深入浅出Spark(二):血统(DAG)( 四 )
RDD 的 5 大属性及其含义
其中第一大属性 dependencies 又可以细分为 NarrowDependency 和 ShuffleDependency , NarrowDependency 又名“窄依赖” , 它表示 RDD 所依赖的数据无需分发 , 基于当前现有的数据分片执行 compute 属性封装的函数即可;ShuffleDependency 则不然 , 它表示 RDD 依赖的数据分片需要先在集群内分发 , 然后才能执行 RDD 的 compute 函数完成计算 。 因此 , RDD 之间的转换是否发生 Shuffle , 取决于子 RDD 的依赖类型 , 如果依赖类型为 ShuffleDependency , 那么 DAGScheduler 判定:二者的转换会引入 Shuffle 。 在回溯 DAG 的过程中 , 一旦 DAGScheduler 发现 RDD 的依赖类型为 ShuffleDependency , 便依序执行如下 3 项操作:
- 沿着 Shuffle 边界的子 RDD 方向创建新的 Stage 对象
- 把新建的 Stage 注册到 DAGScheduler 的 stages 系列字典中 , 这些字典用于存储、记录与 Stage 有关的状态和元信息 , 以备后用
- 沿着当前 RDD 的父 RDD 遵循广度优先搜索算法继续回溯 DAG
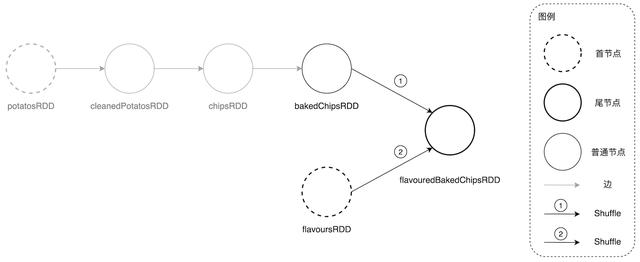
 文章插图
文章插图DAGScheduler 回溯 DAG 过程当中遇到 ShuffleDependency 时的主要操作流程
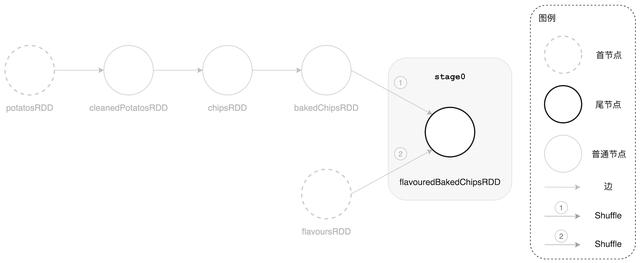
 文章插图
文章插图DAGScheduler 沿着尾节点回溯并划分出 stage0
在完成第一个 Stage(stage0)的创建和注册之后 , DAGScheduler 先沿着 bakedChipsRDD 方向继续向前回溯 。 在沿着这条路向前跑的时候 , 我们的这位 DAGScheduler 向导官惊喜地发现:“我去!这一路上一马平川、风景甚好 , 各个驿站之间什么障碍都没有 , 交通甚是顺畅 , 真是片好地形!”—— 沿路遇到的所有 RDD(bakedChipsRDD , chipsRDD , cleanedPotatosRDD , potatosRDD)的依赖类型都是 NarrowDependency 。
【深入浅出Spark(二):血统(DAG)】在回溯完毕时 , DAGScheduler 同样会重复上述 3 个步骤 , 根据 DAGScheduler 以 Shuffle 为边界划分 Stage 的原则 , 沿途的所有 RDD 都划归为同一个 Stage , 暂且记为 stage1 。 值得一提的是 , Stage 对象的 rdd 属性对应的数据类型是 RDD[] , 而不是 List[RDD[]] 。 对于一个逻辑上包含多个 RDD 的 Stage 来说 , 其 rdd 属性存储的是路径末尾的 RDD 节点 , 具体到我们的案例中就是 bakedChipsRDD 。
 文章插图
文章插图DAGScheduler 沿着 bakedChipsRDD 方向回溯并划分出 stage1
勤勤恳恳的 DAGScheduler 在成功创建 stage1 之后 , 依然不忘初心、牢记使命 , 继续奔向还未探索的路线 。 从上图中我们清楚地看到整块地形还剩下 flavoursRDD 方向的路径没有纳入 DAGScheduler 的视野范围 。 咱们的这位 DAGScheduler 向导官记性相当得好 , 早在划分 stage0 的时候 , 他就用小本子(栈)记下:“此路口有分叉 , 先沿着 bakedChipsRDD 方向走 , 然后再回过头来沿着 flavoursRDD 的方向探索 。 切记 , 切记!”此时 , 向导大人拿出之前的小本子 , 用横线把 bakedChipsRDD 方向的路径划掉 —— 表示该方向路径已探索过 , 然后沿着 flavoursRDD 方向大踏步地走下去 。 一脚下去 , 发现:“我去!到头儿了!” , 然后紧接着执行一贯的“三招一套”流程 —— 创建 Stage、注册 Stage、继续回溯 。 随着 DAGScheduler 创建最后一个 Stage:stage2 , 地形上的所有路径都已探索完毕 。
- 英产血统 纯正音色 RHA TrueConnect2真无线蓝牙耳机
- 零基础入门Spark groupBy操作(Java版)
- 唯品会实时平台架构-Flink、Spark、Storm
- 从0到1进行Spark history分析
- 零进程入门Spark keyBy操作(Java版)