如何利用PyTorch中的Moco-V2减少计算约束( 二 )
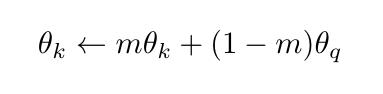 文章插图
文章插图其中m非常接近于1(例如 , 典型值为0.999) , 这确保我们在不同的时间从相似的编码器获得编码键 。
损失函数-InfoNCE我们希望查询接近其所有正样本 , 远离所有负样本 。 InfoNC函数E会捕获它 。 它代表信息噪声对比估计 。 对于查询q和键k , InfoNCE损失函数是:
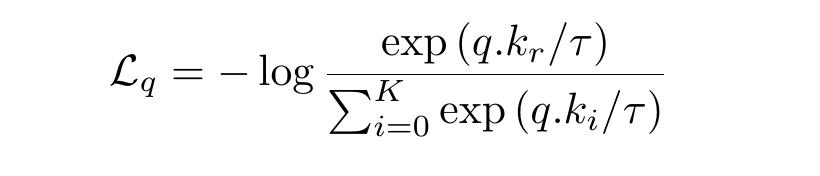 文章插图
文章插图我们可以重写为:
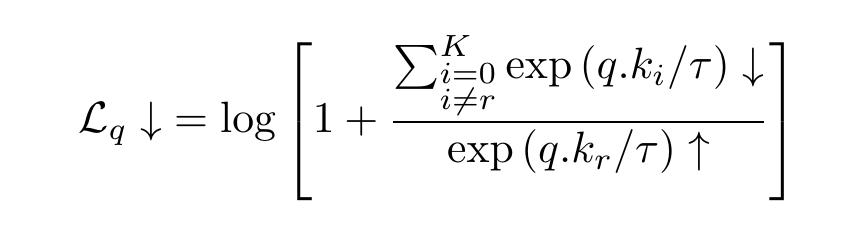 文章插图
文章插图当q和k的相似性增大 , q与负样本的相似性减小时 , 损失值减小
以下是损失函数的代码:
τ = 0.05def loss_function(q, k, queue):# N是批量大小N = q.shape[0]# C是表示的维数C = q.shape[1]# bmm代表批处理矩阵乘法# 如果mat1是b×n×m张量 , 那么mat2是b×m×p张量 ,# 然后输出一个b×n×p张量 。pos = torch.exp(torch.div(torch.bmm(q.view(N,1,C), k.view(N,C,1)).view(N, 1),τ))# 在查询和队列张量之间执行矩阵乘法neg = torch.sum(torch.exp(torch.div(torch.mm(q.view(N,C), torch.t(queue)),τ)), dim=1)# 求和denominator = neg + posreturn torch.mean(-torch.log(torch.div(pos,denominator)))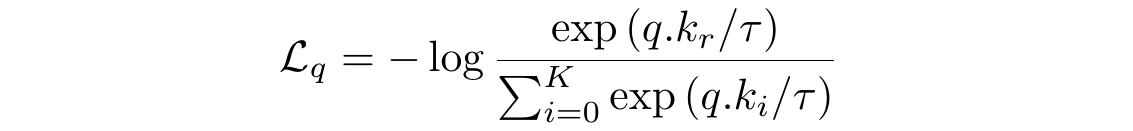 文章插图
文章插图让我们再看看这个损失函数 , 并将它与分类交叉熵损失函数进行比较 。
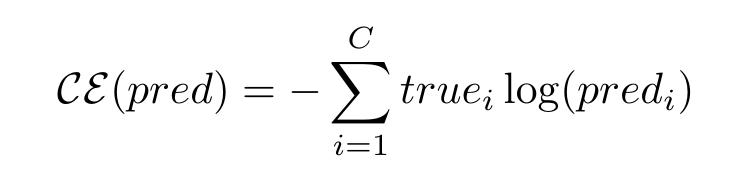 文章插图
文章插图这里pred?是数据点在第i类中的概率值预测 , true?是该点属于第i类的实际概率值(可以是模糊的 , 但大多数情况下是一个one-hot) 。
如果你不熟悉这个话题 , 你可以看这个视频来更好地理解交叉熵 。 另外 , 请注意 , 我们经常通过softmax这样的函数将分数转换为概率值:
我们可以把信息损失函数看作交叉熵损失 。 数据样本“q”的正确类是第r类 , 底层分类器基于softmax , 它试图在K+1类之间进行分类 。
Info-NCE还与编码表示之间的相互信息有关;关于这一点的更多细节见[4] 。
MoCo-v2框架现在 , 让我们把所有的东西放在一起 , 看看整个Moco-v2算法是什么样子的 。
步骤1:我们必须得到查询和键编码器 。 最初 , 键编码器具有与查询编码器相同的参数 。 它们是彼此的复制品 。 随着训练的进行 , 键编码器将成为查询编码器的移动平均值(在这一点上进展缓慢) 。
由于计算能力的限制 , 我们使用Resnet-18体系结构来实现 。 在通常的resnet架构之上 , 我们添加了一些密集的层 , 以使表示的维数降到25 。 这些层中的某些层稍后将充当投影 。
# 定义我们的深度学习架构resnetq = resnet18(pretrained=False)classifier = nn.Sequential(OrderedDict([('fc1', nn.Linear(resnetq.fc.in_features, 100)),('added_relu1', nn.ReLU(inplace=True)),('fc2', nn.Linear(100, 50)),('added_relu2', nn.ReLU(inplace=True)),('fc3', nn.Linear(50, 25))]))resnetq.fc = classifierresnetk = copy.deepcopy(resnetq)# 将resnet架构迁移到设备resnetq.to(device)resnetk.to(device)步骤2:现在 , 我们已经有了编码器 , 并且假设我们已经设置了其他重要的数据结构 , 现在是时候开始训练循环并理解管道了 。这一步是从训练批中获取编码查询和键 。 我们用L2范数对表示进行规范化 。
只是一个约定警告 , 所有后续步骤中的代码都将位于批处理和epoch循环中 。 我们还将张量“k”从它的梯度中分离出来 , 因为我们不需要计算图中的键编码器部分 , 因为动量更新方程会更新键编码器 。
# 梯度零化optimizer.zero_grad()# 检索xq和xk这两个图像batchxq = sample_batched['image1']xk = sample_batched['image2']# 把它们移到设备上xq = xq.to(device)xk = xk.to(device)# 获取他们的输出q = resnetq(xq)k = resnetk(xk)k = k.detach()# 将输出规范化 , 使它们成为单位向量q = torch.div(q,torch.norm(q,dim=1).reshape(-1,1))k = torch.div(k,torch.norm(k,dim=1).reshape(-1,1))步骤3:现在 , 我们将查询、键和队列传递给前面定义的loss函数 , 并将值存储在一个列表中 。 然后 , 像往常一样 , 对损失值调用backward函数并运行优化器 。# 获得损失值loss = loss_function(q, k, queue)# 把这个损失值放到epoch损失列表中epoch_losses_train.append(loss.cpu().data.item())# 反向传播loss.backward()# 运行优化器optimizer.step()
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐