知识|产品视角下的知识图谱构建流程与技术理解( 七 )
手工建立关系非常耗时,目前的研究热点是采用合理的方法和工具进行自动或半自动的构建。
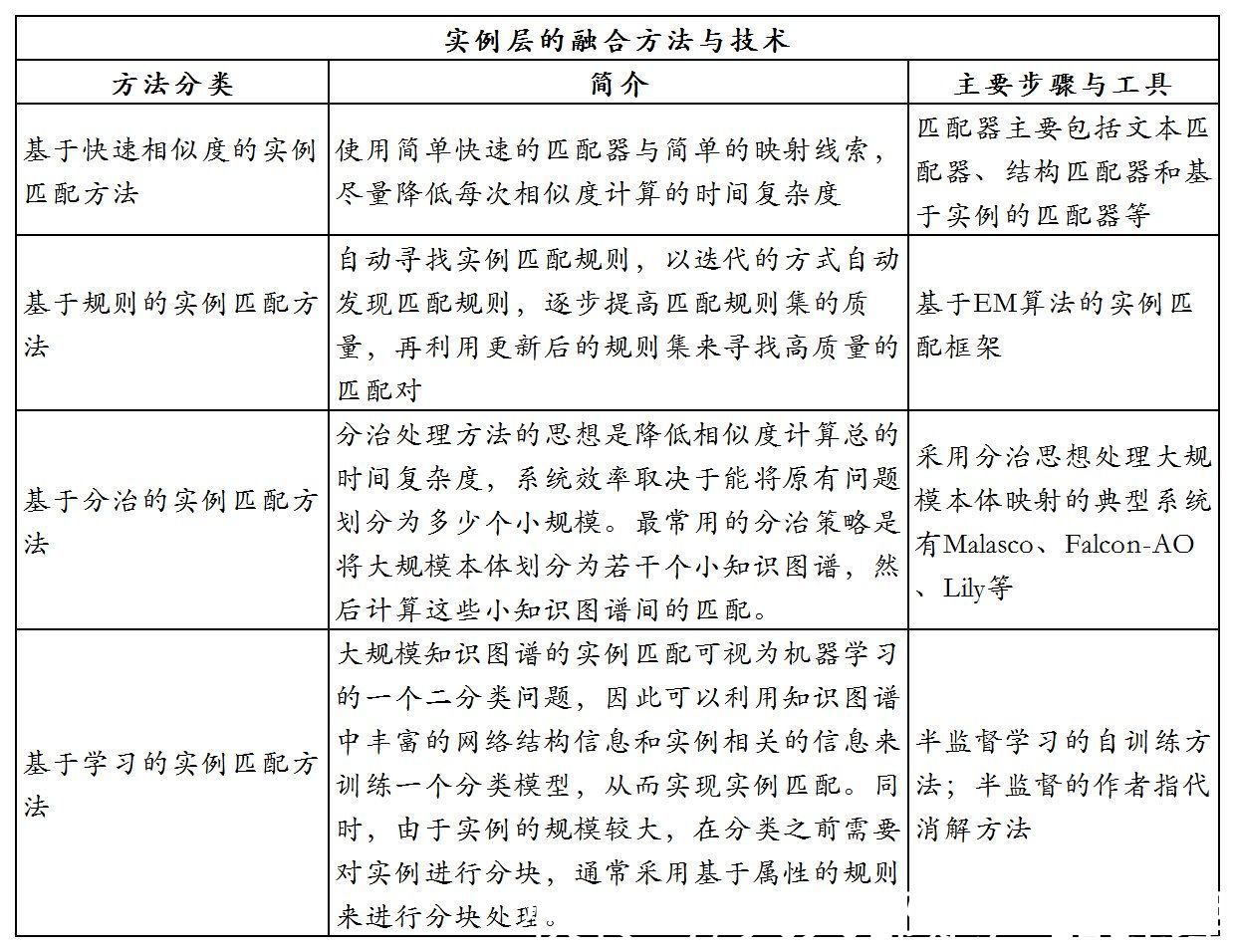
不同的本体映射的方法使用的技术不同,但过程基本是相似的。
- 导入待映射的本体:不一定统一本体语言,但映射成分需方便获取。
- 发现映射:利用一定的算法,如计算概念间的相似度等,寻找异构本体间的联系,然后根据这些联系建立异构本体间的映射规则。
- 表示映射:将这些映射合理地表示起来,根据映射的类型,借助工具将发现的映射合理表示和组织。
文章插图
八、知识图谱推理、知识统计与图挖掘通过知识表示,我们确定了知识以什么样的方式组织、表示和储存,使人类和计算机有了认识和使用知识图谱的基础;知识抽取则是从各种已有的数据库,专业知识和互联网上文本、表格等。
提取出我们关心的数据,并通过各种方法爬取,清洗,将原本结构化、半结构化、非结构化的各种非图谱数据变为图谱中可用的、结构化的图谱数据,相当于建成了基本的知识图谱。
建立了知识图谱后,为了实现不同系统间的的知识图谱的交互,让不同图谱对应到统一的本体和实例,需要进行知识图谱融合,知识融合极大的拓展了知识图谱的规模和应用场景。
通过以上三步,基本上就构建了有一定规模和实用性,可以实现不同系统间交互的知识图谱,即实现了数据的从无到有,从有到有用的过程。
下一步就是使用知识图谱,通过各种计算与分析从大数据中获取价值,进而进一步支持语义搜索,智能问答,辅助分析等应用场景。
从知识图谱构建到应用的中间一步,就是知识图谱推理、知识统计与图挖掘。
先说知识统计与图挖掘,其实就是传统意义上的数据统计与挖掘,只不过数据是知识图谱,而图相对树、链表等又是比较复杂的,尤其是知识图谱规模较大,有时寻找特定数据或关联数据要耗费大量的时间和算力。
查询又是知识图谱中最常见的计算,比如要查询某一个实例及其关联信息,RDF三元组中可以将其转变为对于关系型数据库的查询。
而对RDF图模型或者图数据库如Neo4J来说,这就是查询符合条件的一部分节点和关系,即子图查询,比如搜索“水泥是由什么组成的”,就是搜索“水泥”以及所有与其存在“组成”关系(或者与其他组成同义词,如“原材料”,“用于建造”等)的节点所构成的图,使用的算法如深度优先搜索或广度优先搜索等图算法。
同时还可以对图的特征进行统计,比如有向图中指向某个节点的边有多少(入度),该节点指向其他节点的边有多少(出度),节点在图中重要地位的中心度等等。
比如统计图谱中某一家公司与其他公司的到期未偿还债务关系多少(属于“到期未偿还”关系的边和节点的多少),按此来选择一批信用不良的公司,或者某些出入度离群的点,是否存在刷单情况等等,将图谱用于异常检测。
还有一种很常见的情况,就是对图谱中多个节点关系进行关联分析,比如侦破金融里的团队诈骗,往往一个诈骗团队有非常复杂的关系网,可以通过图谱查找多个账户之间的转账关系,或者与可以账户关系密切的账户。
其中常用的方法有路径查询、距离计算,输出结果为节点及节点间边 的距离和边的集合(路径)。
或者对某一个节点或事件做时序分析,观察事件发展中都涉及那些团体和事件,常见的方法如时序分析。
知识统计与图挖掘是对图谱中已有知识的查询、统计和展示,通过明细数据的展示,或者聚合成更高维度的数据来发掘价值,通常是得到新的结论,但不会拓展知识图谱中已有的数据,从知识图谱的角度来说是没有产生新的知识。
而知识推理则是根据已有的知识,按照某种规则或者策略,产生新的知识(新的三元组)。
举个前面提到的例子,知识图谱中存在<砂石,组成,水泥>和<水泥,组成,混凝土>两个三元组,通过知识推理,可以得到<砂石,组成,混凝土>,即通过一定的知识推理得到未知的事实与关系。
知识推理有很多应用,如知识问答就可以通过知识推理来实现,或者可以补全一部分知识图谱,检测与推理内容不一致的节点。这些一方面可以改正知识图谱的质量,修复一些明显的错误,另一方面在知识问答中可以推出一些新的结论和回答。
- 基础层|B端决策类产品|关键信息密度提升设计
- 小米12|小米 Civi 产品经理证实:没有小米 12 青春版了
- 具有性价|不到20元 这五款小米产品香爆了
- |售价高达4999元!OPPO“黑科技”产品亮相,苹果直呼内行
- find x|姜文、久石让两位大咖助力,Find X5发布会到底有多少重磅产品?
- OPPO|OPPO最科幻产品!OPPO Air Glass智能眼镜限量上市:4999元
- 龙芯|天翼云与龙芯完成产品兼容适配 加速国产化云平台发展
- 产品|O2O 生鲜 SaaS 创业记·市场篇(四)
- 中国消费者报|智能汽车市场竞争的“入场券”:电子元器件正成为产品缺陷主因
- |用户体验两手抓 这家汽车机器人公司已为首款产品铺好路