说话者|机器学习不能解决自然语言理解( 三 )
ML 方法甚至与 NLU 无关:意图逻辑学家们长期以来一直在研究一种语义概念,试图用语义三角形解释什么是"内涵"。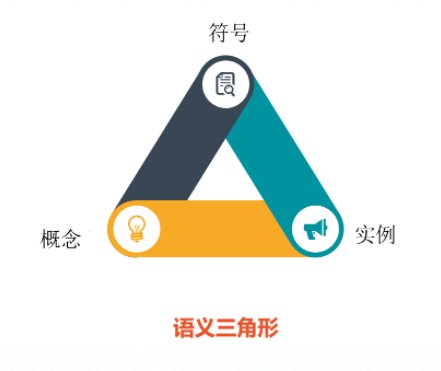
文章插图
一个符号用来指代一个概念,概念可能有实际的对象作为实例,但有些概念没有实例,例如,神话中的独角兽只是一个概念,没有实际的实例独角兽。类似地,"被取消的旅行"是对实际未发生的事件的引用,或从未存在的事件等。
因此,每个"事物"(或认知的每一个对象)都有三个部分:一个符号,符号所指的概念以及概念具有的具体实例。我有时说,因为概念"独角兽"没有"实际"实例。概念本身是其所有潜在实例的理想化模板(因此它接近理想化形式柏拉图)
一个概念(通常由某个符号/标签所指)是由一组属性和属性定义,也许还有额外的公理和既定事实等。然而,概念与实际(不完美)实例不同,在数学世界中也是如此。因此,例如,虽然下面的算术表达式都有相同的扩展,但它们有不同的语气:
内涵决定外延,但外延本身并不能完全代表概念。上述对象仅在一个属性上相等,即它们的值在许多其他属性上是不同的。在语言中,平等和同一性不能混淆,如果对象在某些属性值中是平等的,则不能认为对象是相同的。
因此,虽然所有的表达式评估相同,因此在某种意义上是相等的,但这只是它们的属性之一。事实上,上述表达式有几个其他属性,例如它们的语法结构、操作员数量、操作次数等。价值(这只是一个属性)称为外延,而所有属性的集合是内涵。虽然在应用科学(工程,经济学等),我们可以安全地认为它们相等仅属性,在认知中(尤其是在语言理解中),这种平等是失败的!下面是一个简单的示例:
假设(1)是真的,即假设(1)真的发生了,我们看到了/ 见证了它。不过,这并不意味着我们可以假设(2)是真的,尽管我们所做的只是将 (1) 中的 '1b' 替换为一个(假设)等于它的值。所以发生了什么事?
我们在真实陈述中用一个被认为与之相等的对象替换了一个对象,我们从真实的东西中推断出并非如此的东西!虽然在物理科学中,我们可以很容易地用一个属性来替换一个等于它的物体,但这在认知上是行不通的!下面是另一个可能与语言更相关的示例:
通过简单地将"亚历山大大帝的导师"替换为与其相等的值,即亚里士多德,我们得到了(2),这显然是荒谬的。同样,虽然"亚历山大大帝的导师"和"亚里士多德"在某种意义上是平等的(它们都具有相同的价值作为指称),这两个思想对象在许多其他属性上是不同的。那么,这个关于"内涵"的讨论有什么意义呢?
自然语言充斥着内涵现象,因为语言具有不可忽视的内涵。但是机器学习/数据驱动方法的所有变体都纯粹是延伸的——它们以物体的数字(矢量/紧张)表示来运作,而不是它们的象征性和结构特性,因此在这个范式中,我们不能用自然语言来模拟各种内涵。顺便说一句,神经网络纯粹是延伸的,因此不能表示内涵,这是它们总是容易受到对抗性攻击的真正原因,尽管这个问题超出了本文的范围。
结束语我在本文中讨论了三个原因,证明机器学习和数据驱动方法甚至与 NLU 无关(尽管这些方法可用于某些本质上是压缩任务的文本处理任务)。以上三个理由本身都足以结束这场夸张的自然语言理解的数字工程。
人类在传达自己的想法时,其实是在传递高度压缩的语言表达,需要用大脑来解释和"揭示"所有缺失但隐含假设的背景信息。
语言是承载思想的人工制品,因此,在构建越来越大的语言模型时,机器学习和数据驱动方法试图在尝试找到数据中甚至不存在的东西时,徒劳地追逐无穷大。
我们必须认识到,普通的口语不仅仅是语言数据。
编译来源:Machine Learning Won't Solve Natural Language Understanding (thegradient.pub)
雷锋网雷锋网雷锋网
- 彼尔姆|机器人公司想用 20 万美元「买断」你的脸,如果它足够友好
- 人机|人机融合时代,中国机器人如何弯道超车
- mp4|Web前端培训:学习JavaScript重要知识点有哪些?
- 医疗器械|柳叶刀机器人完成数千万元Pre-A+轮融资
- Python|小米 CyberDog 机器人将运行 Ubuntu 操作系统
- 机器人|你愿意卖你的脸吗?俄罗斯公司开价127万,买断你脸的永久使用权
- 柳叶刀|融资丨「柳叶刀机器人」完成Pre-A+轮融资,聚焦骨科及口腔手术智能化
- 机器|工业触摸屏一旦出现了失灵,我们要如何处理你知道吗?
- 小米科技|小米扫地机器人减少,云米营收降三成,深陷亏损困境
- 抖音|学习“优爱腾”,抖音也要收费了