图像的表示 。 SimCLR论文在同一批中创建了这些 。 如果一个批包含N个图像 , 那么对于每个图像 , 我们将得到2个表示 , 这总共占2*N个表示 。 对于一个特定的表示x , 有一个表示与x形成正对(与x来自同一个图像的表示) , 其余所有表示(正好是2*N–2)与x形成负对 。
如果我们手头有大量的负样本 , 这些表示就会得到改善 。 但是 , 在SimCLR中 , 只有当批量较大时 , 才能实现大量的负样本 , 这导致了对计算能力的更高要求 。 MoCo-v2提供了生成负样本的另一种方法 。 让我们详细了解一下 。
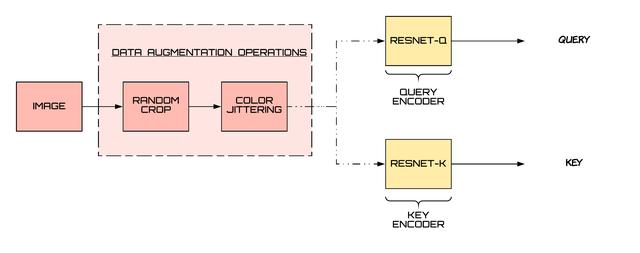
动态词典我们可以用一种稍微不同的方式来看待对比学习方法 , 即将查询与键进行匹配 。 我们现在有两个编码器 , 一个用于查询 , 另一个用于键 。 此外 , 为了得到大量的负样本 , 我们需要一个大的键编码字典 。
 文章插图
文章插图此上下文中的正对表示查询与键匹配 。 如果查询和键都来自同一个图像 , 则它们匹配 。 编码的查询应该与其匹配的键相似 , 而与其他查询不同 。
对于负对 , 我们维护一个大字典 , 其中包含以前批处理的编码键 。 它们作为查询的负样本 。 我们以队列的形式维护字典 。 新的batch被入队 , 较早的batch被出列 。 通过更改此队列的大小 , 可以更改负采样数 。
这种方法的挑战
- 随着键编码器的更改 , 在稍后时间点排队的键可能与较早排队的键不一致 。 为了使用对比学习方法 , 与查询进行比较的所有键必须来自相同或相似的编码器 , 这样比较才会有意义且一致 。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐