深入浅出Spark(二):血统(DAG)( 五 )
 文章插图
文章插图
DAGScheduler 创建最后一个 Stage:stage2
到此为止 , 我们的向导大人几乎跑断了腿、以首尾倒置的顺序对整片地形进行了地毯式搜查 , 最终将地形划分为 3 块战略区域(Stage) 。 那么问题来了 , 向导大人划分出的 3 块区域 , 有啥用呢?DAGScheduler 他老人家马不停蹄地这么跑 , 到底图啥?前面我们提到 , DAGScheduler 的核心职责 , 是将抽象的 DAG 计算图转换为具体的、可并行计算的分布式任务 。 回溯 DAG、创建 Stage , 只是这个核心职责的第一步 , DAGScheduler 以 Stage(TaskSet)为粒度进行任务调度 , 伙同 TaskScheduler、SchedulerBackend 等一众大佬运筹帷幄、调兵遣将 。 不过 , 毕竟本篇的主题是 DAG , 到 Spark 调度系统的核心还有些距离 , 因此这里咱们暂且挖个坑 , 后面再单独开篇(Spark 调度系统)专门讲述几位大佬之间的趣事逸闻 。 填坑之路漫漫其修远兮 , 吾将上下而挖坑 。
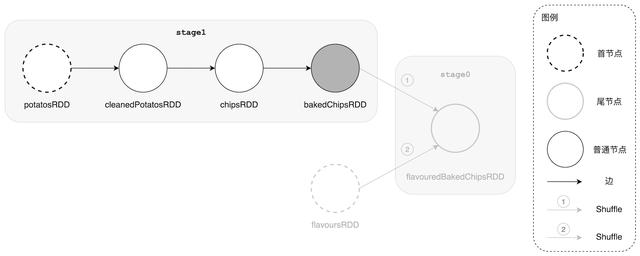
咱们来回顾一下向导大人的心路历程 , 首先 , DAGScheduler 沿着 DAG 的尾节点一路北上 , 并沿途判断每一个 RDD 节点的 dependencies 属性 。 之后 , 如果判定 RDD 的 dependencies 属性是 NarrowDependency , 则 DAGScheduler 继续向前回溯;若 RDD 的依赖是 ShuffleDependency , DAGScheduler 便开启“三招一套”的招式 , 创建 Stage、注册 Stage 并继续向前回溯 。 由此可见 , 何时切割 DAG 并生成新的 Stage 由 RDD 的依赖类型决定 , 当且仅当 RDD 的依赖是 ShuffleDependency 时 , DAGScheduler 才会新建 Stage 。
喜欢刨根问底的您一定会问:“DAGScheduler 怎么知道 RDD 的依赖类型到底是哪一个?他怎么判别 RDD 的依赖是窄依赖还是 ShuffleDependency?”要回答这个问题 , 我们就还得回到 RDD 的 5 大属性上 , 不过这次出场的是 partitioner 。 还记得这个属性吗?partitioner 是 RDD 的分区器、定义了 RDD 数据分片的分区规则 , 它决定了 RDD 的数据分片在分布式集群中如何分布 , 这个属性至关重要 , 后面介绍 Shuffle 的时候我们还会提到它 。 DAGScheduler 正是通过 partitioner 来判定每个 RDD 的依赖类型 , 具体来说 , 如果子 RDD 的 partitioner 与父 RDD 的 partitioner 一致 , 那么 DAGScheduler 判定子 RDD 对父 RDD 的依赖属于窄依赖;相反 , 如果两者 partitioner 不一致 , 也即分区规则不同(分区规则不同则意味着一定存在数据的“重洗牌” , 即 Shuffle) , 那么 DAGScheduler 判定子对父的依赖关系是 ShuffleDependency 。 到此 , DAGScheduler 对于 DAG 的划分逻辑可以暂且告一段落 。 原理说了 , 例子举了 , 还缺啥?对!代码 。
Show me the code古人云:“光说不练假把式” , 我们用一个小例子来展示一下 DAG 与 Stage 的关系 。 还是用上篇《内存计算的由来 —— RDD》中的 WordCount 依样画葫芦 , 文件内容如下 。
 文章插图
文章插图
示例文件内容
代码也没变:
 文章插图
文章插图
WordCount 示例代码
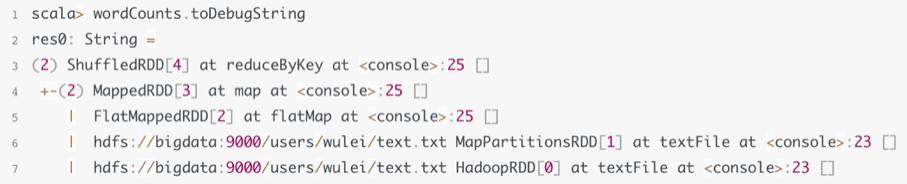
虽然文件内容和代码都没变 , 但是我们观察问题的视角变了 , 这次我们关心的是 DAG 中 Stage 的划分以及 Stage 之间的关系 。 RDD 的 toDebugString 函数让我们可以一览 DAG 的构成以及 Stage 的划分 , 如下图所示 。
 文章插图
文章插图
DAG 构成及 Stage 划分
在上图中 , 从第 3 行往下 , 每一行表示一个 RDD , 很显然 , 第 3 行的 ShuffledRDD 是 DAG 的尾节点 , 而第 7 行的 HadoopRDD 是首节点 。 我们来观察每一行字符串打印的特点 , 首先最明显地 , 第 4、5、6、7 行的前面都有个制表符(Tab) , 与第 3 行有个明显的错位 , 这表示第 3 行的 ShuffledRDD 被划分到了一个 Stage(记为 stage0) , 而第 4、5、6、7 行的其他 RDD 被划分到了另外一个 Stage(记为 stage1) , 且 stage0 对 stage1 有依赖关系 。 假设第 7 行下面的 RDD 字符串打印有两个制表符 , 即与第 7 行产生错位 , 那么第 7 行下面的 RDD 则被划到了新的 Stage , 以此类推 。
- 英产血统 纯正音色 RHA TrueConnect2真无线蓝牙耳机
- 零基础入门Spark groupBy操作(Java版)
- 唯品会实时平台架构-Flink、Spark、Storm
- 从0到1进行Spark history分析
- 零进程入门Spark keyBy操作(Java版)