你不得不关注的Elasticsearch Top X关键指标( 二 )
- 洪水警戒水位线
cluster.routing.allocation.disk.watermark.flood_stage 默认为磁盘容量的95% 。 Elasticsearch对每个索引强制执行只读索引块(index.blocks.read_only_allow_delete) 。 这是防止节点耗尽磁盘空间的最后手段 。 只读模式待磁盘空间充裕后 , 需要人工解除 。因此 , 监视集群中的可用存储空间至关重要 。
3、已删除的文档Elasticsearch中的文档无法修改 , 并且是不可变的(immutable) 。 Elasticsearch 执行的删除或更新文档操作会先将文档标记为已删除(逻辑删除) , 不会立即将其从Elasticsearch中物理删除 。 当你继续索引更多数据时 , 这些文档将在后台被清理 。 已逻辑删除的文档在搜索操作期间不可见 , 但是它们继续占用磁盘空间 。
- 如果磁盘空间成为瓶颈 , 则可以强制执行段合并操作 。 段合并会实现小段合并为大段并清理已删除的文档 。
POST my_index/_forcemerge- 如果通过 reindex 将文档重新索引为新索引 , 则可以执行删除旧索引操作(delete index) , 删除索引的方式会直接物理删除掉文档 。
- 如果你的索引会定期更新 , 则待删除的文档数量会很多 。
4、主节点指标在生产环境中 , 建议你在Elasticsearch集群中配置专用的主节点 。
- 主节点通过监视集群管理活动(例如:跟踪集群中的所有节点、索引和分片)来提高集群的稳定性 。
- 主节点还监视集群的运行状况 , 以确保数据节点不会过载 , 并使集群具有容错能力 。
你可以通过查看主节点的CPU / 内存利用率和 JVM 内存使用百分比来确定主节点实例的配置 。
以下是:cerebro 监控 截图 。
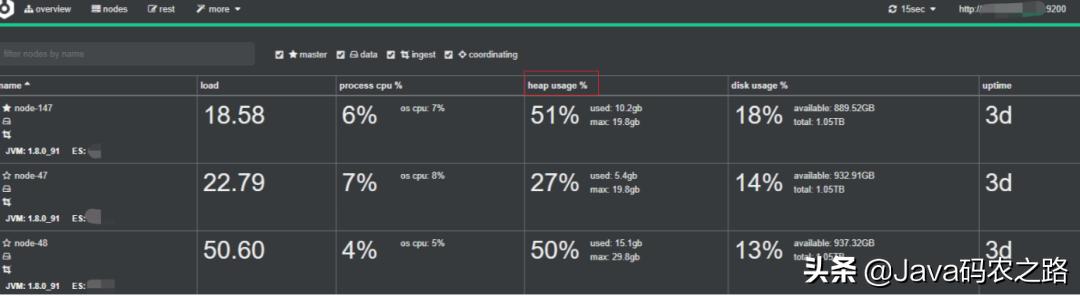 文章插图
文章插图一般来说 , 由于主节点专注于集群状态 , 因此通常需要具有较低CPU /内存资源的计算机 。
5、数据节点指标数据节点托管 Elasticsearch 集群中包含索引文档的分片 。 数据节点还执行搜索和聚合有关的所有数据操作 , 并处理客户端请求 。
与主节点相比 , 数据节点需要具有较高CPU / 内存资源的服务器 。
如果你的集群没有专用的主节点 , 则其中一个数据节点将开始充当主节点 。 这会在集群中造成CPU和JVM使用的不平衡 。
文档增、删、改、查操作和搜索操作占用大量CPU和IO , 因此监视数据节点利用率指标很重要 。
从CPU /内存的角度来看 , 您应确保数据节点平衡且不会过载 。
6、数据写入性能指标如果您试图将大量文档写入 Elasticsearch 中 , 则可以监视数据写入延迟和数据索引化速率指标 , 以验证索引吞吐量是否满足企业的需求 。
有几种方法可以提高数据写入速度 。 可概括为如下四项措施:
6.1 bulk 批量操作或者多线程写入利用 Elasticsearch 提供的批量API(bulk)来同时索引一批文档 。 还可以使用多线程写入 Elasticsearch 以最大化利用所有集群资源 。
请注意 , 文档大小和集群配置可能会影响数据写入速度 。 为了找到集群的最佳吞吐量 , 你需要运行性能测试并尝试使用不同的批处理大小和并发线程值大小 。
6.2 合理调整刷新频率Elasticsearch refresh 刷新操作是使文档可搜索的过程 。
默认情况下 , 每秒刷新一次 。 如果主要目标是调整摄取速度的索引 , 则可以将 Elasticsearch 的默认刷新间隔从1秒更改为30秒 。 30秒后 , 这将使文档可见以供搜索 , 从而优化索引速度 。
更新指定索引的刷新频率 , 实现如下:
PUT my_index/_settings{"index": {"refresh_interval": "30s"}}在写入繁重的业务场景或索引速度比搜索性能更关键的业务场景下 , 这可能是一个很好的实践 。6.3 写入前后动态调整副本大小副本能提升集群的高可用并且作为主分片数据的备份能一定程度防止数据丢失 , 但带来了相应的成本 。
在初始数据加载期间 , 你可以禁用副本以实现较高的索引写入速度 。
PUT my_index/_settings{"index": {"number_of_replicas": 0}}为保证集群高可用 , 一旦完成初始加载 , 就可以重新启用副本 。6.4 合理的数据建模不要索引业务层面不需搜索的字段 。 可通过不索引冗余字段来节省存储空间(举例:设置 index:false) 。
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 国产手机|国产手机新品频发,果粉们你们还能忍得住吗?
- 减重|快看!奇瑞蚂蚁都减重了 那你还焦虑什么?
- 化妆产品|直播带货年入百万,这8个行业告诉你:是真的
- 关华为P50Pro|华为P50Pro概念图:半圆形6摄,看完iPhone12劝你暂时别买
- 屏幕|苹果iPhone12屏幕不仅发白,还绿的你发慌,用户:环保绿
- 主题活动|首届“上海在线生活节”启动,8大电商平台优惠活动承包你的12月
- 月入|一上网,感觉网上每个人都是月入过万,到底是错觉还是你out了?
- 社区团购|你在买菜APP上薅的每一根羊毛,都将加倍奉还!