「轻阅读」基于 Flink SQL CDC的实时数据同步方案( 三 )
■ 基于查询的维表关联
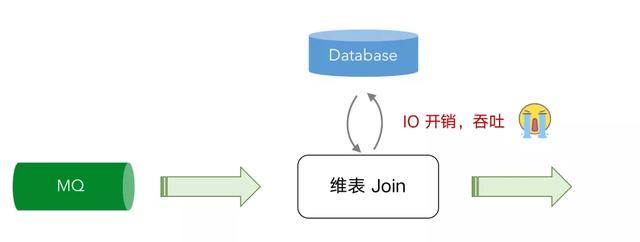 文章插图
文章插图目前维表查询的方式主要是通过 Join 的方式 , 数据从消息队列进来后通过向数据库发起 IO 的请求 , 由数据库把结果返回后合并再输出到下游 , 但是这个过程无可避免的产生了 IO 和网络通信的消耗 , 导致吞吐量无法进一步提升 , 就算使用一些缓存机制 , 但是因为缓存更新不及时可能会导致精确性也没那么高 。
■ 基于 CDC 的维表关联
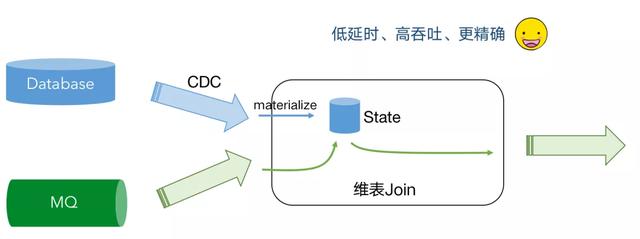 文章插图
文章插图我们可以通过 CDC 把维表的数据导入到维表 Join 的状态里面 , 在这个 State 里面因为它是一个分布式的 State, 里面保存了 Database 里面实时的数据库维表镜像 , 当消息队列数据过来时候无需再次查询远程的数据库了 , 直接查询本地磁盘的 State, 避免了 IO 操作 , 实现了低延迟、高吞吐 , 更精准 。
Tips:目前此功能在 1.12 版本的规划中 , 具体进度请关注 FLIP-132。
未来规划
- FLIP-132 :Temporal Table DDL(基于 CDC 的维表关联)
- Upsert 数据输出到 Kafka
- 更多的 CDC formats 支持(debezium-avro, OGG, Maxwell)
- 批模式支持处理 CDC 数据
- flink-cdc-connectors 支持更多数据库
本文通过对比传统的数据同步方案与 Flink SQL CDC 方案分享了 Flink CDC 的优势 , 与此同时介绍了 CDC 分为日志型和查询型各自的实现原理 。 后续案例也演示了关于 Debezium 订阅 MySQL Binlog 的场景介绍 , 以及如何通过 flink-cdc-connectors 实现技术整合替代订阅组件 。 除此之外 , 还详细讲解了 Flink CDC 在数据同步、物化视图、多机房备份等的场景 , 并重点讲解了社区未来规划的基于 CDC 维表关联对比传统维表关联的优势以及 CDC 组件工作 。
希望通过这次分享 , 大家对 Flink SQL CDC 能有全新的认识和了解 , 在未来实际生产开发中 , 期望 Flink CDC 能带来更多开发的便捷和更丰富的使用场景 。
Q--tt-darkmode-color: #595959;">1、GROUP BY 结果如何写到 Kafka ?
因为 group by 的结果是一个更新的结果 , 目前无法写入 append only 的消息队列中里面去 。 更新的结果写入 Kafka 中将在 1.12 版本中原生地支持 。 在 1.11 版本中 , 可以通过 flink-cdc-connectors 项目提供的 changelog-json format 来实现该功能 , 具体见文档 。
文档链接:
/wiki/Changelog-JSON-Format
2、CDC 是否需要保证顺序化消费?
是的 , 数据同步到 kafka, 首先需要 kafka 在分区中保证有序 , 同一个 key 的变更数据需要打入到同一个 kafka 的分区里面 。 这样 flink 读取的时候才能保证顺序 。
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 死亡|这届年轻人不讲武德,旧消费主义社会性死亡
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 轻松|使用 GIMP 轻松地设置图片透明度
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 确认|三星确认正在开发“轻薄轻巧”的可折叠手机
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- mini|电影、mini 与「当日完稿」工作流
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- 产品|墨案Inkpad X超级阅读器:10英寸大屏,同品类号称无敌