从0到1进行Spark history分析
作者: JasonCeng
出处:
一、总体思路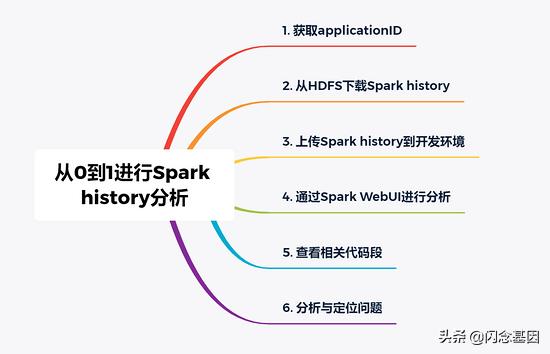 文章插图
文章插图
以上是我在平时工作中分析spark程序报错以及性能问题时的一般步骤 。 当然 , 首先说明一下 , 以上分析步骤是基于企业级大数据平台 , 该平台会抹平很多开发难度 , 比如会有调度日志(spark-submit日志)、运维平台等加持 , 减少了开发人员直接接触生成服务器命令行的可能 , 从物理角度进行了硬控制 , 提高了安全性 。
下面我将带领大家从零到一 , 从取日志 , 到在Spark WebUI进行可视化分析相关报错、性能问题的方法 。
二、步骤(一)获取applicationID1.从调度日志获取一般企业级大数据平台会相对重视日志的采集 , 这不仅有助于事后对相关问题、现象的分析;同时也是相关审计环节的要求 。
我们知道 , spark的调度是通过spark-submit执行触发的 , 每一次spark-submit都会有对应的applicationID生成 , 所以 , 一般我们可以在调度日志中可以找到本次调度的applicationID 。
2.从运维平台获取企业级大数据平台为了减少开发、运维人员直接通过ftp、putty、xshell等工具直连生产服务器 , 避免误操作等风险发生 , 一般会提供一个运维平台 , 在页面上便可直接查看到job粒度的作业运行情况 , 以及其唯一标志applicationID , 缩短了开发、运维人员获取applicationID的“路径” , 减少了机械性的步骤 。
(二)从HDFS下载Spark history我们假设我们的大数据平台把spark history保存到了HDFS的 /sparkJobHistory/ 目录下 , 下面我们来看看具体如何获取我们对应applicationID的spark history 。
1.命令行下载HDFS文件hadoop fs -get /sparkJobHistory/applicationID_xxxxx_1-meta localfilehadoop fs -get /sparkJobHistory/applicationID_xxxxx_1-part1 localfile2.HUE工具下载HDFS文件我们使用租户登录HUE工具 , 进入到File Browser页面 , 并通过页面上的目录访问按钮进入到sparkJobHistory目录下 , 然后在搜索框中输入applicationID, 就可以看到该applicationID对应的spark history(meta和part1两个文件)显示在了页面中 , 勾选并下载 , 便可以将spark history下载到我们本地 。
(三)上传Spark history到开发环境接下来我们要做的工作就是将从生产上获取到的spark history放到我们开发环境上 , 以便进行后续分析 。
1.命令行推送spark history到HDFS上首先我们需要将从生产下载到本地的spark history上传到我们测试环境的任意一个节点上 , 这里我们将其上传到测试环境01节点的 ${WORK_ROOT}/etluser/tmp/spark_history/applicationID_xxxxx/ 路径下 , 接下来在测试环境命令行执行以下命令 , 将spark history上传到HDFS:
hadoop fs -put ${WORK_ROOT}/etluser/tmp/spark_history/applicationID_xxxxx/* /sparkJobHistory/2.HUE工具上传spark history到HDFS上这个步骤和我们在生产HUE类似 , 首先使用租户登录到测试环境HUE , 然后进入File Browser的 /sparkJobHistory/ 路径下 , 点击Upload按钮 , 上传spark history到该路径下即可 。
(四)Spark WebUI进行分析1.搜索applicationID进入Spark WebUI页面 , 在搜索框输入applicationID , 即可筛选出该applicationID的spark history 。
2.进行stage可视化分析点击该App ID进去即可看到该applicationID的每一个Job详细运行情况;点击进一个Job , 即可看到该Job的DAG图 , 以及对应的stage运行情况;点击进一个stage , 即可看到该stage下所有的task运行情况 。 通过每一个页面上的运行耗时、GC时间、input/output数据量大小等 , 根据这些信息即可分析出异常的task、stage、job 。
- 微软|外媒:微软将对Windows 10界面进行彻底改进 已招兵买马
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- AMP Robotics募资5500万美元 开发AI对可回收物进行分拣
- Mozilla正在对Firefox设计进行更新工作
- iPhone 13仍将有四款型号 Pro版屏幕进行重大升级
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- 将OPPO美学进行到底 Reno5 Pro+外观设计一览
- 苹果操控专利曝光:未来或允许Mac用户在投影面上进行触摸输入
- 亲子陪伴好去处 华为应用市场2020嘉年华火爆进行中
- 软通智慧又有了什么成绩?携手百度进行安徽的无人驾驶5G路测