不以英语为中心,百种语言互译,FB开源首个单一多语言MT模型
机器之心报道
机器之心编辑部
Facebook AI 近日开源了多语言机器翻译模型 M2M-100 , 该模型不依赖以英语为中心的数据 , 可以实现 100 种语言之间的相互翻译 。 文章插图
文章插图
机器翻译(MT)打破了人类之间的语言障碍 。 如今 , 平均每天需要在 Facebook 新闻提要上提供 200 亿次翻译 , 这得益于低资源机器翻译领域的发展以及评估翻译质量的最新进展 。
典型的 MT 系统需要为每种语言和每种任务构建单独的 AI 模型 , 但这种方法无法在 Facebook 上进行有效推广 , 因为人们在数十亿个帖子中发布超过 160 种语言的内容 。 先进的多语言处理系统能够同时处理多种语言 , 但由于依赖英语数据来弥合源语言和目标语言之间的差距 , 在准确性上会有所折中 。
因此 , 我们需要一种可以翻译任何语言的多语言机器翻译(multilingual machine translation, MMT)模型 , 从而更好地服务于全球近三分之二不使用英语的人们 。
近日 , Facebook 根据多年对 MT 的研究宣布实现了一个重要的里程碑:首个单一的大规模 MMT 模型 , 该模型可以实现 100x100 个语言对的直接翻译 , 而不依赖以英语为中心的数据 。 这个单一的多语言模型表现得和传统双语模型一样好 , 并且比以英语为中心的多语言模型提高了 10 个 BLEU 点 。
具体而言 , 通过使用新的挖掘策略来创建翻译数据 , 该研究构建了首个真正的多对多数据集 。 该数据集拥有 100 种语言的 75 亿个句子 。 研究者使用可扩展技术来建立具有 150 亿个参数的通用模型 , 它从相关语言中捕获信息 , 并反映出更加多样化的语言文字和词法 。 目前 , 这项研究已经开源 。 文章插图
文章插图
论文主页:
GitHub 地址:
挖掘语言方向
构建多对多 MMT 模型的最大障碍之一是:在任意方向翻译大量的高质量句子对(也称为平行句) , 而不需要涉及英语 。 从中文到英文、从英文到法文的翻译要比从法文到中文容易得多 。 更重要的是 , 模型训练所需的数据量会随着语言数量的增加而呈二次增长 。 例如 , 如果每个方向需要 10M 句子对 , 我们需要挖掘 10 种语言的 1B 句子对和 100 种语言的 100B 句子对 。
该研究建立了多样化的多对多 MMT 数据集:跨越 100 种语言的 75 亿句子对 。 通过结合互补的数据挖掘资源:ccAligned、ccMatrix 以及 LASER 。 此外该研究还创建了一个新的 LASER 2.0 并改进了 fastText 语言识别 , 提高了挖掘质量 , 并开放了源代码的训练和评估脚本 。 所有的数据挖掘资源都利用公开数据集 , 并且都是开源的 。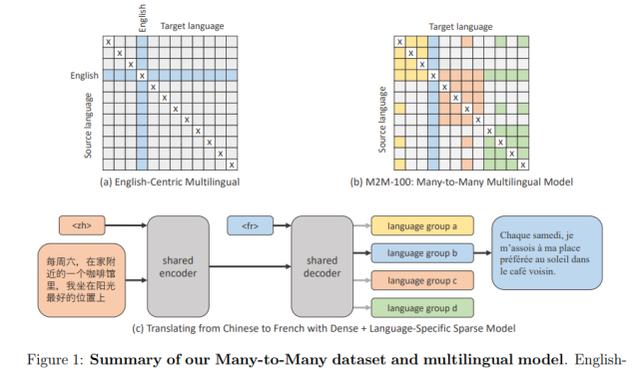 文章插图
文章插图
多对多数据集和多语言模型示意图 。
尽管如此 , 即使使用了像 LASER 2.0 这样先进的底层技术 , 为 100 种不同语言的任意对(或是 4450 种可能的语言对)挖掘大规模训练数据仍然需要大量的计算 。 为了使这种数据挖掘规模更容易管理 , 该研究首先关注翻译请求最多的语言 。 因此 , 以最高质量的数据和最大数量的数据为优先挖掘方向 。 该研究避开了在统计上很少需要翻译的方向 , 比如冰岛语到尼泊尔语翻译 , 或者是僧伽罗语到爪哇语的翻译 。
桥梁语言策略
接着 , 研究者提出了一种新的桥梁挖掘(bridge mining)策略 , 其中按照语言分类、地域和文化相似性将 100 种语言分成了 14 个语系 。 这样做是因为 , 同一个语系中的人(包含多种语言)往往交流更频繁 , 并将从高质量翻译中收益 。 举例而言 , 一个语系中将涵盖印度境内使用的孟加拉语、印地语、马拉地语、尼泊尔语、泰米尔语和乌尔都语等多种语言 。 研究者系统性地挖掘每个语系中所有可能的语言对 。
为了连通不同语系的语言 , 研究者确定了少量的桥梁语言(bridge language) , 它们通常由每个语系中的 1 至 3 种主要语言构成 。 如上述印度境内所使用的语言中 , 印地语、孟加拉语和泰米尔语是雅利安语的桥梁语言 。 然后 , 研究者挖掘这些桥梁语言所有可能组合的并行训练数据 。 通过这种方法 , 训练数据集最终生成了 75 亿个并行句子 , 对应 2200 个语言方向(direction) 。
【不以英语为中心,百种语言互译,FB开源首个单一多语言MT模型】由于挖掘的数据可以用来训练给定语言对的两个不同方向 , 如 en→fr 和 fr→en , 因此挖掘策略有助于实现高效、稀疏地挖掘 , 从而以最佳的状态覆盖一个模型中的所有 100×100(共计 9900)个方向 。
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- SPI协议详解
- Facebook新AI模型实现直接从非英语语言翻译到另一种非英语语言
- 数字联接新动能|数字化转型想要成功,就要以“人”为中心
- 鲸鱼外教培优吴昊:小班课会成为线上少儿英语机构的主流形态
- 英语启蒙APP那么多,互联网“大厂”出品的有啥不一样?
- 图说|图说英语:新概念英语默写本,值得收藏
- 不以盈利为目|顺风车已“死”
- 手机拨号键上的“#”“*”英语怎么读?
- 学习编程语言是否对于数学和英语的要求比较高