深入浅出Spark(二):血统(DAG)( 二 )
 文章插图
文章插图
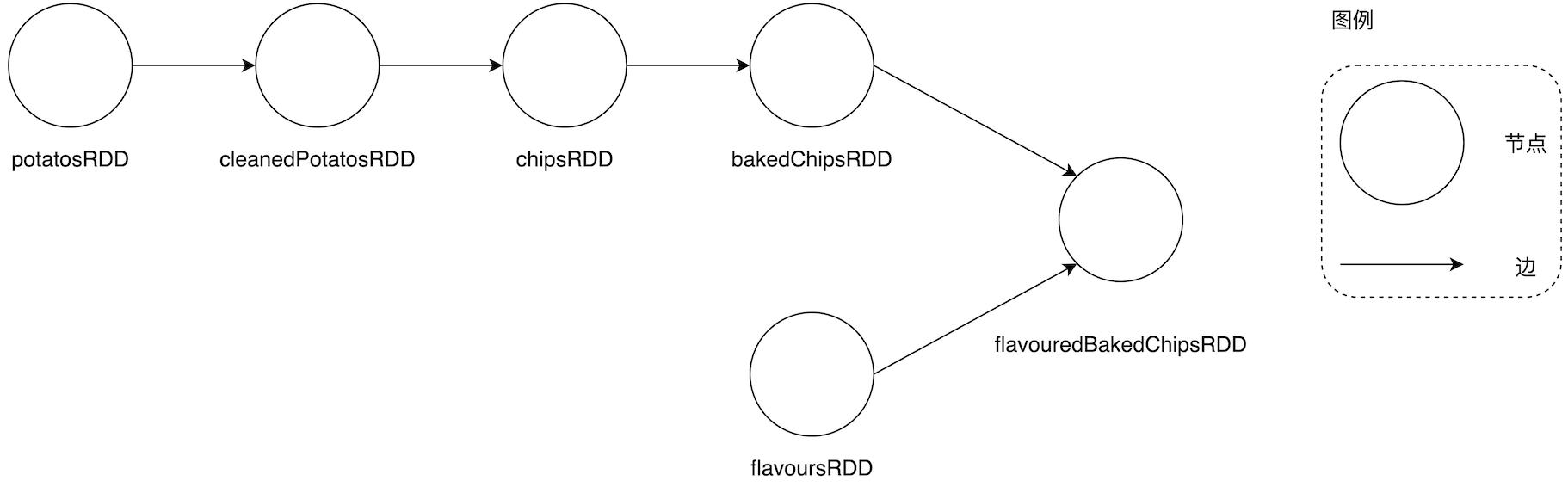
多个分支的DAG
在上一篇 , 我们探讨了Spark Core 内功心法的第一要义 —— RDD , 这一篇 , 咱们来说说内功心法的第二个秘诀 —— DAG 。
RDD 算子 —— DAG 的边在上一篇《内存计算的由来 —— RDD》最后 , 我们以 WordCount 为例展示不同 RDD 之间转换而形成的 DAG 计算图 。 通读代码 , 从开发的角度来看 , 我们发现 DAG 构成的关键在于 RDD 算子调用 。 不同于 Hadoop MapReduce , Spark 以数据为导向提供了丰富的 RDD 算子 , 供开发者灵活地排列组合 , 从而实现多样化的数据处理逻辑 。 那么问题来了 , Spark 都提供哪些算子呢?
 文章插图
文章插图
数据来源:
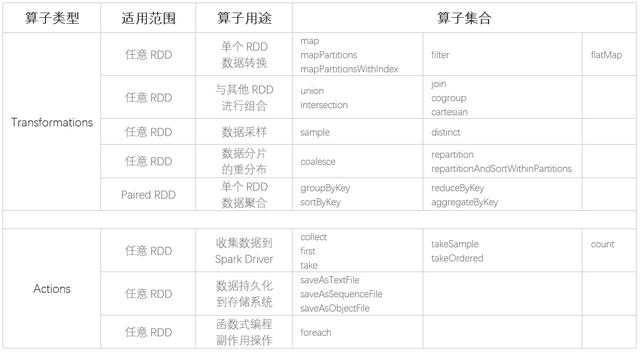
从表格中我们看到 , Spark 的 RDD 算子丰富到让人眼花缭乱的程度 , 对于初次接触 Spark 的同学来说 , 如果不稍加归类 , 面对多如繁星的算子还真是无从下手 。 Apache Spark 官网将 RDD 算子归为 Transformations 和 Actions 两种类型 , 这也是大家在各类 Spark 技术博客中常见的分类方法 。 为了说明 Transformations 和 Actions 算子的本质区别 , 我们必须得提一提 Spark 计算模型的“惰性计算”(Lazy evaluation , 又名延迟计算)特性 。
掌握一个新概念最有效的方法之一就是找到与之相对的概念 —— 与“惰性计算”相对 , 大多数传统编程语言、编程框架的求值策略是“及早求值”(Eager evaluation) 。 例如 , 对于我们熟悉的 C、C++、Java 来说 , 每一条指令都会尝试调度 CPU、占用时钟周期、触发计算的执行 , 同时 , CPU 寄存器需要与内存通信从而完成数据交换、数据缓存 。 在传统编程模式中 , 每一条指令都很“急”(Eager) , 都恨不得自己马上被调度到“前线”、参与战斗 。
惰性计算模型则不然 —— 具体到 Spark , 绝大多数 RDD 算子都很“稳”、特别能沉得住气 , 他们会明确告诉 DAGScheduler:“老兄 , 你先往前走着 , 不用理我 , 我先绷会儿、抽袋烟 。 队伍的前排是我们带头大哥 , 没有他的命令 , 我们不会贸然行动 。 ”有了惰性计算和及早求值的基本了解 , 我们再说回 Transformations 和 Actions 的区别 。 在 Spark 的 RDD 算子中 , Transformations 算子都属于惰性求值操作 , 仅参与 DAG 计算图的构建、指明计算逻辑 , 并不会被立即调度、执行 。 惰性求值的特点是当且仅当数据需要被物化(Materialized)时才会触发计算的执行 , RDD 的 Actions 算子提供各种数据物化操作 , 其主要职责在于触发整个 DAG 计算链条的执行 。 当且仅当 Actions 算子触发计算时 ,DAG 从头至尾的所有算子(前面用于构建 DAG 的 Transformations 算子)才会按照依赖关系的先后顺序依次被调度、执行 。
说到这里 , 各位看官不禁要问:Spark 采用惰性求值的计算模型 , 有什么优势吗?或者反过来问:Spark 为什么没有采用传统的及早求值?不知道各位看官有没有听说过“延迟满足效应”(又名“糖果效应”) , 它指的是为了获取长远的、更大的利益而自愿延缓甚至放弃目前的、较小的满足 。 正所谓:“云想衣裳花想容 , 猪想发福人想红” 。 Spark 这孩子不仅天资过人 , 小小年纪竟颇具城府 , 独创的内功心法意不在赢得眼下的一招半式 , 而是着眼于整个武林 。 扯远了 , 我们收回来 。 笼统地说 , 惰性计算为 Spark 执行引擎的整体优化提供了广阔的空间 。 关于惰性计算具体如何帮助 Spark 做全局优化 —— 说书的一张嘴表不了两家事 , 后文书咱们慢慢展开 。
还是说回 RDD 算子 , 除了常见的按照 Transformations 和 Actions 分类的方法 , 笔者又从适用范围和用途两个维度为老铁们做了归类 , 毕竟人类的大脑喜欢结构化的知识 , 官网上一字长蛇阵的罗列总是让人看了昏昏欲睡 。 有了这个表格 , 我们就知道 *ByKey 的操作一定是作用在 Paired RDD 上的 , 所谓 Paired RDD 是指 Schema 明确区分(Key, Value)对的 RDD , 与之相对 , 任意 RDD 指的是不带 Schema 或带任意 Schema 的 RDD 。 从用途的角度来区分 RDD 算子的归类相对比较分散 , 篇幅的原因 , 这里就不一一展开介绍 , 老铁们各取所需吧 。
- 英产血统 纯正音色 RHA TrueConnect2真无线蓝牙耳机
- 零基础入门Spark groupBy操作(Java版)
- 唯品会实时平台架构-Flink、Spark、Storm
- 从0到1进行Spark history分析
- 零进程入门Spark keyBy操作(Java版)