「轻阅读」基于 Flink SQL CDC的实时数据同步方案
整理:陈政羽(Flink 社区志愿者)
Flink 1.11 引入了 Flink SQL CDC , CDC 能给我们数据和业务间能带来什么变化?本文由 Apache Flink PMC , 阿里巴巴技术专家伍翀 (云邪)分享 , 内容将从传统的数据同步方案 , 基于 Flink CDC 同步的解决方案以及更多的应用场景和 CDC 未来开发规划等方面进行介绍和演示 。
- 传统数据同步方案
- 基于 Flink SQL CDC 的数据同步方案(Demo)
- Flink SQL CDC 的更多应用场景
- Flink SQL CDC 的未来规划
传统的数据同步方案与
Flink SQL CDC 解决方案
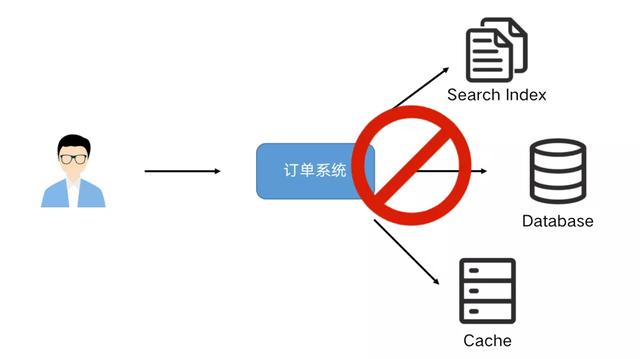
业务系统经常会遇到需要更新数据到多个存储的需求 。 例如:一个订单系统刚刚开始只需要写入数据库即可完成业务使用 。 某天 BI 团队期望对数据库做全文索引 , 于是我们同时要写多一份数据到 ES 中 , 改造后一段时间 , 又有需求需要写入到 Redis 缓存中 。
 文章插图
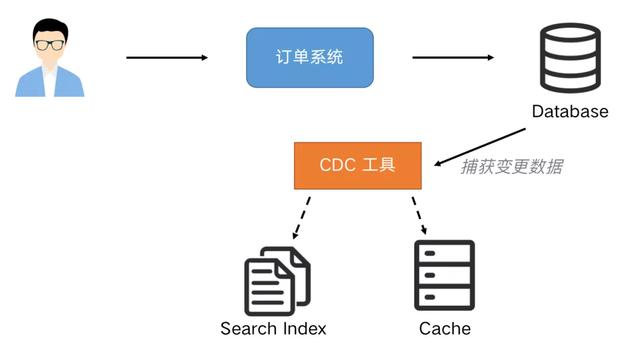
文章插图很明显这种模式是不可持续发展的 , 这种双写到各个数据存储系统中可能导致不可维护和扩展 , 数据一致性问题等 , 需要引入分布式事务 , 成本和复杂度也随之增加 。 我们可以通过 CDC(Change Data Capture)工具进行解除耦合 , 同步到下游需要同步的存储系统 。 通过这种方式提高系统的稳健性 , 也方便后续的维护 。
 文章插图
文章插图Flink SQL CDC 数据同步与原理解析 CDC 全称是 Change Data Capture, 它是一个比较广义的概念 , 只要能捕获变更的数据 , 我们都可以称为 CDC。 业界主要有基于查询的 CDC 和基于日志的 CDC, 可以从下面表格对比他们功能和差异点 。
基于查询的 CDC基于日志的 CDC概念每次捕获变更发起 Select 查询进行全表扫描 , 过滤出查询之间变更的数据读取数据存储系统的 log, 例如 MySQL 里面的 binlog持续监控开源产品Sqoop, Kafka JDBC SourceCanal, Maxwell, Debezium执行模式BatchStreaming捕获所有数据的变化??低延迟 , 不增加数据库负载??不侵入业务(LastUpdated字段)? ?捕获删除事件和旧记录的状态??捕获旧记录的状态??
【「轻阅读」基于 Flink SQL CDC的实时数据同步方案】经过以上对比 , 我们可以发现基于日志 CDC 有以下这几种优势:
- 能够捕获所有数据的变化 , 捕获完整的变更记录 。 在异地容灾 , 数据备份等场景中得到广泛应用 , 如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失
- 每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤 , 拥有更高的效率和性能 , 具有低延迟 , 不增加数据库负载的优势
- 无需入侵业务 , 业务解耦 , 无需更改业务模型
- 捕获删除事件和捕获旧记录的状态 , 在查询 CDC 中 , 周期的查询无法感知中间数据是否删除
 文章插图
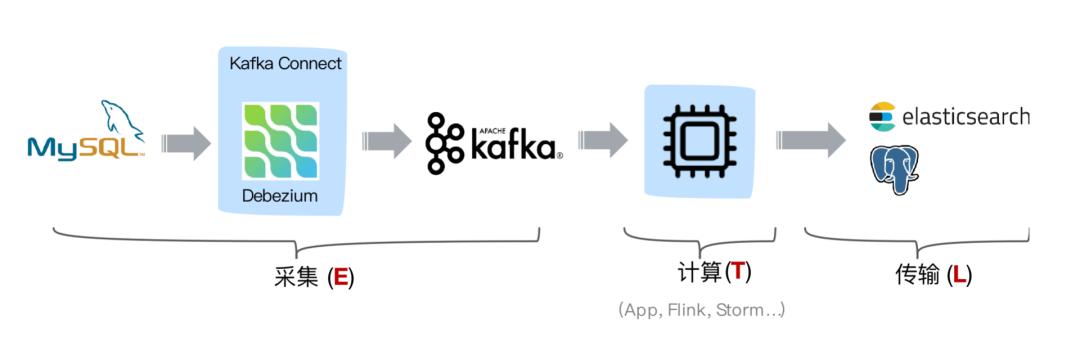
文章插图基于日志的 CDC 方案介绍
从 ETL 的角度进行分析 , 一般采集的都是业务库数据 , 这里使用 MySQL 作为需要采集的数据库 , 通过 Debezium 把 MySQL Binlog 进行采集后发送至 Kafka 消息队列 , 然后对接一些实时计算引擎或者 APP 进行消费后把数据传输入 OLAP 系统或者其他存储介质 。
Flink 希望打通更多数据源 , 发挥完整的计算能力 。 我们生产中主要来源于业务日志和数据库日志 , Flink 在业务日志的支持上已经非常完善 , 但是在数据库日志支持方面在 Flink 1.11 前还属于一片空白 , 这就是为什么要集成 CDC 的原因之一 。
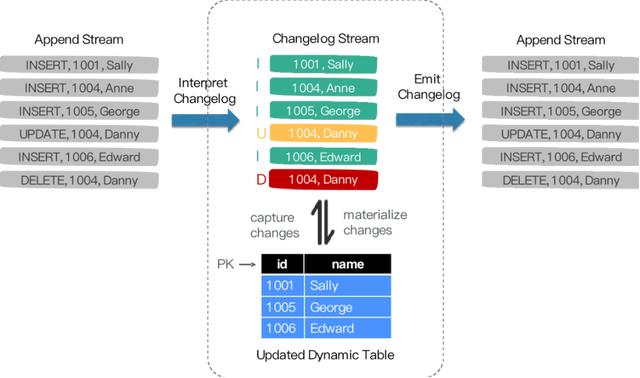
Flink SQL 内部支持了完整的 changelog 机制 , 所以 Flink 对接 CDC 数据只需要把CDC 数据转换成 Flink 认识的数据 , 所以在 Flink 1.11 里面重构了 TableSource 接口 , 以便更好支持和集成 CDC 。
 文章插图
文章插图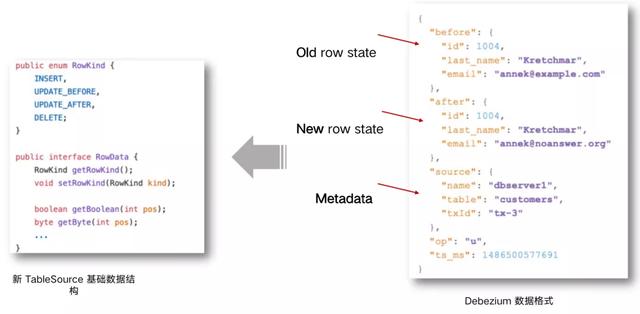 文章插图
文章插图重构后的 TableSource 输出的都是 RowData 数据结构 , 代表了一行的数据 。 在RowData 上面会有一个元数据的信息 , 我们称为 RowKind。 RowKind 里面包括了插入、更新前、更新后、删除 , 这样和数据库里面的 binlog 概念十分类似 。 通过 Debezium 采集的 JSON 格式 , 包含了旧数据和新数据行以及原数据信息 , op 的 u表示是 update 更新操作标识符 , ts_ms 表示同步的时间戳 。 因此 , 对接 Debezium JSON 的数据 , 其实就是将这种原始的 JSON 数据转换成 Flink 认识的 RowData 。
- 作家|逾万名作家联名反对亚马逊有声书轻松退换政策
- 死亡|这届年轻人不讲武德,旧消费主义社会性死亡
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 轻松|使用 GIMP 轻松地设置图片透明度
- 试试|手机内存不够用,咋办?试试关闭微信这两步操作,轻松腾出几个G
- 确认|三星确认正在开发“轻薄轻巧”的可折叠手机
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- mini|电影、mini 与「当日完稿」工作流
- 字化转型|疫情重构经济,传统企业「数字化」的通关密码是什么?
- 产品|墨案Inkpad X超级阅读器:10英寸大屏,同品类号称无敌