HybridPose:混合表示下的6D对象姿态估计( 四 )
Occlusion-Linemod的基线比较 。 HybridPose大大优于所有基线方法 。 就ADD(-S)精度而言 , 本文的方法将PVNet从40.8提高到79.2 , 提高了94.1% 。 这种增强功能清楚地显示了HybridPose在被遮挡对象上的优势 , 其中看不见的关键点的预测可能很嘈杂 , 可见的关键点可能无法单独为位姿回归提供足够的约束 。 HybridPose还优于Occlusion Linemod上最新的位姿估计器DPOD 67.4% 。 一种解释是基于DPOD的基于渲染的方法在被遮挡的对象上效果较差 , 这是由于在数据扩充和对应计算中难以对遮挡进行建模 。
运行时间 。 在配备16核Intel?Xeon?E5-2637 CPU和GeForce GTX 1080 GPU的台式机上 , HybridPose花费0.6秒来预测中间表示 , 花费0.4秒来回归位姿 。 假设批大小为30 , 则平均处理速度为每秒30帧 , 从而可以进行实时分析 。
3.3 消融实验本文继续进行消融研究 。 表3总结了使用不同的预测中间表示形式的HybridPose的性能 。 由于Linemod上不同方法的性能接近饱和 , 因此本文在此处进行的消融研究基于Occlusion Linemod , 它清楚地揭示了不同预测元素对位姿优化的影响 。 Linemod的消融研究推迟到供应材料 。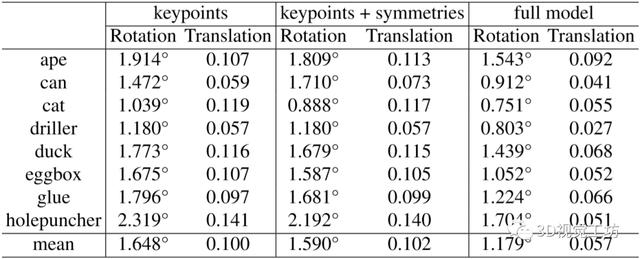 文章插图
文章插图
表3:具有不同中间表示形式的定性评估 。
关键点 。 作为基线方法 , 本文首先仅通过利用关键点信息来估计对象的位姿 。 如表3所示 , 平均绝对旋转误差为1.648度 , 平均相对平移误差为0.100 。
关键点和对称性 。 将对称对应关系添加到关键点会导致旋转组件获得明显的性能提升 。 相对性能提升为3.52% , 并且在所有对象类别中这种改善几乎是一致的 。 一致的改进清楚地表明了对称对应的有效性 。 另一方面 , 使用关键点和使用关键点+对称性的转换误差几乎保持不变 。 一种解释是对称对应只约束三个旋转参数的两个自由度 , 而对平移参数没有约束 。
完整模型 。 将边缘向量添加到关键点和对称对应关系会在旋转和平移估计中显着提高性能 。 旋转和平移的相对性能提升分别为25.85%和44.12% 。 一种解释是 , 边缘矢量在平移和旋转上都提供了更多的约束 。 与关键点相比 , 边缘向量表示平移 , 因为它表示相邻关键点的位移 , 并提供了更多的回归信息 , 因此对平移提供了更多约束 。 结果 , 翻译错误显着降低 。 与仅对旋转提供2个约束的对称对应相比 , 边缘矢量在旋转参数上约束3个自由度 , 从而提高了旋转估计的性能 。 此外 , 改进的旋转估计有助于改进子模块中的GM鲁棒功能 , 以识别关键点预测中的异常值 。
四、总结和未来工作在本文中 , 本文介绍了HybridPose , 这是一种利用关键点 , 边缘向量和对称对应关系的6D姿态估计方法 。 实验表明 , HybridPose具有实时预测功能 , 并且在准确性方面优于当前的最新姿态估计方法 。 HybridPose对遮挡和极端位姿具有鲁棒性 。 将来 , 本文计划将HybridPose扩展为包括更多的中间表示形式 , 例如形状基元 , 法线和平面 。 未来工作的另一个可能方向是在不同表示形式之间加强一致性 , 这是网络培训中的自我监督损失 。
本文仅做学术分享 , 如有侵权 , 请联系删文 。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉 , 即可下载 3D视觉相关资料干货 , 涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向 。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总 , 即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计汇总等 。
下载3
【HybridPose:混合表示下的6D对象姿态估计】在「3D视觉工坊」公众号后台回复:相机标定 , 即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配 , 即可下载独家立体匹配学习课件与视频网址 。
- 降价|iPhone12 mini会跌价到4000出头?果粉表示很期待!
- 麦景图发布全新MA12000旗舰混合式合并式放大器
- 斗鱼和虎牙合并,内部人员表示双方很团结,要联手对抗新敌人
- 美团|美团表示将积极遵守监管规定
- 平台|IBM 混合云平台:企业 2.5倍价值飞跃从哪儿来?
- 福音|一加新机即将发布,看到配置后网友表示:发烧友的福音
- 燕窝|辛巴就燕窝事件发表道歉信,表示将替品牌方进行赔付6198万
- 混合模式改|三分钟学会打造纹理叠加效果
- 刘强东表示干满5年就买房,干了10年的0001号快递员怎样?
- 服务器|TikTok现状如何首席安全官最新表示服务器已与字节跳动分开