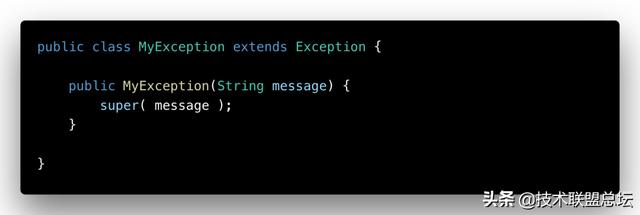
我为什么反对用异常做流程控制?
曲总 技术琐话 文章插图
文章插图 文章插图
文章插图
“懒”是驱动程序员前进的原动力 , 亦是原罪 。
像SSH/M这种基础框架的出现 , 让不少程序员“瘫痪”成了流水线工人 。 以前小心翼翼方能写就的逻辑分支判断 , 演变成了直接丢个异常然后坐等AOP拦截处理 , 此时的拦截器就是个垃圾处理厂 。 这种似乎失控的编码方式 , 让我想到了邪恶的“GoTo”语法 , 很多编程语言里都有它 ,但是都不建议你用它 。 因为邪恶的不是GoTo本身 , 而是滥用GoTo的我们 。
题眼基本表达了我的论点 , 随着本文的深入会对该论点做加一个约束条件 。 现在容我开始论证它~
都说抛异常很重 , 到底重在哪里?
不整虚的 , 我们用测试数据来说话 。 采用OpenJDK的JMH基准测试框架实现 , 设计如下6种测试场景:
- New一个普通的Exception
- New一个普通的不包含堆栈信息的Exception
- New一个普通的自定义对象
- Throw一个普通的Exception
- Throw一个普通的不包含堆栈信息的Exception
- 获取/打印异常的堆栈信息
 文章插图
文章插图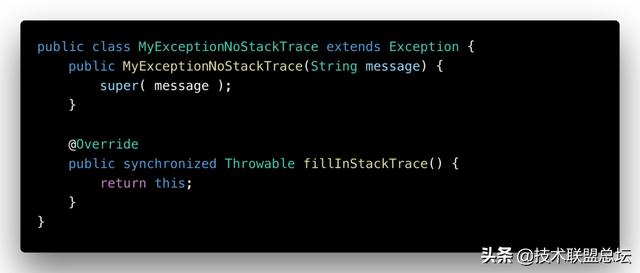 文章插图
文章插图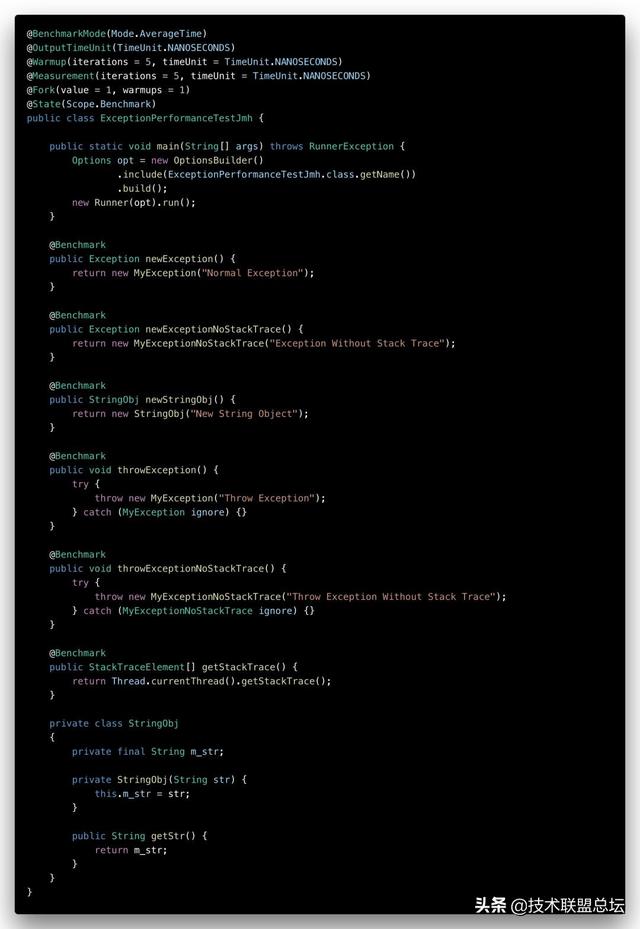 文章插图
文章插图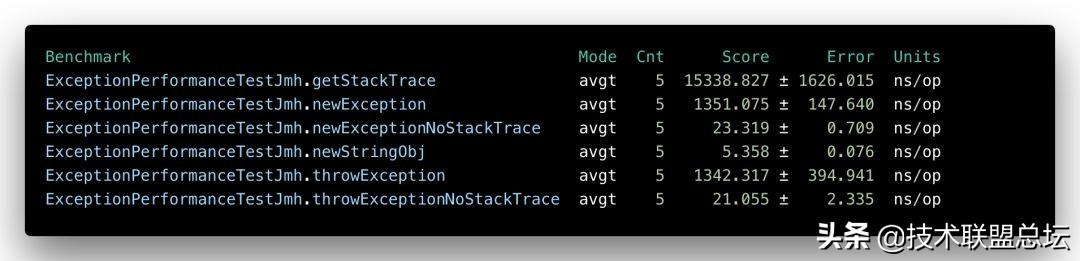 文章插图
文章插图6个场景的benchmark测试报告如上图 。 从结果数字可以看出:耗时最短的是创建自定义对象 , 耗时最长的是获取异常的堆栈信息 。 详细说明几个要点:
--tt-darkmode-color: #FF061F;">250倍 。 所以异常从出生就死在起跑线 。 虽然我们的测试耗时是纳秒级别 , 若从系统接口通常的秒为单位 , 就算30倍也可以忽略不计 。 但是在这里已经可以凸显出异常本身的沉重 。
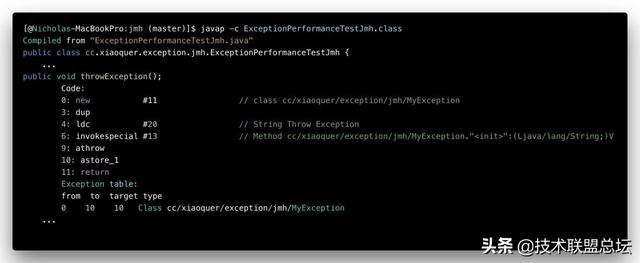
--tt-darkmode-color: #FF061F;">明确概念1:Java中如果不发生异常 , try/catch基本是不会造成任何性能损失的(查看字节码了解异常表) 。 而一旦发生异常 , 除了昂贵的异常填充堆栈成本 , 也就是确认下try block对应异常表记录的起止代码行和异常名称是否一致 。 上测试结果也表明确实会有性能波动 , 但其实很小 。
 文章插图
文章插图明确概念2:对于try block内的代码 , Java会阻止指令重排序一类的内存优化手段 。 所以即使try的性能损耗很小 , 但是我们仍旧建议try block的边界越窄越好 。
明确概念3:try block的范围即使很宽 , 对于堆栈深度来说并无特别影响 。 因为栈帧的深度取决于不同方法之间的调用关系和次数 。
--tt-darkmode-color: #FF061F;">最耗时的操作竟是读取堆栈操作 。
 文章插图
文章插图对Thread::getStackTrace()做个简单说明 。 大家可以看一下JDK源码 , 在当前线程里它等同于
(new Exception()).getStackTrace()
实例化一个异常对象已经够慢了 , 获取异常堆栈数据的耗时竟然达到10倍以上 。 大家想一想不管是自己写的try/catch代码块 , 还是AOP的拦截器 , 是不是都会读取堆栈 , 然后打印到日志里用于排障?
所以异常重不重已经很明确了吧?再贴一遍测试数据感受一下 , 所有的真相都在此图了 。
文章插图代码示例已上传Github
接口设计如何定义异常的边界?
传统的接口设计规范说明会包含几个基本要素:接口名/地址、版本号、请求参数 , 响应参数 。 其中应答的响应码基本都会一一列举并详细说明 , 让调用方简单直观的理解到此接口的服务能力 。
当把控制流程的异常嵌入到接口设计里 , 随之问题就来了:
- 甚少看到有人能够在Javadoc里使用@exception将接口内的异常标注清楚;
- 如何权衡选择正常的应答返回还是抛异常?当接口应答只是true/false的时候 , 抛异常会是个很匪夷所思的设计;
- 当下层方法不断的抛出各种异常 , 然后汇总到拦截器里处理时 , 或者需要对异常拆开做判断 , 再自定义成合理的应答话术;或者将好不容易区分开的不同异常 , 被整合成了“通用系统异常”无法分辨;这时候的拦截器就是个异常中央处理池 , 拆就是hardcode , 不拆就可能是浪费了之前的异常细颗粒度;
- 看不上|为什么还有用户看不上华为Mate40系列来看看内行人怎么说
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 发展|我省要求互联网平台坚持依法合规经营 推动线上经济健康规范发展
- 电信|巴西电信协会及运营商发文 反对限制华为5G
- 页面|流程图怎样画?老板要我帮他做个组织结构图
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 效果|周冬雨化身美妆效果评测员?相比美妆数码宅的我更期待OPPO新机
- 制药领域|为什么AI制药这么火,为什么是现在?