TinyML:下一轮人工智能革命( 四 )
 文章插图
文章插图
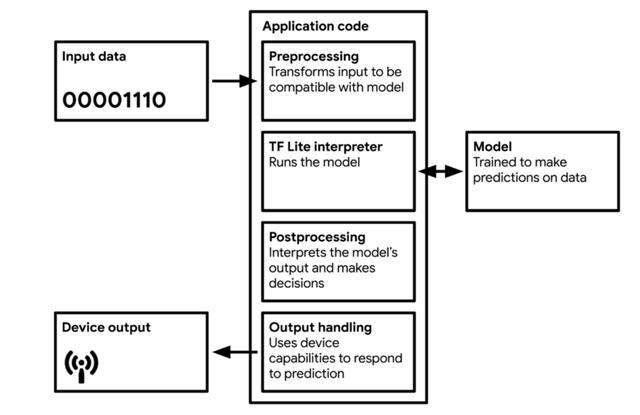
图 8 TinyML 应用的工作流图 。 来源:Pete Warden 和 Daniel Situnayake 编写的《 TinyML 》一书
大多数 TinyML 技术 , 针对的是处理微控制器所导致的复杂性 。 TF Lite 和 TF Lite Micro 非常小 , 是因为其中删除了所有非必要的功能 。 不幸的是 , 它们同时也删除了一些有用的功能 , 例如调试和可视化 。 这意味着 , 如果在部署过程中出现错误 , 可能很难判别原因 。
另外 , 尽管模型必须存储在设备本地 , 但模型也必须要支持执行推理 。 这意味着微控制器必须具有足够大的内存去运行(1)操作系统和软件库;(2)神经网络解释器 , 例如 TF Lite);(3)存储的神经网络权重和架构;(4)推理过程中的中间结果 。 因此 , TinyML 方向的研究论文在给出内存使用量、乘法累加单元(multiply-accumulate units , MAC)数量 , 准确率等指标的同时 , 通常还需给出量化算法的峰值内存使用情况 。
为什么不在设备上训练?在设备上进行训练会引入额外的复杂性 。 由于数值精度的降低 , 要确保网络训练所需的足够准确率是极为困难的 。 在标准台式计算机的精度下 , 自动微分方法是大体准确的 。 计算导数的精度可达令人难以置信的 10^{-16} , 但是在 8 位数值上做自动微分 , 将给出精度较差的结果 。 在反向传播过程中 , 会组合使用求导并最终用于更新神经参数 。 在如此低的数值精度下 , 模型的准确率可能很差 。
尽管存在上述问题 , 一些神经网络还是使用了 16 位和 8 位浮点数做了训练 。
第一篇研究降低深度学习中的数值精度的论文 , 是 Suyog Gupta 及其同事在 2015 年发表的“具有有限数值精度的深度学习”( Deep Learning with Limited Numerical Precision ) 。 该论文给出的结果非常有意思 , 即可在几乎不降低准确率的情况下 , 将 32 位浮点表示形式降至 16 位固定点表示 。 但该结果仅适用于使用随机舍入( stochastic rounding )的情况 , 因为其在均值上产生无偏结果 。
在 Naigang Wang 及其同事 2018 年发表的论文“使用 8 位浮点数训练深度神经网络”( Training Deep Neural Networks with 8-bit Floating Point Numbers )中 , 使用了 8 位浮点数训练神经网络 。 在训练中使用 8 位数值 , 相比在推理中要明显难以实现 , 因为需要在反向传播期间保持梯度计算的保真度(fidelity) , 使得在做自动微分时能够达到机器的精度 。
计算效率如何?可以通过定制模型 , 提高模型的计算效率 。 一个很好的例子就是 MobileNet V1 和 MobileNet V2 , 它们是已在移动设备上得到广泛部署的模型架构 , 本质上是一种通过重组(recast)实现更高计算效率卷积运算的卷积神经网络 。 这种更有效的卷积形式 , 称为深度可分离卷积结构(depthwise separable convolution) 。 针对架构延迟的优化 , 还可以使用基于硬件的概要(hardware-based profiling)和神经架构搜索(neural architecture search)等技术 , 对此本文将不做详述 。
新一轮人工智能革命在资源受限的设备上运行机器学习模型 , 为许多新的应用打开了大门 。 使标准的机器学习更加节能的技术进步 , 将有助于消除数据科学对环境影响的一些担忧 。 此外 , TinyML 支持嵌入式设备搭载基于数据驱动算法的全新智能 , 进而应用在了从预防性维护到检测森林中的鸟叫声等多种场景中 。
尽管继续扩大模型的规模是一些机器学习从业者的坚定方向 , 但面向内存、计算和能源效率更高的机器学习算法发展也是一个新的趋势 。 TinyML 仍处于起步阶段 , 在该方向上的专家很少 。 本文参考文献中列出了一些TinyML 领域中的重要论文 , 建议有兴趣的读者去阅读 。 该方向正在快速增长 , 并将在未来几年内 , 成为人工智能在工业领域的重要新应用 。 请保持关注 。
作者简介Matthew Stewart , 哈佛大学环境和数据科学博士研究生 , Critical Future 公司机器学习顾问 , 个人博客地址:
参考文献
[1] Hinton, Geoffrey--tt-darkmode-color: #9B9B9B;">[2] D. Bankman, L. Yang, B. Moons, M. Verhelst and B. Murmann, “ An always-on 3.8μJ/86% CIFAR-10 mixed-signal binary CNN processor with all memory on chip in 28nm CMOS ,” 2018 IEEE International Solid-State Circuits Conference — (ISSCC), San Francisco, CA, 2018, pp. 222–224, doi: 10.1109/ISSCC.2018.8310264.
[3] Warden, P. (2018). Why the Future of Machine Learning is Tiny . Pete Warden’s Blog.
[4] Ward-Foxton, S. (2020). AI Sound Recognition on a Cortex-M0: Data is King . EE Times.
[5] Levy, M. (2020). Deep Learning on MCUs is the Future of Edge Computing . EE Times.
- 推新标准建新生态,下载超198亿次金山发力海内外
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 先别|用了周冬雨的照片,我会成为下一个被告?自媒体创作者先别自乱阵脚
- 丹丹|福佑卡车创始人兼CEO单丹丹:数字领航 驶向下一个十年
- 看过明年的iPhone之后,现在下手的都哭了
- 砍单|iPhone12之后,拼多多又将iPhone12Pro拉下水
- 巨头|“社区薇娅”都不够用了 一线互联网巨头全员下场卖菜
- 余额|中兴通讯:现有资金余额仅能确保公司当前经营规模下现金流安全
- 销售|Shopify宣布创下51亿美元的假日购物季销售纪录