AlphaGo原来是这样运行的,一文详解多智能体强化学习( 四 )
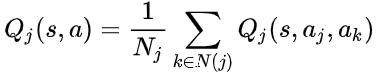 文章插图
文章插图
然后 , 将平均场理论的思想结合到上式中 。 考虑离散的动作空间 , 单个智能体的动作采用 one-hot 编码的方式 , 即 aj=[h(aj_1), ... h(aj_d)] , 其中 h(aj_i)=1 if aj=aj_i ?: 0;其他相邻智能体的动作可以表示为平均动作 \ bar和一个波动δ的形式: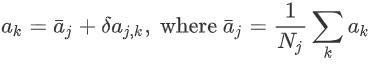 文章插图
文章插图
利用泰勒二阶展开 , 得到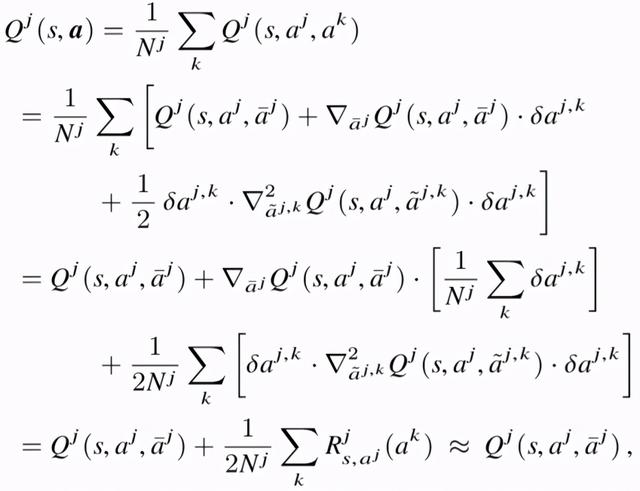 文章插图
文章插图
该式子即是将当前智能体 j 与其他相邻智能体 k 的相互作用 , 简化为当前智能体 j 和虚拟智能体 \ bar的相互作用 , 是平均场思想在数学形式上的体现 。 此时 , 在学习过程中 , 迭代更新的对象为平均场下的 Q(s,aj,\bar)值(即 MF-Q) , 有: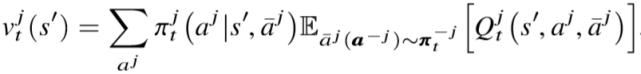 文章插图
文章插图
在更新中使用 v 而不是使用 max Q 的原因在于:对 Q 取 max , 需要相邻智能体策略 \ bar的合作 , 而对于智能体 j 来说是无法直接干涉其他智能体的决策情况;另一方面 , 贪心的选择依旧会导致学习过程受到环境不稳定性的影响 。
对应地 , 智能体 j 的策略也会基于 Q 值迭代更新 , 使用玻尔兹曼分布有: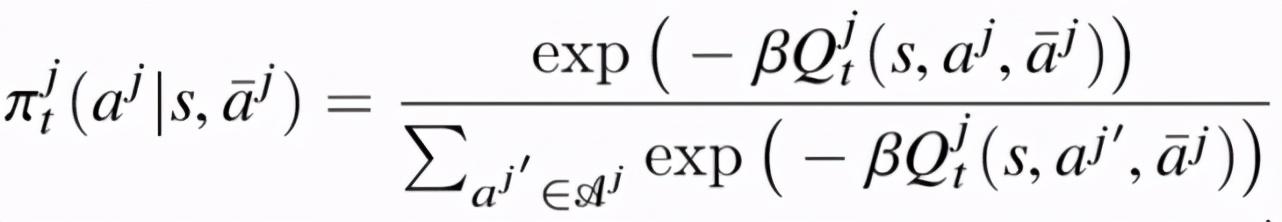 文章插图
文章插图
原文证明了通过这样的迭代更新方式 , \bar最终能够收敛到唯一平衡点的证明 , 并推出智能体 j 的策略πj 能够收敛到纳什均衡策略 。
显式的协作机制
关于显式的协作机制 , 我们将通过多智能体深度强化学习在多机器人领域的应用中会简单介绍(主要是人机之间的交互 , 考虑现存的一些约束条件 / 先验规则等) 。
2. 多智能体深度强化学习
随着深度学习的发展 , 利用神经网络的强大表达能力来搭建逼近模型(value approximation)和策略模型(常见于 policy-based 的 DRL 方法) 。 深度强化学习的方法可以分为基于值函数(value-based)和基于策略(policy-based)两种 , 在考虑多智能体问题时 , 主要的方式是在值函数的定义或者是策略的定义中引入多智能体的相关因素 , 并设计相应的网络结构作为值函数模型和策略模型 , 最终训练得到的模型能够适应(直接或者是潜在地学习到智能体相互之间的复杂关系) , 在具体任务上获得不错的效果 。
2.1 policy-based 的方法
在完全合作的 setting 下 , 多智能体整体通常需要最大化全局的期望回报 。 前面提到一种完全集中式的方式:通过一个中心模块来完成全局信息的获取和决策计算 , 能够直接地将适用于单智能体的 RL 方法拓展到多智能体系统中 。 但通常在现实情况中 , 中心化的控制器(centralized controller)并不一定可行 , 或者说不一定是比较理想的决策方式 。 而如果采用完全分布式的方式 , 每个智能体独自学习自己的值函数网络以及策略网络、不考虑其他智能体对自己的影响 , 无法很好处理环境的不稳定问题 。 利用强化学习中 actor-critic 框架的特点 , 能够在这两种极端方式中找到协调的办法 。
1. 多智能体 DDPG 方法(Multi-Agent Deep Deterministic Policy Gradient, MADDPG) 文章插图
文章插图
这种方法是在深度确定策略梯度(Deep Deterministic Policy Gradient , DDPG)方法的基础上、对其中涉及到的 actor-critic 框架进行改进 , 使用集中式训练、分布式执行的机制(centralized training and decentralized execution) , 为解决多智能体问题提供了一种比较通用的思路 。
MADDPG 为每个智能体都建立了一个中心化的 critic , 它能够获取全局信息(包括全局状态和所有智能体的动作)并给出对应的值函数 Qi(x,a1,...,an) , 这在一定程度上能够缓解多智能体系统环境不稳定的问题 。 另一方面 , 每个智能体的 actor 则只需要根据局部的观测信息作出决策 , 这能够实现对多智能体的分布式控制 。
在基于 actor-critic 框架的学习过程中 , critic 和 actor 的更新方式和 DDPG 类似 。 对于 critic , 它的优化目标为:
对于 actor , 考虑确定性策略μi(ai|oi) , 策略更新时的梯度计算可以表示为: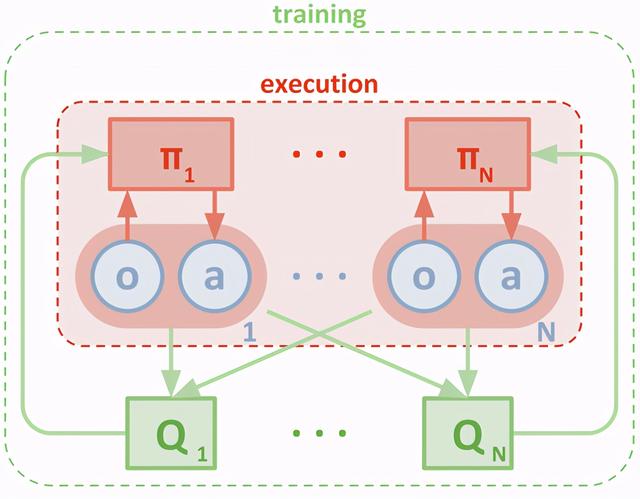 文章插图
文章插图
图 6:中心化的 Q 值学习(绿色)和分布式的策略执行(褐色) 。 Q 值获取所有智能体的观测信息 o 和动作 a , 策略π根据个体的观测信息来输出个体动作 。 图源:[9]
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 无国界|嘴上说着支持华为,却为苹果贡献了2000亿!还真是科技无国界啊?