AlphaGo原来是这样运行的,一文详解多智能体强化学习( 二 )
相比于单智能体系统 , 强化学习应用在多智能体系统中会遇到哪些问题和挑战?
环境的不稳定性:智能体在做决策的同时 , 其他智能体也在采取动作;环境状态的变化与所有智能体的联合动作相关;
智能体获取信息的局限性:不一定能够获得全局的信息 , 智能体仅能获取局部的观测信息 , 但无法得知其他智能体的观测信息、动作和奖励等信息;
个体的目标一致性:各智能体的目标可能是最优的全局回报;也可能是各自局部回报的最优;
可拓展性:在大规模的多智能体系统中 , 就会涉及到高维度的状态空间和动作空间 , 对于模型表达能力和真实场景中的硬件算力有一定的要求 。
1.2 多智能体问题的求解——多智能体强化学习算法介绍
对于多智能体强化学习问题 , 一种直接的解决思路:将单智能体强化学习方法直接套用在多智能体系统中 , 即每个智能体把其他智能体都当做环境中的因素 , 仍然按照单智能体学习的方式、通过与环境的交互来更新策略;这是 independent Q-learning 方法的思想 。 这种学习方式固然简单也很容易实现 , 但忽略了其他智能体也具备决策的能力、所有个体的动作共同影响环境的状态 , 使得它很难稳定地学习并达到良好的效果 。
在一般情况下 , 智能体之间可能存在的是竞争关系(非合作关系)、半竞争半合作关系(混合式)或者是完全合作关系 , 在这些关系模式下 , 个体需要考虑其他智能体决策行为的影响也是不一样的 。 参考综述[3] , 接下来的部分将根据智能体之间的关系 , 按照完全竞争式、半竞争半合作、完全合作式来阐述多智能体问题的建模以及求解方法 。
1.2.1 智能体之间是完全竞争关系
minimax Q-learning 算法用于两个智能体之间是完全竞争关系的零和随机博弈 。 首先是最优值函数的定义:对于智能体 i , 它需要考虑在其他智能体(i-)采取的动作(a-)令自己(i)回报最差(min)的情况下 , 能够获得的最大(max)期望回报 。 该回报可以表示为: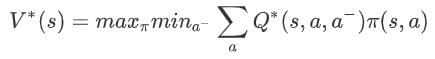 文章插图
文章插图
在式子中 , V 和 Q 省略了智能体 i 的下标 , 是因为在零和博弈中设定了 Q1=-Q2 , 所以上式对于另一个智能体来说是对称等价的 。 这个值函数表明 , 当前智能体在考虑了对手策略的情况下使用贪心选择 。 这种方式使得智能体容易收敛到纳什均衡策略 。
在学习过程中 , 基于强化学习中的 Q-learning 方法 , minimax Q-learning 利用上述 minimax 思想定义的值函数、通过迭代更新 Q 值;动作的选择 , 则是通过线性规划来求解当前阶段状态 s 对应的纳什均衡策略 。 文章插图
文章插图
图 3:minimax-Q learning 算法流程 。 图源[4]
minimax Q 方法是竞争式博弈中很经典的一种思想 , 基于该种思想衍生出很多其他方法 , 包括 Friend-or-Foe Q-learning、correlated Q-learning , 以及接下来将要提到的 Nash Q-learning 。
1.2.2 智能体之间是半合作半竞争(混合)关系
双人零和博弈的更一般形式为多人一般和博弈(general-sum game) , 此时 minimax Q-learning 方法可扩展为 Nash Q-learning 方法 。 当每个智能体采用普通的 Q 学习方法 , 并且都采取贪心的方式、即最大化各自的 Q 值时 , 这样的方法容易收敛到纳什均衡策略 。 Nash Q-learning 方法可用于处理以纳什均衡为解的多智能体学习问题 。 它的目标是通过寻找每一个状态的纳什均衡点 , 从而在学习过程中基于纳什均衡策略来更新 Q 值 。
具体地 , 对于一个智能体 i 来说 , 它的 Nash Q 值定义为:
此时 , 假设了所有智能体从下一时刻开始都采取纳什均衡策略 , 纳什策略可以通过二次规划(仅考虑离散的动作空间 , π是各动作的概率分布)来求解 。
在 Q 值的迭代更新过程中 , 使用 Nash Q 值来更新:
可以看到 , 对于单个智能体 i , 在使用 Nash Q 值进行更新时 , 它除了需要知道全局状态 s 和其他智能体的动作 a 以外 , 还需要知道其他所有智能体在下一状态对应的纳什均衡策略π 。 进一步地 , 当前智能体就需要知道其他智能体的 Q(s')值 , 这通常是根据观察到的其他智能体的奖励和动作来猜想和计算 。 所以 , Nash Q-learning 方法对智能体能够获取的其他智能体的信息(包括动作、奖励等)具有较强的假设 , 在复杂的真实问题中一般不满足这样严格的条件 , 方法的适用范围受限 。 文章插图
文章插图
- 对手|一加9Pro全面曝光,或是小米11最大对手
- 行业|现在行业内客服托管费用是怎么算的
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 无国界|嘴上说着支持华为,却为苹果贡献了2000亿!还真是科技无国界啊?