深入浅出Spark(二):血统(DAG)( 三 )
值得一提的是 , 对于相同的计算场景 , 采用不同算子实现带来的执行性能可能会有天壤之别 , 在后续的性能调优篇咱们再具体问题具体分析 。 好吧 , 坑越挖越多 , 列位看官您稍安勿躁 , 咱们按照 FIFO 的原则 , 先来说说刚刚才提到的、还热乎的 DAGScheduler 。
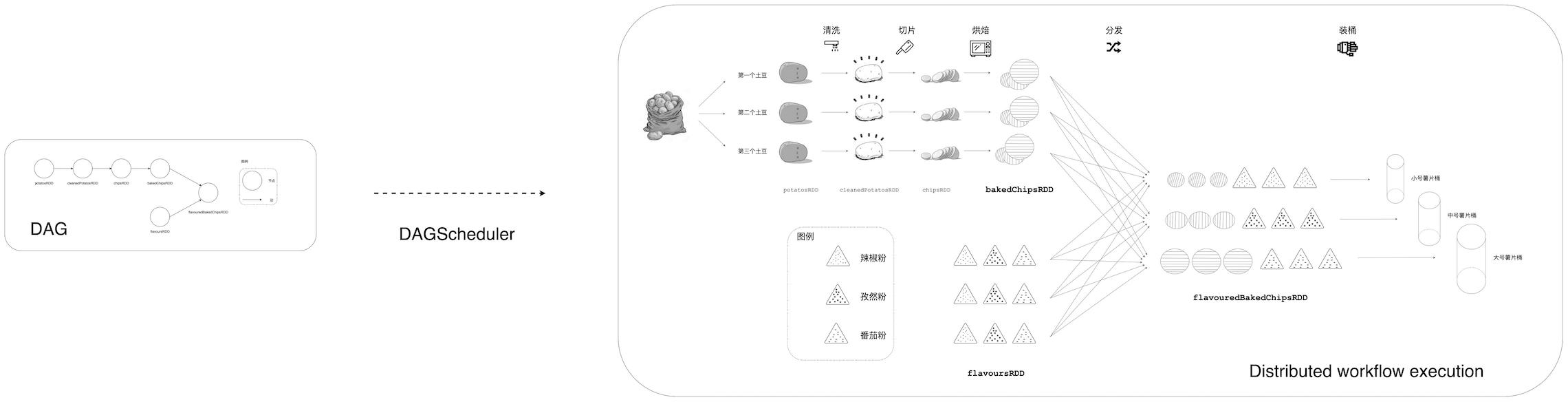
DAGScheduler —— DAG 的向导官DAGScheduler 是 Spark 分布式调度系统的重要组件之一 , 其他组件还包括 TaskScheduler、MapOutputTracker、SchedulerBackend 等 。 DAGScheduler 的主要职责是根据 RDD 依赖关系将 DAG 划分为 Stages , 以 Stage 为粒度提交任务(TaskSet)并跟踪任务进展 。 如果把 DAG 看作是 Spark 作业的执行路径或“战略地形” , 那么 DAGScheduler 就是这块地形的向导官 , 这个向导官负责从头至尾将地形摸清楚 , 根据地形特点排兵布阵 。 更形象地 , 回到土豆工坊的例子 , DAGScheduler 要做的事情是把抽象的土豆加工 DAG 转化为工坊流水线上一个个具体的薯片加工操作任务 。 那么问题来了 , DAGScheduler 以怎样的方式摸索“地形”?如何划分 Stages?划分 Stages 的依据是什么?更进一步 , 将 DAG 划分为 Stages 的收益有哪些?Spark 为什么要这么做?
 文章插图
文章插图
DAGScheduler 的核心职责
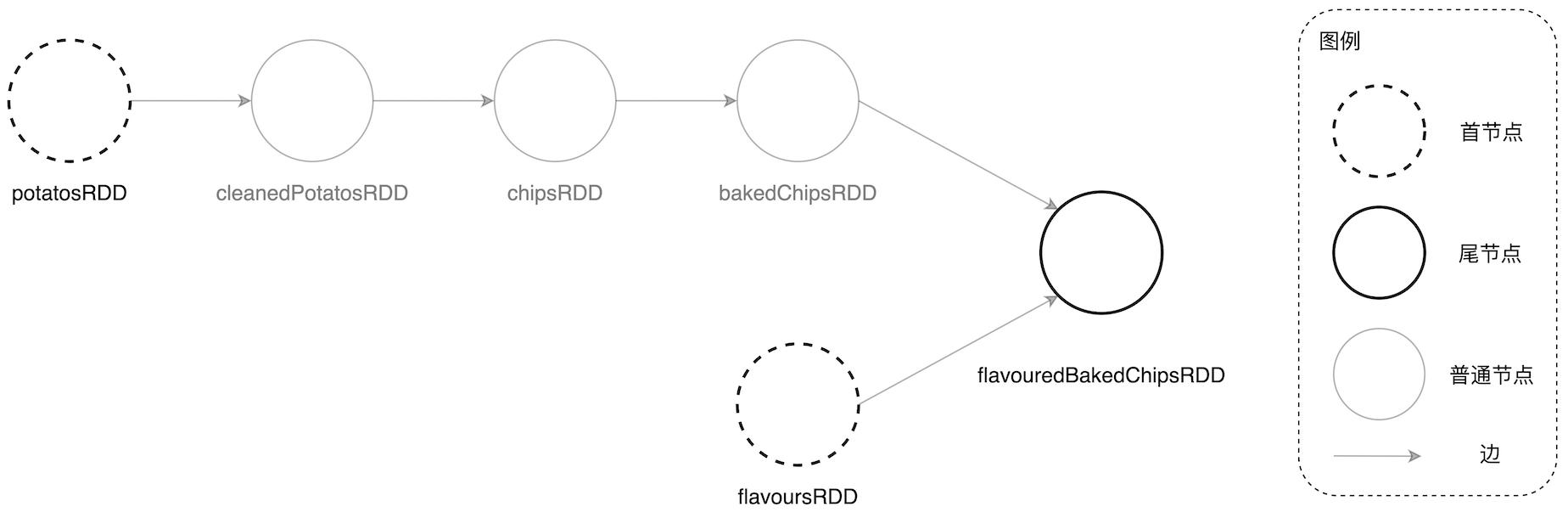
为了回答这些问题 , 我们需要先对于 DAG 的“首”和“尾”进行如下定义:在一个 DAG 中 , 没有父 RDD 的节点称为首节点 , 而没有子 RDD 的节点称为尾节点 。 还是以土豆工坊为例 , 其中首节点有两个 , 分别是 potatosRDD 和 flavoursRDD , 而尾节点是 flavouredBakedChipsRDD 。
 文章插图
文章插图
DAG 中首与尾的定义
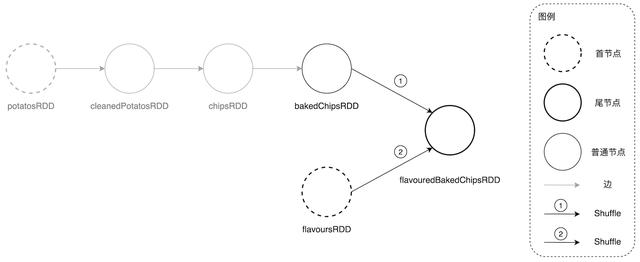
DAGScheduler 在尝试探索 DAG“地形”时 , 是以首尾倒置的方式从后向前进行 。 具体说来 , 对于土豆工坊的 DAG , DAGScheduler 会从尾节点 flavouredBakedChipsRDD 开始 , 根据 RDD 依赖关系依次向前遍历所有父 RDD 节点 , 在遍历的过程中以 Shuffle 为边界划分 Stage 。 Shuffle 的字面意思是“洗牌” , 没错 , 就是扑克游戏中的洗牌 , 在大数据领域 Shuffle 引申为“跨节点的数据分发” , 指的是为了实现某些计算逻辑需要将数据在集群范围内的不同计算节点之间定向分发 。 在绝大多数场景中 , Shuffle 都是当之无愧的“性能瓶颈担当” , 毫不客气地说 , 有 Shuffle 的地方 , 就有性能优化的空间 。 关于 Spark Shuffle 的原理和性能优化技巧 , 后面我们会单独开一篇来专门探讨 。 在土豆工坊的 DAG 中 , 有两个地方发生了 Shuffle , 一个是从 bakedChipsRDD 到 flavouredBakedChipsRDD 的计算 , 另一个是从 flavoursRDD 到 flavouredBakedChipsRDD 的计算 , 如下图所示 。
 文章插图
文章插图
土豆工坊 DAG 中的 Shuffle
各位看官不禁要问:DAGScheduler 如何判断 RDD 之间的转换是否会发生 Shuffle 呢?那位看官说了:“前文书说了半天算子是 RDD 之间转换的关键 , 莫不是根据算子来判断会不会发生 Shuffle?”您还真猜错了 , 算子与 Shuffle 没有对应关系 。 就拿 join 算子来说 , 在大部分场景下 , join 都会引入 Shuffle;然而在 collocated join 中 , 左右表数据分布一致的情况下 , 是不会发生 Shuffle 的 。 所以您看 , DAGScheduler 还真不能依赖算子本身来判断发生 Shuffle 与否 。 要回答这个问题 , 咱们还是得回到前文书《内存计算的由来 —— RDD》中介绍 RDD 时提到的 5 大属性 。
属性名 成员类型 属性含义 dependencies 变量 生成该 RDD 所依赖的父 RDD compute 方法 生成该 RDD 的计算接口 partitions 变量 该 RDD 的所有数据分片实体 partitioner 方法 划分数据分片的规则 preferredLocations 变量 数据分片的物理位置偏好
- 英产血统 纯正音色 RHA TrueConnect2真无线蓝牙耳机
- 零基础入门Spark groupBy操作(Java版)
- 唯品会实时平台架构-Flink、Spark、Storm
- 从0到1进行Spark history分析
- 零进程入门Spark keyBy操作(Java版)