你不得不关注的Elasticsearch Top X关键指标
0、题记
- 在写繁重的业务场景下 , 你是否遇到过 Elasticsearch 集群的性能问题?
- 你是否遇到过 Elasticsearch 数据索引化速度限制问题?
- 你是否遇到过搜索花费时间太长而无法执行的延迟问题?
- 你是否遭遇过 Elasticsearch 集群故障排查的挑战?
- 你是否努力尝试在零停机情况下提高 Elasticsearch 集群的稳定性?
- 你是否想过从监控的角度去看Elasticsearch 关键指标?
我将介绍一些有关故障排除和解决 Elasticsearch 性能问题的经验 。
到本文结尾 , 你应该对关键指标有一个很好的了解 , 以便在你遇到Elasticsearch集群的性能或操作问题时进行监视 。
那么 , 要监视 Elasticsearch Top X 指标是什么呢?本文揭晓答案 。
1、集群配置Elasticsearch 是一个分布式搜索引擎 , 可实现快速的数据索引化并具备良好的搜索性能 。
开箱即用的 Elasticsearch 配置可以满足N多业务场景 。 但是 , 如果你想获得最佳性能 , 那么了解索引以及搜索要求并确保集群配置符合Elasticsearch最佳实践至关重要 。
Elasticsearch是按业务规模构建的 , 具有最佳配置可确保更好的集群性能 。 Elasticsearch 集群可拆解为各种可度量的元素 , 可以将节点视为运行 Elasticsearch 进程的机器 。 索引本身可以被视为一个完整的搜索引擎 , 由一个或多个分片组成 。 可以将一个分片可视化为 Apache Lucene 的单个实例 , 该实例保存用于索引和搜索的文档 , 并且这些文档在各个分片之间均匀分布 。
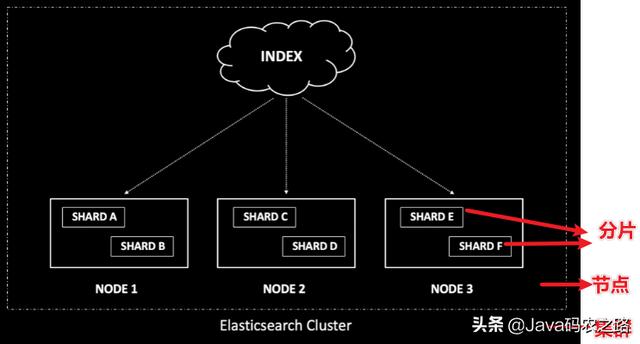 文章插图
文章插图图为:一个三节点集群 , 其索引分为六个分片
分片可以提高摄取(ingest)和搜索性能 , 但是分片过多也会降低速度 。 适当的分片策略对于集群至关重要 。 建议单个分片大小设置在 30-50 GB 之间 。
分片数高于节点数可便于扩展集群 。 但是分片的过度分配可能会减慢搜索操作 , 是因为搜索首先在 query 阶段请求需要命中索引中的每个分片 , 然后执行 fetch 阶段获取并汇聚结果 。
如果你的分片仅容纳了 5 GB数据 , 则可以认为未充分利用 。
咱们之前 N 多文章都提过 , 一个简单的查看集群整体健康状态的 API 如下:
GET _cluster/health返回结果如下:{"cluster_name" : "my-application","status" : "yellow","timed_out" : false,"number_of_nodes" : 1,"number_of_data_nodes" : 1,"active_primary_shards" : 11,"active_shards" : 11,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 5,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 68.75}开发人员经常问到的一个问题是:“集群应该配置的最佳分片数是多少?以使得整个集群性能最优 。 ”我要说的是 , 这个问题没有一个千篇一律的答案 。 这取决于你的业务要求和你要满足的SLA(网站服务可用性的保证) 。如下多项统计信息将帮助你做出正确的容量规划决策 , 包含但不限于:
- 需要每秒索引的文档数
- 单文档大小
- 每秒查询数
- 数据集的增长模式
强烈建议你了解您的数据和索引、搜索要求 , 以创建一个平衡且高效的集群 。
2、总可用存储空间大小如果你的 Elasticsearch 集群节点的磁盘空间不足 , 则会影响集群性能 。
一旦可用存储空间低于特定阈值限制 , 它将开始阻止写入操作 , 进而影响数据进入集群 。
不少同学可能会遇到过如下的错误:
ElasticsearchStatusException[Elasticsearch exception [type=cluster_block_exception, reason=blocked by: [FORBIDDEN/12/index read-only / allow这就是磁盘快满了做的保护机制提示 。再次强调一下 , 磁盘的三个默认警戒水位线 。
- 低警戒水位线
cluster.routing.allocation.disk.watermark.low 默认为磁盘容量的85% 。 Elasticsearch不会将新的分片分配给磁盘使用率超过85%的节点 。 它也可以设置为绝对字节值(如500mb) , 以防止 Elasticsearch 在小于指定的可用空间量时分配分片 。 此设置不会影响新创建的索引的主分片 , 特别是之前从未分配过的分片 。- 高警戒水位线
cluster.routing.allocation.disk.watermark.high 默认为磁盘容量的90% 。 Elasticsearch 将尝试对磁盘使用率超过90%的节点重新分配分片(将当前节点的数据转移到其他节点) 。 它也可以设置为绝对字节值 , 以便在节点小于指定的可用空间量时将其从节点重新分配 。 此设置会影响所有分片的分配 , 无论先前是否分配 。
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 国产手机|国产手机新品频发,果粉们你们还能忍得住吗?
- 减重|快看!奇瑞蚂蚁都减重了 那你还焦虑什么?
- 化妆产品|直播带货年入百万,这8个行业告诉你:是真的
- 关华为P50Pro|华为P50Pro概念图:半圆形6摄,看完iPhone12劝你暂时别买
- 屏幕|苹果iPhone12屏幕不仅发白,还绿的你发慌,用户:环保绿
- 主题活动|首届“上海在线生活节”启动,8大电商平台优惠活动承包你的12月
- 月入|一上网,感觉网上每个人都是月入过万,到底是错觉还是你out了?
- 社区团购|你在买菜APP上薅的每一根羊毛,都将加倍奉还!