不以英语为中心,百种语言互译,FB开源首个单一多语言MT模型( 二 )
 文章插图
文章插图
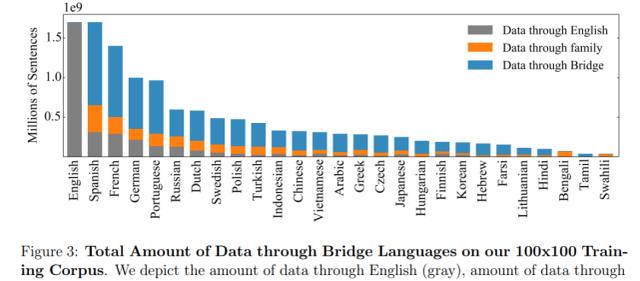
训练语料库中桥梁语言的数据量 。
反向翻译策略
为了对低翻译质量的语料匮乏语言补充并行数据 , 研究者使用了反向翻译(back-translation)策略 。 举例而言 , 如果想要训练一个汉语 - 法语翻译模型 , 则应该首先训练一个法语到汉语的模型 , 并翻译所有的单一法语数据以创建合成的反向翻译汉语 。 研究者发现 , 反向翻译策略在大规模语言转换中特别有效 , 比如将亿万个单语句子转换为并行数据集 。
具体而言 , 研究者使用反向翻译策略作为已经挖掘语言对方向训练的补充 , 将合成反向翻译数据添加到挖掘的并行数据中 。 此外 , 研究者还使用反向翻译策略为以往无人监督的语言对方向创建数据 。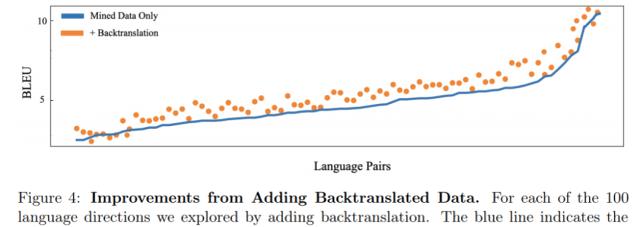 文章插图
文章插图
仅挖掘数据 VS 反向翻译策略加持形成的语言对比较 。
总的来说 , 与单靠挖掘数据上的训练相比 , 桥梁策略和反向翻译数据的结合将 100 个反向翻译方向上的性能提升了 1.7BLEU 。 有了鲁棒性更强、高效和高质量的数据集 , 这就为构建和扩展多对多(many-to-many)语言模型打下了坚实基础 。
在语言对无可用训练数据的零样本设置下 , 研究者也发现了令人印象深刻的结果 。 举例而言 , 如果一个模型在法语 - 英语和德语 - 瑞典语语料库中进行训练 , 则可以实现法语和瑞典语的零样本转译 。 在多对多模型必须实现非英语方向之间零样本转译的设置下 , 则该模型要比以英语为中心的多语言模型好得多 。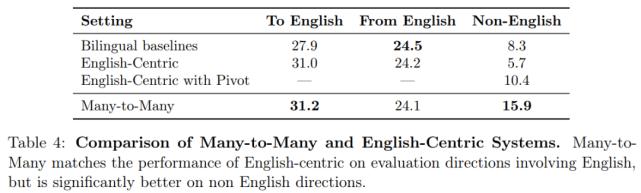 文章插图
文章插图
多对多和以英语为中心语言模型的比较 。 在包含英语的评估方向上 , 多对多模型与以英语为中心模型的性能相当 , 但在非英语方向上的性能要好得多 。
高速度高质量地将 MMT 模型扩展到 150 亿个参数
多语言翻译中的一个挑战是:单一模型必须从多种不同语言和多种脚本中捕获信息 。 为了解决这个问题 , 研究者发现扩展模型容量并添加特定于语言的参数的显著优势 。 扩展模型大小对于高资源语言对尤其有用 , 因为它们具有训练额外模型容量的大部分数据 。
最终 , 当将模型规模密集扩展到 120 亿个参数时 , 研究者在所有语言方向上平均获得了 1.2BLEU 的平均提升 。 此后 , 进一步密集扩展所带来的回报逐渐减少 。 密集扩展和特定于语言的稀疏参数(32 亿个)的组合使得能够创建一个具有 150 亿个参数的更优模型 。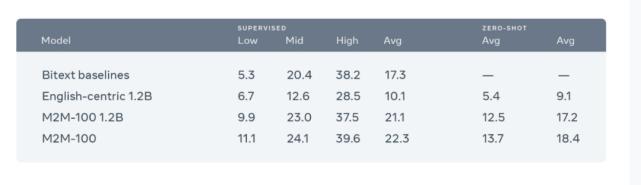 文章插图
文章插图
研究者将其模型与双语基准和以英语为中心的多语言模型进行比较 。 研究者从具有 24 个编码器层和 24 个解码器层的 12 亿个参数基线开始 , 然后将以英语为中心的模型与 M2M-100 模型进行比较 。 接下来 , 如果将 12B 参数与 12 亿个参数进行比较 , 将获得 1.2BLEU 的提高 。
为了扩展模型的大小 , 研究者增加了 Transformer 网络中的层数以及每层的宽度 。 研究者发现大型模型收敛迅速并且训练高效 。 值得注意的是 , 这是第一个利用 Fairscale(一个新的专门设计用于支持管道和张量并行性的 PyTorch 库)的多对多系统 。
研究者建立了通用的基础架构 , 以通过将模型并行到 Fairscale 中来容纳无法在单个 GPU 上安装的大型模型 , 并且是基于 ZeRO 优化器、层内模型并行性和管道模型并行性构建的 , 以训练大型模型 。
但是仅将模型扩展到数十亿个参数还不够 。 为了能够将此模型应用于生产 , 需要以高速训练尽可能高效地扩展模型 。 例如 , 许多现有研究使用多模型集成 , 其中训练了多个模型并将其用于同一个源句以生成翻译 。 为了降低训练多个模型所需的复杂度和计算量 , 研究者探索了多源自集成技术 , 该技术可将源句子翻译成多种语言以提升翻译质量 。 此外 , 研究者还在该研究中引入了 LayerDrop 和 Depth-Adaptive , 以用常规主干和一些语言特定参数集来共同训练模型 。
这种方法对于多对多模型非常有效 , 因为它提供了一种按照语言对或语言族来拆分模型的自然方法 。 通过将模型容量的密集扩展与特定于语言的参数结合 , 该研究提供了大型模型的优势以及学习不同语言的特定层的能力 。
研究者表示 , 他们将继续通过整合此类前沿研究来提升模型 , 探索方法以负责任地部署 MT 系统 , 并创建更专业的计算架构将模型投入实际使用 。
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- SPI协议详解
- Facebook新AI模型实现直接从非英语语言翻译到另一种非英语语言
- 数字联接新动能|数字化转型想要成功,就要以“人”为中心
- 鲸鱼外教培优吴昊:小班课会成为线上少儿英语机构的主流形态
- 英语启蒙APP那么多,互联网“大厂”出品的有啥不一样?
- 图说|图说英语:新概念英语默写本,值得收藏
- 不以盈利为目|顺风车已“死”
- 手机拨号键上的“#”“*”英语怎么读?
- 学习编程语言是否对于数学和英语的要求比较高