深入浅出Spark(二):血统(DAG)
专题介绍
2009 年 , Spark 诞生于加州大学伯克利分校的 AMP 实验室(the Algorithms, Machines and People lab) , 并于 2010 年开源 。 2013 年 , Spark 捐献给阿帕奇软件基金会(Apache Software Foundation) , 并于 2014 年成为 Apache 顶级项目 。
如今 , 十年光景已过 , Spark 成为了大大小小企业与研究机构的常用工具之一 , 依旧深受不少开发人员的喜爱 。 如果你是初入江湖且希望了解、学习 Spark 的“小虾米” , 那么 InfoQ 与 FreeWheel 技术专家吴磊合作的专题系列文章——《深入浅出 Spark:原理详解与开发实践》一定适合你!
本文系专题系列第二篇 。
书接前文 , 在上一篇《内存计算的由来 —— RDD》 , 我们从“虚”、“实”两个方面介绍了RDD 的基本构成 。 RDD 通过dependencies 和compute 属性首尾相连构成的计算路径 , 专业术语称之为Lineage —— 血统 , 又名DAG(Directed Acyclic Graph , 有向无环图) 。 一个概念为什么会有两个称呼呢?这两个不同的名字又有什么区别和联系?简单地说 , 血统与DAG 是从两个不同的视角出发 , 来描述同一个事物 。 血统 , 侧重于从数据的角度描述不同RDD 之间的依赖关系;DAG , 则是从计算的角度描述不同RDD 之间的转换逻辑 。 如果说RDD 是Spark 对于分布式数据模型的抽象 , 那么与之对应地 , DAG 就是Spark 对于分布式计算模型的抽象 。
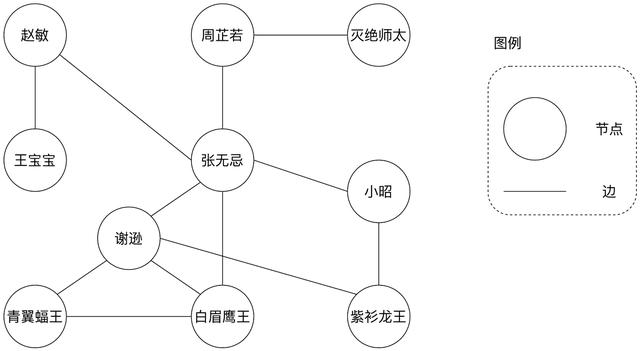
顾名思义 , DAG 是一种“图” , 图计算模型的应用由来已久 , 早在上个世纪就被应用于数据库系统(Graph databases)的实现中 。 任何一个图都包含两种基本元素:节点(Vertex)和边(Edge) , 节点通常用于表示实体 , 而边则代表实体间的关系 。 例如 , 在“倚天屠龙”社交网络的好友关系中 , 每个节点表示一个具体的人 , 每条边意味着两端的实体之间建立了好友关系 。
 文章插图
文章插图
倚天屠龙社交网络
在上面的社交网络中 , 好友关系是相互的 , 如张无忌和周芷若互为好友 , 因此该关系图中的边是没有指向性的;另外 , 细心的同学可能已经发现 , 上面的图结构是有“环”的 , 如张无忌、谢逊、白眉鹰王构成的关系环 , 张无忌、谢逊、紫衫龙王、小昭之间的关系环 , 等等 。 像上面这样的图结构 , 术语称之为“无向有环图” 。 没有比较就没有鉴别 , 有向无环图(DAG)自然是一种带有指向性、不存在“环”结构的图模型 。 各位看官还记得土豆工坊的例子吗?
 文章插图
文章插图
土豆工坊DAG
在上面的土豆加工DAG 中 , 每个节点是一个个RDD , 每条边代表着不同RDD 之间的父子关系 —— 父子关系自然是单向的 , 因此整张图是有指向性的 。 另外我们注意到 , 整个图中是不存在环结构的 。 像这样的土豆加工流水线可以说是最简单的有向无环图 , 每个节点的入度(Indegree , 指向自己的边)与出度(Outdegree , 从自己出发的边)都是1 , 整个图看下来只有一条分支 。
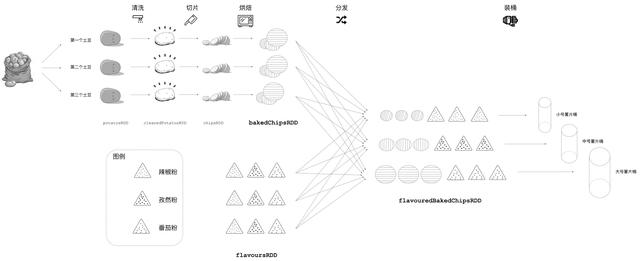
不过 , 工业应用中的Spark DAG 要比这复杂得多 , 往往是由不同RDD 经过关联、拆分产生多个分支的有向无环图 。 为了说明这一点 , 我们还是拿土豆工坊来举例 , 在将“原味”薯片推向市场一段时间后 , 工坊老板发现季度销量直线下滑 , 老板心急如焚、一筹莫展 。 此时有人向他建议:“何不推出更多风味的薯片 , 来迎合大众的多样化选择” , 于是老板一声令下 , 工人们对流水线做了如下改动 。
 文章插图
文章插图
土豆工坊高级生产线
与之前相比 , 新的流程增加了3 条风味流水线 , 用于分发不同的调料粉 。 新流水线上的辣椒粉被分发到收集小号薯片的流水线、孜然粉分发到中号薯片流水线 , 相应地 , 番茄粉分发到大号薯片流水线 。 经过改造 , 土豆工坊现在可以生产3 种风味、不同尺寸的薯片 , 即麻辣味的小号薯片、孜然味的中号薯片和番茄味的大号薯片 。 如果我们用flavoursRDD 来抽象调味品的话 , 那么工坊新作业流程所对应的DAG 会演化为如下所示带有2 个分支的有向无环图 。
- 英产血统 纯正音色 RHA TrueConnect2真无线蓝牙耳机
- 零基础入门Spark groupBy操作(Java版)
- 唯品会实时平台架构-Flink、Spark、Storm
- 从0到1进行Spark history分析
- 零进程入门Spark keyBy操作(Java版)