知识|产品视角下的知识图谱构建流程与技术理解( 五 )
文章插图
PREFIX部分进行命名空间的声明,使下面查询的书写更为简洁。
RDF中以“?”或者“$”指示变量,在where子句中列出关联的三元组模板(三元组中允许存在变量,所以称为模板),而select子句指示要查询的变量。
对应到上述这个例子,查询的是学生姓名,年龄以及选修的课程,OPTIONAL关键字是可选算子,指的是在这个算子覆盖范围的查询语句是可选的,有年龄则返回年龄。
filter是过滤算子,指的是这个算子覆盖范围的查询语句可以用来过滤查询结果,整句的意思是如果有年龄,则年龄必须大于25岁。
查询语句可以写的很复杂,可以层层嵌套,求并集等各种运算来实现复杂的业务逻辑。
最后说一下RDF的存储,三元组形式简单,可以简化为一张三列的表,进而存储在关系型数据库(如Mysql)中,也可以存储在专门的RDF数据库中,如RDF4J。
RDF4J是Eclipse基金会旗下的开源孵化项目,功能包括RDF数据的解析、存储、推理和查询等。
RDF4J本身提供内存和磁盘两种RDF存储机制,支持全部的SPARQL查询和更新语言,可以使用与访问本地RDF库相同的API访问远程RDF库,支持所有主流RDF数据格式,包括RDF/XML、Turtle、N-Triples等。其实现的查询语言为SPARQL。
六、知识抽取要构建规模庞大的知识图谱,已有的文献或资源数量上肯定是不够的,需要把各种来源的数据中的知识提取出来,并且存储在知识图谱中。
知识抽取是指自动化地从文本中发现和抽取相关信息,并将多个文本碎片中的信息进行合并,将非结构化数据转换为结构化数据,包括某一特定领域的模式、实体关系或RDF三元组。
具体来说,数据的来源有结构化数据、半结构化数据、非结构化数据等,分别对于了不同的抽取方法。
而具体抽取的内容也包括实体抽取(命名实体识别)、事件抽取、关系抽取、共指消解(搞清句子中代词的指代对象)。
知识抽取的数据来源中,非结构化数据占比最高。
非结构化数据其实就是自由文本,比如新闻、论文、政策等,而面向非结构化数据的抽取涉及到机器学习和NLP等。
半结构化数据占比也很大,其数据形式不符合关系型数据库或其他形式的数据表形式结构,但又包含标签或其他标记来分离语义元素并保持记录和数据字段的层次结构,比如表格、列表等。
目前的知识抽取中,百科类数据、网页数据是重要的半结构化数据来源。
结构化数据往往是企业的业务系统中的数据,常常用于垂直领域知识图谱的抽取,比如从MySql中抽取成为RDF,因为关系型数据和RDF都是一种结构化数据,所以通常可以通过一定的规则从一种数据映射到另一种数据,目前已经有一些成熟的工具和规则。
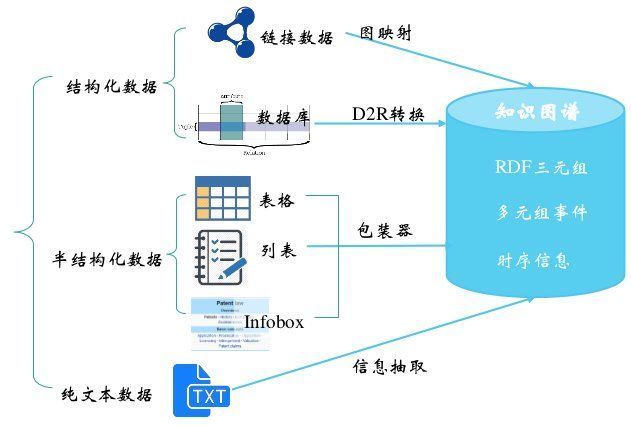
文章插图
图:知识来源及抽取方法
面向非结构化数据的知识抽取,主要包括实体抽取、关系抽取和时间抽取。
实体抽取是从文本中抽取实体信息元素,包括人名、组织机构名、地理位置、时间、日期、字符值和数值等,就是在抽取知识图谱中的各个点,是知识图谱最基本的单元,也是很多自然语言处理问题的基础。
针对实体抽取,目前已经有了很多很多方法,大致分为基于规则的方法、基于统计模型的方法和基于深度模型的方法。
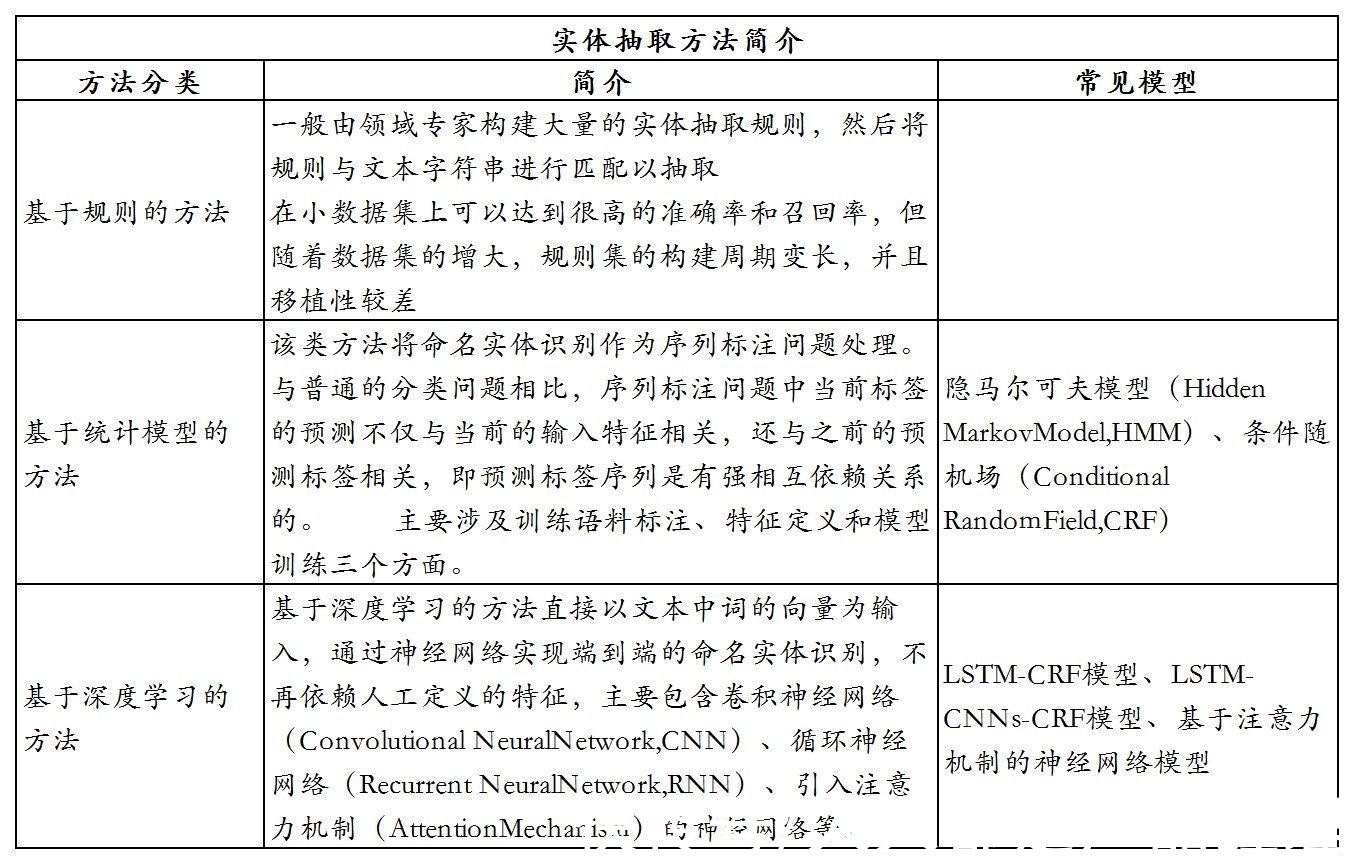
文章插图
关系抽取是从文本中抽取出两个或多个实体之间的语义关系,与实体识别关系密切,主要有以下几类方法:
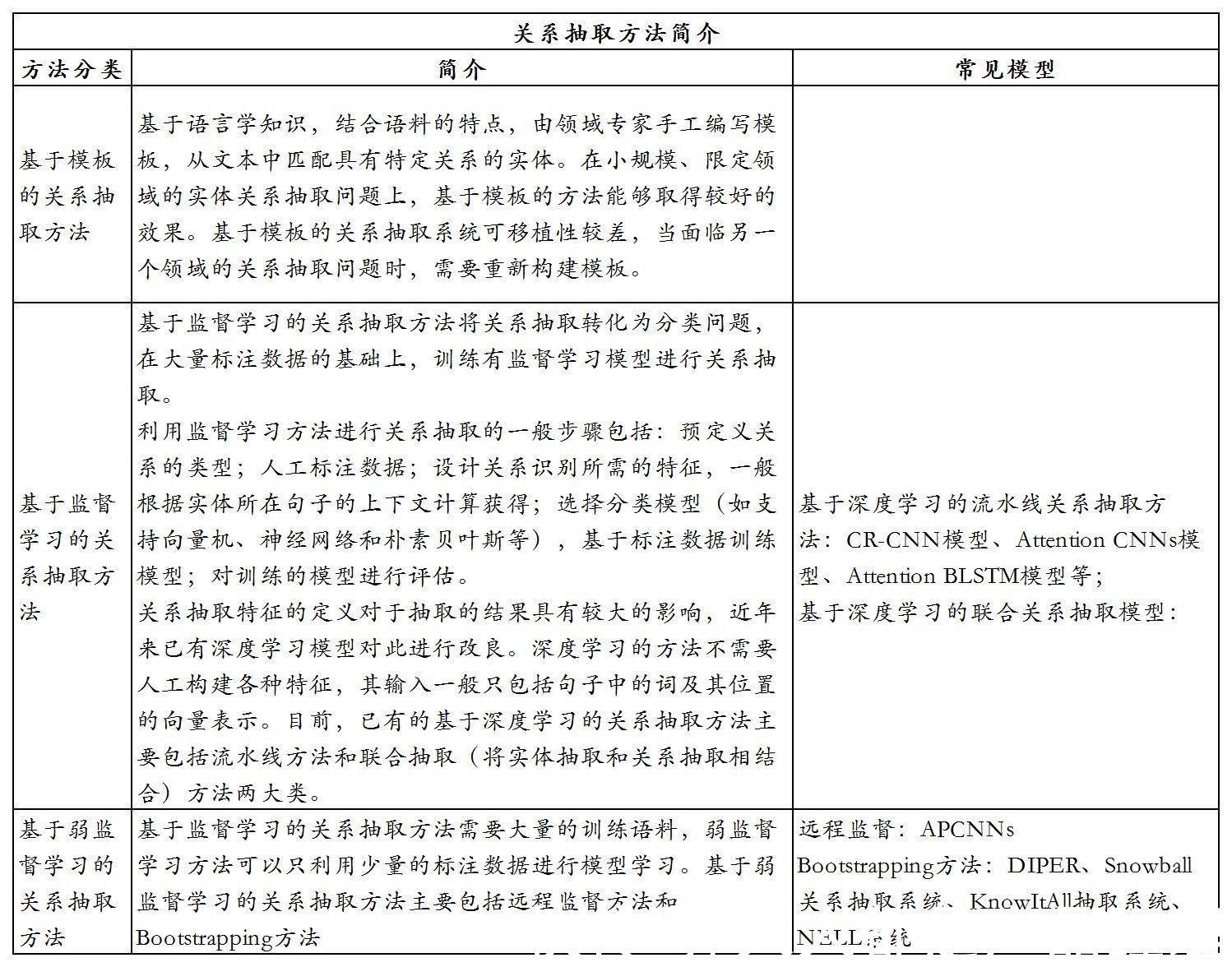
文章插图
事件抽取是指从自然语言文本中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等,如下图:
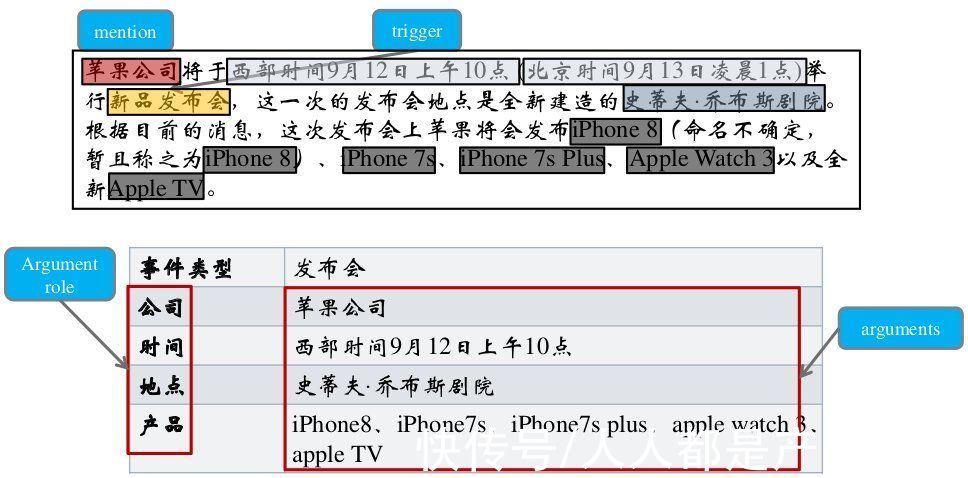
文章插图
图:事件抽取
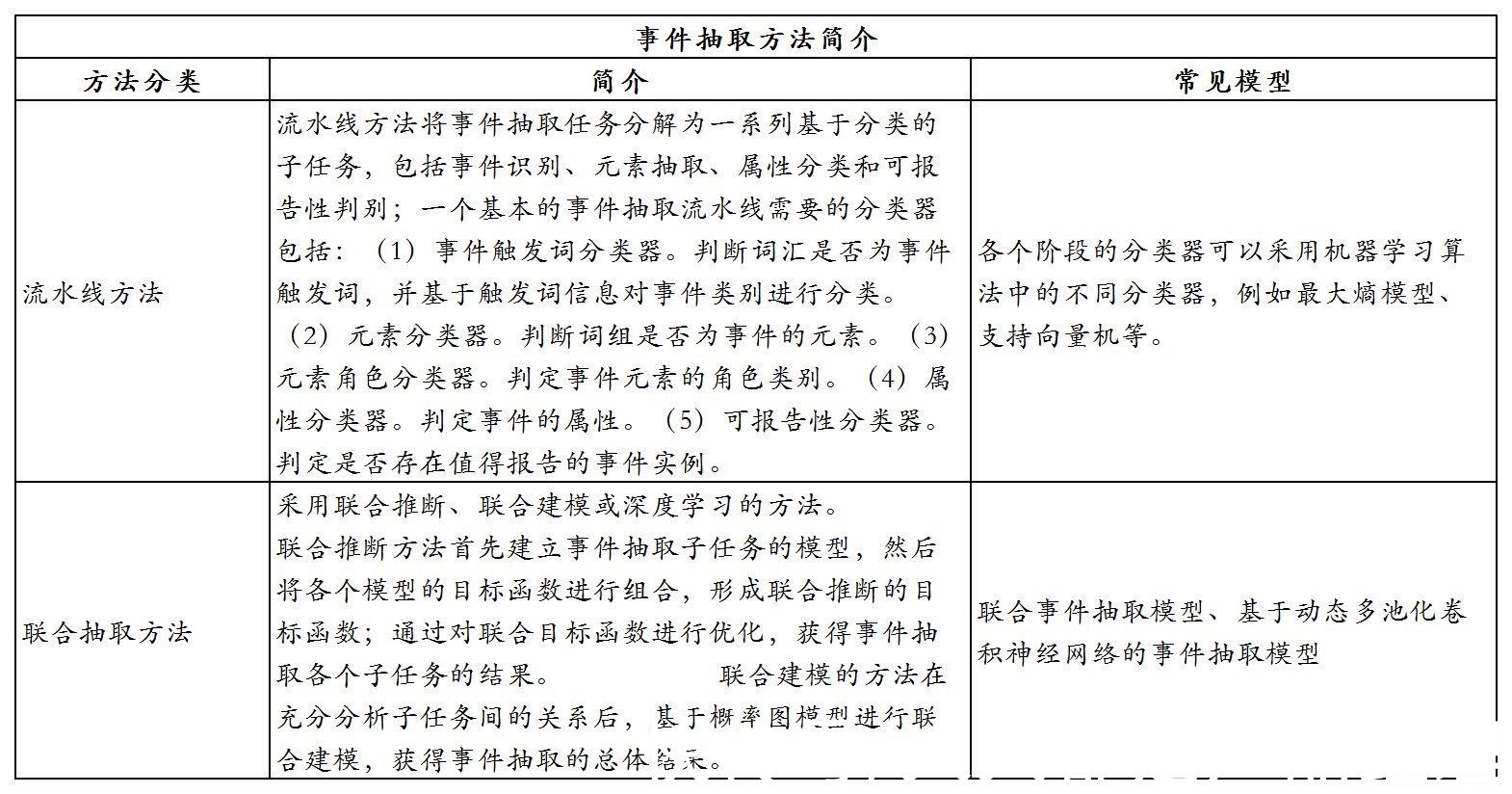
文章插图
半结构化数据抽取主要是从网页中提取,一般通过包装器实现,包装器是能够将数据从HTML网页中抽取出来,并将它们还原为结构化数据的软件程序。
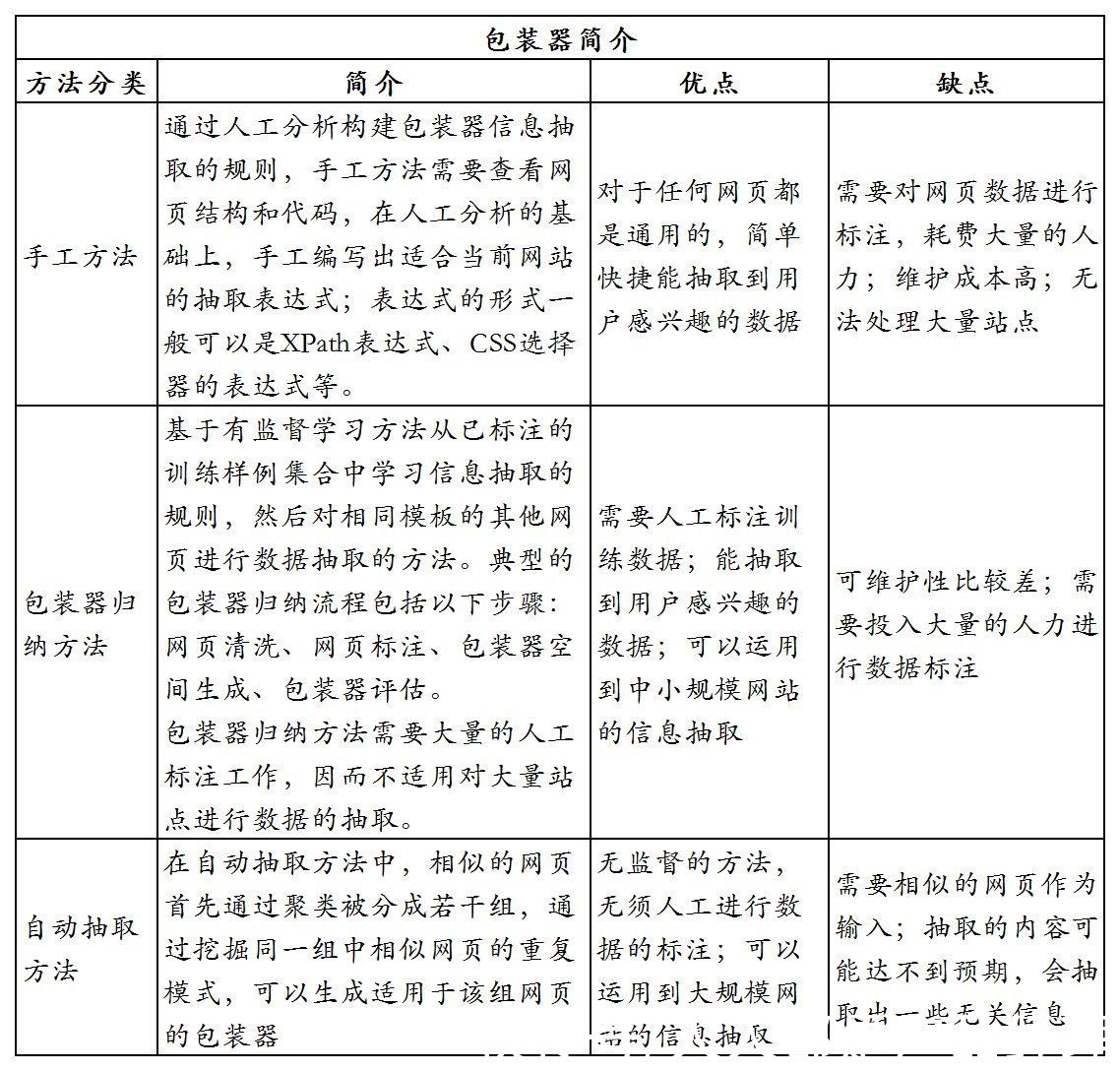
文章插图
结构化的数据抽取一般是按照规则映射,W3C的RDB2RDF工作组于2012年发布了两个推荐的RDB2RDF映射语言:DM(Direct Mapping,直接映射)和R2RML。
直接映射规范定义了一个从关系数据库到RDF图数据的简单转换,将关系数据库表结构和数据直接转换为RDF图,关系数据库的数据结构直接反映在RDF图中,基本规则包括:
- 基础层|B端决策类产品|关键信息密度提升设计
- 小米12|小米 Civi 产品经理证实:没有小米 12 青春版了
- 具有性价|不到20元 这五款小米产品香爆了
- |售价高达4999元!OPPO“黑科技”产品亮相,苹果直呼内行
- find x|姜文、久石让两位大咖助力,Find X5发布会到底有多少重磅产品?
- OPPO|OPPO最科幻产品!OPPO Air Glass智能眼镜限量上市:4999元
- 龙芯|天翼云与龙芯完成产品兼容适配 加速国产化云平台发展
- 产品|O2O 生鲜 SaaS 创业记·市场篇(四)
- 中国消费者报|智能汽车市场竞争的“入场券”:电子元器件正成为产品缺陷主因
- |用户体验两手抓 这家汽车机器人公司已为首款产品铺好路